Классификация является одним из фундаментальных процессов в науке. Прежде чем мы сможем понять определенный круг явлений и разработать принципы, их объясняющие, часто необходимо их предварительно упорядочить. Таким образом классификацию можно считать интеллектуальной деятельностью высокого уровня, которая необходима нам для понимания природы. Классификация – это упорядочение объектов по схожести. А само понятие схожести является неоднозначным. Принципы классификации также могут быть различными. Поэтому часто процедуры, используемые в кластерном анализе для формирования классов, основываются на фундаментальных процессах классификации, присущих людям и, возможно, другим живым существам (Классификация и кластер, 1980). Достаточно часто в психологии возникает необходимость проведения классификации множества объектов по множеству переменных. Для проведения такой многомерной классификации используются методы кластерного анализа. Группы близких по какому-либо критерию объектов обычно называются кластерами. Кластеризацию можно считать процедурой, которая, начиная работать с тем или иным типом данных, преобразует их в данные о кластерах. Многие методы кластерного анализа отличаются от других методов многомерного анализа отсутствием обучающих выборок, т.е. априорной информации о распределении соответствующих переменных генеральной совокупности. Методов кластерного анализа достаточно много, и далее будет описана их классификация.
Наибольшее распространение в психологии получили иерархические агломеративные методы и итерационные методы группировки. При использовании методов кластерного анализа достаточно сложно дать однозначные рекомендации по предпочтению применения тех или иных методов. Необходимо понимать, что получаемые результаты классификации не являются единственными. Предпочтительность выбранного метода и полученных результатов следует обосновать.
Кластерный анализ (КА) строит систему классификации исследуемых объектов и переменных в виде дерева (дендрограммы) или осуществляет разбиение объектов на заданное число удаленных друг от друга классов.
Методы кластерного анализа можно расклассифицировать на:
- внутренние (признаки классификации равнозначны);
- внешние (существует один главный признак, остальные определяют его).
Внутренние методы в свою очередь можно разделить на:
- иерархические (процедура классификация имеет древовидную структуру);
- неиерархические.
Далее, иерархические подразделяются на:
- агломеративные (объединяющие);
- дивизивные (разъединяющие).
Необходимость в использовании методов кластерного анализа возникает в том случае, когда задано множество характеристик, по которым тестируется множество испытуемых; задача состоит в выделении классов (групп) испытуемых, близких по всему множеству характеристик (профилю). На первом этапе матрица смешения (оценки людей по различным характеристикам) преобразуется в матрицу расстояний. Для подсчета матрицы расстояния осуществляется подбор метрики, или метода вычисления расстояния между объектами в многомерном пространстве. Если объект описывается k признаками, то он может быть представлен как точка в k-мерном пространстве. Возможность измерения расстояний между объектами в k-мерном пространстве вводится через понятие метрики.
Пусть объекты i и j принадлежат множеству M и каждый объект описывается k признаками, тогда будем говорить, что на множестве M задана метрика, если для любой пары объектов, принадлежащих множеству M, определено неотрицательное число dij , удовлетворяющее следующим условиям (аксиомам метрики):
- Аксиома тождества: dij = 0 ⇔ i≡ j.
- Аксиома симметричности: dij = dji ∀ i, j.
- Неравенство треугольника: ∀ i, j, z∈M, выполняется неравенство diz ≤ dij + dzj .
Пространство, на котором введена метрика, называется метрическим. Наиболее используемыми являются следующие метрики:
1. Метрика Евклида:
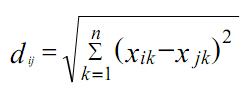
Эта метрика является наиболее используемой и отражает среднее различие между объектами.
2. Метрика нормированного Евклида. Нормализованные евклидовы расстояния более подходят для переменных, измеряемых в различных единицах или значительно различающихся по величине.
Если дисперсии по характеристикам отличаются друг от друга, то:
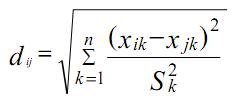
Если масштаб данных различен, например, одна переменная измерена в стэнах, а другая в баллах, то для обеспечения одинакового влияния всех характеристик на близость объектов используется следующая формула подсчета расстояния:
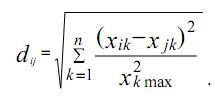
3. Метрика city-block (манхэттенская метрика, получившая свое название в честь района Манхэттен, который образуют улицы, расположенные в виде пересечения параллельных прямых под прямым углом; как правило, применяется для номинальных или качественных переменных):
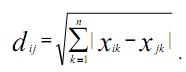
4. Метрика на основе корреляции: dij =1- |r ij |.
5. Метрика Брея-Картиса, которая также используется для номинативных и ранговых шкал, обычно данные предварительно стандартизируются:
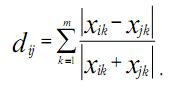
Расстояния, вычисляемые на основе коэффициента корреляции, отражают согласованность колебаний оценок, в отличие от метрики Евклида, которая определяет схожесть в среднем. Выбор метрики определяется задачей исследования и типом данных. Помимо приведенных выше методов, разработаны метрики для ранговых и дихотомических переменных и т.д. (во всех выше приведенных формулах i,j – номера столбцов; k – номер строки; dij – элемент матрицы расстояний; xik , xjk – элементы исходной матрицы; n – количество объектов).
Наиболее используемый в психологии метод кластерного анализа – это иерархический агломеративный метод, который позволяет строить дерево классификации n объектов посредством иерархического объединения их в группы, или кластеры, все более высокой общности на основе заданного критерия, например, минимума расстояния в пространстве m переменных, описывающих объекты. В результате производится разбиение некоторого множества объектов на естественное число кластеров. Первоначально каждый элемент является классом, далее на каждом шаге происходит объединение ближайших объектов, и в результате все объекты образуют один класс.
Алгоритм агломеративного метода можно представить в следующем виде: на входе имеется матрица смешения, из которой строится матрица расстояния, либо матрица расстояния, полученная непосредственно в результате исследований.
- На первом шаге в один класс объединяются те объекты, между которыми расстояние является минимальным.
- На втором шаге производится пересчет матрицы расстояний с учетом вновь образованного класса.
Далее чередование пунктов 1 и 2 производится до тех пор, пока все объекты не будут объединены в один класс. Графическое представление результатов обычно осуществляется в виде дерева иерарахической кластеризации. По оси X располагаются классифицируемые объекты (на одинаковом расстоянии друг от друга); по оси Y – расстояния, на основании которых происходит объединение объектов в кластеры. Для определения «естественного» числа кластеров применяется критерий разбиения на классы в виде отношения средних внутрикластерных расстояний к межкластерным расстояниям. Глобальный минимум соответствует «естественному» числу классов, а локальные минимумы – под- и над- структурам (нижним и верхним границам).
Методы иерархического кластерного анализа различаются также по стратегии объединения (стратегии пересчета расстояний). Однако в стандартных статистических пакетах, к сожалению, не проводится оценка разбиения на классы, поэтому данный метод используется как предварительный с целью определения числа классов (обычно по соотношению межкластерных и внутрикластерных расстояний). Далее используется либо метод k-means, либо дискриминантный анализ, либо авторы, самостоятельно используя различные методы, доказывают отделимость классов.
При объединении i-го и j-го классов в класс k, расстояние между новым классом k и любым другим классом h пересчитывается одним из приведенных ниже способов (стратегии объединения). Расстояния между другими классами сохраняются неизменными. Наиболее распространенными являются следующие стратегии объединения (название несколько не соответствует содержанию; в соответствии с выбранными формулами производится пересчет расстояния от объектов до вновь образованного класса):
1. Стратегия «ближайшего соседа» – сужает пространство (классы объединяются по ближайшей границе)
![]()
2. Стратегия «дальнего соседа» – растягивает пространство (классы объединяются по дальней границе):
![]()
3. Стратегия «группового среднего» – не изменяет пространство (объекты объединяются в соответствии с расстоянием до центра класса) :
![]()
где ni , nj , nk – число объектов соответственно в классах i, j, k.
Первые две стратегии изменяют пространство (сужают и растягивают), а последняя его не изменяет. Поэтому, если не удается получить достаточно хорошего разбиения на классы с помощью третьей стратегии, а их все же необходимо выделить, то используются первые две, причем первая стратегия объединяет классы по ближайшим границам, а вторая – по дальним.
Таким образом, обычно в стандартных ситуациях используется стратегия «группового среднего». Если исследуемая группа достаточна разнородна, т.е. испытуемые, входящие в нее, значимо отличаются друг от друга по множеству характеристик, однако среди них необходимо выделить группы более сходные по всему профилю характеристик, то используется стратегия «дальнего соседа» (сужающая пространство). Если же группа достаточно гомогенна, тогда для выделения подгрупп среди очень схожих по характеристикам испытуемых следует использовать стратегию «дальнего соседа».
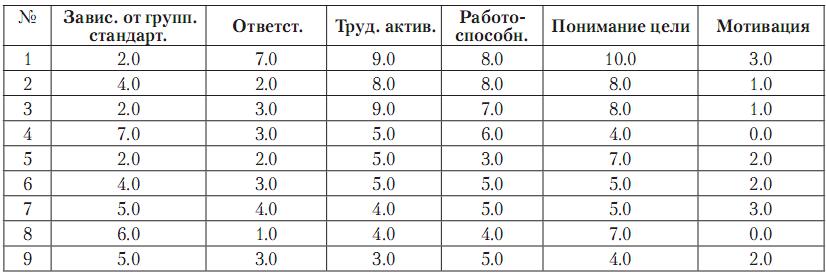
Рассмотрим фрагмент результатов исследования успешности деятельности команды – малой группы, ориентированной на решение деловой задачи и состоящей из молодых специалистов (инженеров-программистов), коллективно принимающих решение, выполняющих сложные работы в различном составе. Задача состоит в исследовании структуры данной команды и качественном описании характеристик каждой подгруппы. В качестве характеристик были рассмотрены: зависимость от групповых стандартов, ответственность, работоспособность, трудовая активность, понимание цели, организованность, мотивация. Матрица смешения для 9 сотрудников приведена ниже.
Таблица 1. Матрица смешения для коллектива из 9 человек
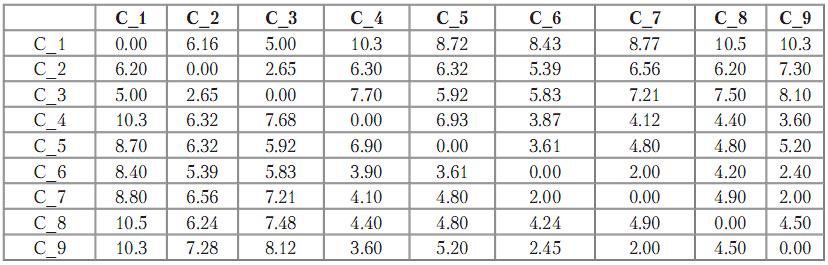
Используя метрику Евклида, получаем симметричную матрицу расстояний, которая является основой для кластерного анализа.
Таблица 2. Матрица расстояний, полученная с использованием метрики Евклида
Результат применения агломеративного иерархического метода КА к полученной матрице при использовании пакета STATISTICA – дерево классификации – представлен на рис.1.: по горизонтальной оси откладываются на одинаковом расстоянии номера объектов (членов команды), по вертикальной оси – расстояние, на котором объединяются эти объекты.
Можно заметить, что выделилось два класса: в один вошли объекты 5, 8, 9, 7, 6, 4, а в другой – 3, 2, 1. Отделимость классов оценивается сравнением внутрикластерных и межкластерных расстояний на качественном уровне.
Примененный к результатам эмпирических исследований агломеративный иерархический метод КА позволяет выделить «естественное» число классов, а также под- и над- структуры. Он будет более эффективным при использовании оценок разбиения на классы.
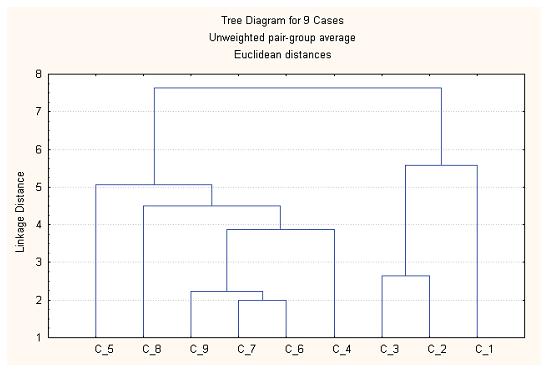
Рис. 1. Дерево классификации
Для определения «естественного» числа кластеров, на которые может быть разбита совокупность объектов, а возможно, и для выделения более «тонкой» структуры применялся следующий критерий: на каждом уровне иерархической кластеризации выполнялось разбиение множества на данное число классов. В основу примененной для этого формулы была заложена идея физической плотности или, точнее, объема пространства, занимаемого данным множеством объектов (Савченко, Рассказова, 1989). Для каждой пары кластеров оценивалась степень их внутренней связанности друг с другом. Для этого вычислялось среднее внутрикластерное расстояние для каждого кластера из заданной пары; если при этом в класс входит всего один элемент, то расстояние соответствует минимальному расстоянию до какого-либо из элементов. Если в классе более одного элемента, но все различия между ними равны 0, то в формуле отражается аналогия с объемом пространства, занимаемого одним объектом. Формула учитывает, что в данном случае в одной точке пространства находится лишь один объект с большей «удельной плотностью».
В качестве оценки связанности берется отношение среднего внутрикластерного расстояния к межкластерному:
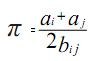
где аi и аj – средние внутрикластерные расстояния классов i и j; bij – среднее межкластерное расстояние между этими же классами.
Оценка «естественного» разбиения производится по следующей формуле:
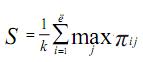
Отметим некоторые свойства такого разбиения: если все различия между объектами равны между собой, то S для такого случая равна 1; разбиения, получаемые с помощью вышеописанного алгоритма, имеют оценку не более 1. Итак, будем считать значение критерия такого разбиения, когда все объекты объединены в один кластер, равным 1.
Минимум значения функции S определяет наилучшее разбиение множества объектов на кластеры. Изображение на одном графике дерева кластеризации и значений функции S позволяет выявлять не только оптимальное разбиение, но и под- и над- структуры, которые соответствуют локальным минимумам функции S и позволяют обнаружить в множестве разные уровни объединения. Таким образом, описанный метод кластерного анализа позволяет выявлять иерархическую организацию множества объектов, используя только матрицу различий между ними.
Однако в стандартных пакетах, как отмечалось выше, такая оценка, к сожалению, не предусмотрена. Для получения более детальной информации о полученных классах используются другие методы кластеризации: например, дендритный анализ дает возможность проследить близость объектов в классах и более подробно изучить их структуру; метод k-means позволяет качественно описать каждый класс объектов и провести сравнительный анализ степени выраженности исследуемых характеристик у представителей обоих классов.
При анализе данных социально-психологических исследований взаимоотношений в коллективах помимо разбиения на классы необходимо решить вопрос о том, какие именно объекты (характеристики, признаки) связывают классы друг с другом. В этом случае целесообразным является использование дендритного метода кластерного анализа, который часто применяется совместно с иерархическим. Дендрит в данном случае – это ломаная линия, которая не содержит замкнутых ломаных и в то же время соединяет любые два элемента. Он определяется не единственным способом, поэтому предлагается построение дендрита, у которого сумма длин связей минимальна.
Итак, объекты – это вершины дендрита, а расстояния между ними – дуги. На первом этапе к каждому объекту находится ближайший (находящийся к нему на минимальном расстоянии) объект и составляются пары. Число пар равно числу объектов. Далее, если есть симметричные пары (например: i______j, j_____i ), то одна из них убирается; если в двух парах присутствует один и тот же элемент, то пары объединяются через этот элемент. Например, две пары:
i__________j,
j______k
объединяются в связку i___________j________k .
На этом заканчивается построение скоплений (плеяд) первого порядка. Затем определяются минимальные расстояния между объектами скоплений первого порядка, и эти скопления объединяются до тех пор, пока не будет построен дендрит. Группы объектов считаются вполне отделимыми, если длина дуги между ними dlk > Cp , где Cp = Сср + S, Сср – средняя длина дуги, S – стандартное отклонение.
Дендриты могут принимать форму розетки, амебообразного следа, цепочки. При совместном использовании иерархического КА и метода дендрита распределение элементов по классам получают, применив КА, а взаимосвязи между элементами анализируются с помощью дендрита.
Применение дендритного анализа к рассматриваемым данным позволило получить следующий дендрит (см. рис. 2).
Итак, в описанном выше случае Cp = 4.8. Это означает, что выделяются три класса, что несколько отличается от результата, полученного с помощью агломеративного метода. Из первого класса, в который входили объекты 1, 3, 2, отделился первый член коллектива. Во второй класс вошли объекты 8, 4, 9, 7, 6, 5 (аналогично результатам, полученным с помощью агломеративного метода).
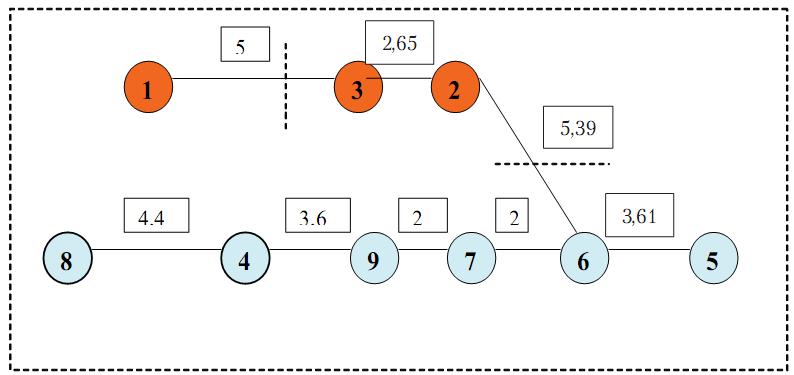
Рис. 2. Дендрит (форма простого дерева): над дугами дендрита указаны расстояния между объектами
Применение такого метода позволяет получить дополнительную информацию о том, какие объекты связывают классы друг с другом. В нашем случае это 2 и 6 объекты (члены коллектива). Данная структура аналогична социометрической, однако получена она на основе результатов тестирования. Дальнейший анализ дендрита позволит выделить группы совместимых людей (которые наиболее эффективно решают поставленные задачи в ходе совместной деятельности) либо выявить тех, кто лучше работает в одиночку, например, объект 1; 8 объект находится на границе отделимости, поэтому, возможно, ему лучше давать индивидуальные задания.
Помимо агломеративных иерархических методов существует также большое количество итеративных методов кластерного анализа. Основное отличие их состоит в том, что процесс классификации начинается с задания начальных условий: это может быть число классов, критерий завершения классификации и т.д. К таким методам относятся, например, дивизивные методы, методы k-means и другие, требующие от исследователя интуиции и творческого подхода. Еще до проведения классификации необходимо представлять, какое количество классов должно быть образовано, когда закончить процесс классификации и т.д. От верно выбранных начальных условий будет зависеть результат классификации, поскольку некорректно выбранные условия могут приводить к «размытости» классов. Таким образом, эти методы используются, если есть теоретическое обоснование, например, количества ожидаемых классов, а также после проведения иерархических методов классификации, которые позволяют выработать наиболее оптимальную стратегию исследования.
Метод k-means можно отнести к итеративным методам эталонного типа. Название ему было дано Дж. Мак-Куином. Существует много различных модификаций данного метода. Рассмотрим одну из них.
Пусть в результате проведенного исследования получена матрица измерений n объектов по m характеристикам. Множество объектов необходимо разбить на k классов по всем исследуемым характеристикам.
На первом шаге из n объектов выбираются k точек либо случайным образом, либо исходя из теоретических предпосылок. Это и есть эталоны. Каждому из них присваивается порядковый номер (номер класса) и вес, равный единице.
На втором шаге из оставшихся n-k объектов извлекается один и проверяется, к какому из классов он ближе, для чего используется одна из метрик (к сожалению, в основных статистических пакетах используется только метрика Евклида). Рассматриваемый объект относится к тому классу, к эталону которого он наиболее близок. Если есть два одинаковых минимальных расстояния, то объект присоединяется к классу с минимальным номером.
Производится перерасчет эталона, к которому присоединен новый объект, и его вес возрастает на единицу.
Пусть эталоны представлены таким образом:
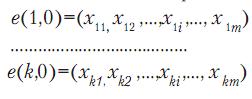
Тогда если рассматриваемый объект j относится к эталону k, то данный эталон (т.е. центр образовавшегося класса) пересчитывается следующим образом:
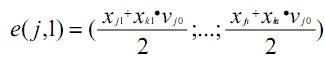
здесь vjo – вес эталона j в нулевой итерации.
Остальные эталоны остаются неизменными.
Далее процедура повторяется до тех пор, пока все n-k объекты не будут отнесены к каким-либо эталонам. Веса эталонов накапливаются.
Чтобы получить устойчивое разбиение, новые эталоны после разнесения всех объектов принимаются за начальные, и далее процедура повторяется с первого шага. Веса классов продолжают накапливаться. Новое распределение по классам сравнивается с предыдущим, если различие не превышает заданного уровня, т.е. распределения можно считать не изменившимися, то процедура классификации заканчивается.
Существует две модификации данного метода. В первой пересчет центра кластера происходит после каждого присоединения, во второй – в конце отнесения всех объектов к классам; минимизация внутрикластерной дисперсии осуществляется в большинстве итерационных методов кластерного анализа.
Обычно в методе k-means реализуется процедура построения усредненных профилей каждого класса (см. рис. 3), что дает возможность проводить качественный анализ выраженности признаков у представителей каждого класса. Для сравнения классов по выраженности тех или иных характеристик используется процедура, подобная ANOVA, сравнивающая внутрикластерные и межкластерные дисперсии по каждой характеристике и тем самым позволяющая осуществить проверку значимости различия классов по исследуемым характеристикам.
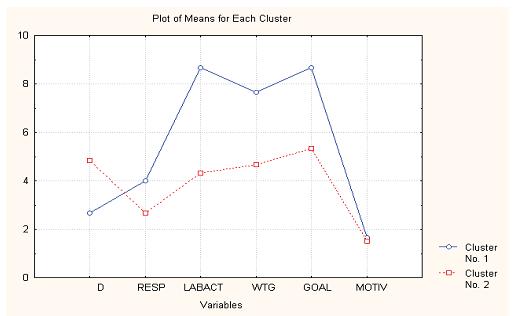
Рис. 3. Усредненные профили классов
Таблица 3. Номера объектов и расстояния от центра классов
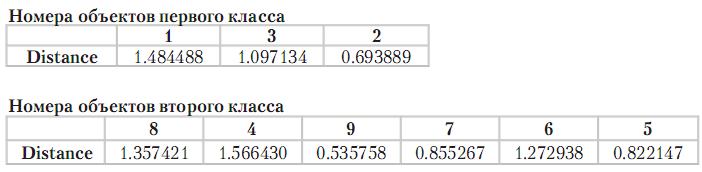
Анализ профилей показывает, что в первый класс (табл. 3) попали члены коллектива, характеризующиеся незначительной зависимостью от группы, средним уровнем ответственности и высокой трудовой активностью, работоспособностью, пониманием цели. Во вторую группу (более многочисленную) вошли сотрудники, характеризующиеся значительной зависимостью от групповых стандартов, низким уровнем ответственности, трудовой активности, работоспособности и понимания общей цели. На тех, кто вошел в состав первой группы, может быть возложена ответственность, они могут самостоятельно принимать решения и т.д.; вторая группа – это исполнители, за выполнением порученных заданий которыми необходим постоянный контроль. Заметим лишь, что мотивация низкая у обеих групп, что связано, возможно, с невысокой оплатой труда. В табл. 4 представлены результаты сравнительного анализа, демонстрирующие значимые отличия классов по трем характеристикам: трудовая активность, работоспособность и понимание цели.
Таблица 4. Анализ отделимости классов (жирным шрифтом выделены те характеристики, по которым наблюдается значимое различие между классами).

К оригинальным методам, в основе которых лежит психологическая теория, можно отнести кластерный анализ на основе теории Выготского. В работе «Мышление и речь» Выготский описывает различные генетические ступени развития понятий. В частности, он выделяет в качестве одного из важнейших этап образования комплексов, являющихся прообразами научных понятий. Он пишет, что в основе комплекса лежат фактические связи между объектами, устанавливаемые в непосредственном опыте. Поэтому такой комплекс представляет собой прежде всего конкретное объединение предметов на основании их фактической близости друг с другом. Далее он выделяет пять форм комплексов, а именно: ассоциативный комплекс, комплекс-коллекция, цепной комплекс, диффузный комплекс, псевдопонятия. Важно сразу же отметить, что во всех типах комплексов возможны любые ассоциативные связи, причем их характер может быть совершенно различным между различными парами элементов, участвующих в образовании одного и того же комплекса. Так что важнейшей особенностью образования комплексов является множественность типов ассоциативных связей между элементами, объединяемыми в комплекс. Заметим, что в качестве частного случая различий между элементами может выступать различие по какому-либо критерию. В кластерном анализе таким критерием является (моделируется) расстояние. Поскольку характер связей в ассоциативном комплексе может быть различным, то формализация осуществляется через задание на одном и том же множестве элементов нескольких различных типов попарных расстояний (или различий) между ними.
Допустим, что в описанном нами примере предметом изучения являются отношения между членами некоей малой группы, например, производственной, научной или учебной. Для одной и той же группы может быть выделено несколько типов отношений: производственные, личные, общность увлечений и т.д. Тогда для какой-либо из групп экспериментально определяется структура отношений каждого типа и строится матрица попарных расстояний (или близости) между членами группы по каждому типу отношений.
Формальное описание ситуации сводится к следующему. Задано множество M элементов А1 , А2 ,…, Аn и множество типов попарной близости этих элементов. Пусть количество этих типов m. Различные типы близости отличаются друг от друга тем, что каждый представляет собой близость по какому-либо качеству, присущему всем элементам множества. Таким образом, выделяются m качеств каждого элемента и производится сравнение (вычисление расстояний или различий) по каждому из этих качеств, что и дает m типов близости элементов. Для каждого типа близости задается матрица попарных расстояний (или различий), отражающая структуру множества элементов m по отношению к данному типу близости. Всего должно быть задано m таких матриц.
Покажем теперь, как в рамках данной формальной схемы могут быть описаны алгоритмы образования комплексов различных типов.
1. Ассоциативный кластер. Согласно Выготскому, в ассоциативном комплексе прежде всего выделяется элемент, который будет образовывать его ядро, затем остальные элементы объединяются с ядром. И здесь Выготский отмечает следующую характерную особенность данного комплекса: «Элементы могут быть вовсе не объединены между собой. Единственным принципом их обобщения является их фактическое родство с основным ядром комплекса. Связь, объединяющая их с этим последним, может быть любой ассоциативной связью» (Выготский, 1982, с. 142).
Дадим описание простейшего варианта алгоритма образования ассоциативного кластера в терминах приведенной выше формальной схемы. Сначала из заданного множества M элементов выбирается один, который будет играть роль ядра ассоциативного кластера. Ясно, что можно построить столько ассоциативных кластеров, сколько элементов в множестве M, выбирая поочередно в качестве ядра все элементы множества. Итак, выберем один элемент Ak . Далее, по каждому качеству (т.е. для каждой матрицы расстояний) выбирается элемент, ближайший к элементу Ak. Таким образом, мы получаем m или более элементов, если по каким-либо признакам выделяются два или более элементов, отстоящих от Ak на одно и то же минимальное по этому признаку расстояние. Совокупность элемента Ak как ядра и всех таким образом выбранных ближайших к нему элементов по каждому признаку и составляет ассоциативный кластер.
Возможны и более сложные алгоритмы, например, если с самого начала в качестве ядра ассоциативного кластера выбирать не один элемент, а несколько. Такой вариант кластерного анализа мы будем называть обобщенным ассоциативным кластером. Опишем алгоритм его образования более подробно.
Сначала выбирается множество элементов, которые в совокупности будут составлять ядро обобщенного ассоциативного кластера. Далее по каждому признаку для каждого из элементов ядра отбираются ближайшие по выбранному признаку элементы, а величины этих минимальных расстояний фиксируются. Затем из всех расстояний выбирается наименьшее, и происходит отбор только тех элементов, которые находятся на минимальном расстоянии от какого-либо из элементов ядра. Эта процедура повторяется для всех качеств. При этом в переборе элементов, естественно, не участвуют те, что составляют ядро кластера. Совокупность элементов ядра и всех элементов, выбранных в соответствии с описанной процедурой, и является обобщенным ассоциативным кластером. Элементы ассоциативного комплекса (по Выготскому) могут вовсе не быть объединены между собой, а находиться в ассоциативной связи лишь с ядром комплекса. Это означает, что a priori могут быть заданы не все расстояния, т.е. множество элементов упорядочится лишь частично.
Рассмотрим конкретный пример применения простейшего алгоритма образования ассоциативного кластера для анализа отношений в малой группе.
Количество членов малой группы, т.е. элементов рассматриваемого множества, n=9. Было выбрано m=3 различных типов отношений между членами малой группы: 1) взаимоотношения, связанные с основной работой, 2) взаимоотношения, связанные с неделовыми формами общения, 3) взаимоотношения, связанные с участием в дополнительной работе. По каждому типу отношений методами экспертных оценок были получены матрицы попарных различий (расстояний) между всеми членами группы.
В соответствии с описанным выше простейшим алгоритмом образования ассоциативного кластера были построены все 9 кластеров, причем в качестве ядра были выбраны поочередно все члены малой группы. На рис. 4 представлен пример полученного ассоциативного кластера, в котором в качестве ядра взят элемент А1.
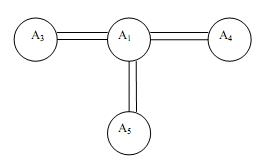
Рис. 4. Ассоциативный кластер с ядром А1
2. Цепной кластер. «Цепной комплекс строится по принципу динамического временного объединения отдельных звеньев в единую цепь и переноса значения через отдельные звенья этой цепи. Каждое звено соединено... с предшествующим... (и)... последующим, причем самое важное отличие этого типа комплекса в том, что характер связи или способ соединения одного и того же звена с предшествующим и последующим может быть совершенно различным» (Выготский, 1982, с. 144).
Теперь приведем описание алгоритма образования цепного кластера в принятых нами терминах формальной модели. Сначала из заданного множества m элементов выбирается один, который станет первым элементом, составляющим цепной кластер. Затем для каждого качества (т.е. для каждой матрицы расстояний из m заданных матриц) выбирается элемент, ближайший к первому. Из полученных M минимальных расстояний выбирается наименьшее и фиксируется номер соответствующей матрицы и номер элемента – этот элемент и будет вторым в цепном кластере. Далее процедура повторяется для второго элемента, причем первый из процесса отбора исключается. Процесс повторяется столько раз, сколько элементов в множестве M.
Заметим, что если на каком-либо шаге построения цепного кластера минимальная величина будет не у одной, а у двух или более пар элементов, то в этом случае может быть построено несколько эквивалентных цепных кластеров. Графическое изображение построенного нами цепного кластера, начинающегося с элемента А1 , представлено на рис. 5, где видно, как к группе из элементов А1 , А3 , А4 присоединяются последовательно остальные элементы. Однако необходимо подчеркнуть, что в данном исследовании цепной кластер менее информативен, чем ассоциативный, тем не менее он предоставляет дополнительные к ассоциативному кластеру сведения.
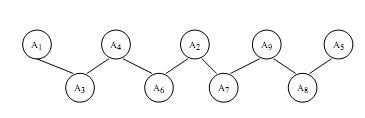
Рис. 5. Цепной кластер с ядром А1 .
3. Ассоциативно-цепной кластер. Как уже отмечалось, процедуры построения ассоциативного и цепного кластеров решают различные содержательные задачи: ассоциативный выявляет все эле менты, ближайшие к ядру по различным свойствам, а цепной показывает связь данного начального элемента последовательно со всеми остальными элементами множества. Представляется целесообразным разработать такой алгоритм, который обладал бы преимуществами как ассоциативного, так и цепного кластера. Далее приведем описание одного из возможных вариантов построения ассоциативно-цепного кластера.
Выберем сначала один элемент, который будет ядром ассоциативно-цепного кластера, в этом качестве может выступать любой элемент множества. Затем применим алгоритм образования простейшего ассоциативного кластера. Рассмотрим далее множество элементов, составивших простейший кластер. Применим к этому множеству элементов алгоритм построения обобщенного ассоциативного кластера. Далее к получившемуся множеству элементов, которые составляют обобщенный кластер, снова применим алгоритм образования. Будем повторять эту процедуру до тех пор, пока в строящийся кластер не объединятся все элементы исходного множества. Полученную в результате описанного процесса структуру и будем называть ассоциативно-цепным кластером. Это название оправданно тем, что структура подобного кластера представляет собой центральный простейший ассоциативный кластер и цепочки из элементов, составляющих простейший кластер. На рис. 6 представлен пример построения ассоциативно-цепного кластера для рассматриваемых нами экспериментальных данных. В качестве исходного элемента взят элемент А1 .
Рис. 6. Ассоциативно-цепной кластер с ядром А1
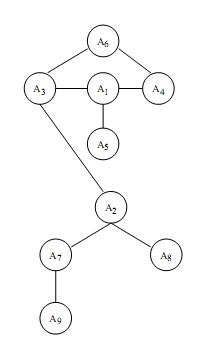
Мы видим, что к образовавшемуся простейшему ассоциативному кластеру с ядром А1 присоединяются элементы А2 , А6 , А7 и, наконец, элементы А8 и А9 на различных итерациях. Если коротко охарактеризовать смысл ассоциативно-цепного кластера, то можно сказать, что он описывает структуру заданного множества элементов по отношению к одному выделенному (на рис. 6 это элемент А1 ).
4. Кластер-коллекция. Рассмотрим, наконец, тип кластера, соответствующий комплексу-коллекции Выготского. Характеризуя его, ученый пишет, что комплексы этого типа «больше всего напоминают то, что принято называть коллекциями. Здесь различные неконкретные предметы объединяются на основе взаимного дополнения по какому-либо одному признаку и образуют единое целое, состоящее из разнородных, взаимно дополняющих друг друга частей». И далее: «Эта форма мышления часто соединяется с описанной выше ассоциативной формой. Тогда получается коллекция, составленная на основе различных признаков» (Выготский, 1982, с. 142–143).
Рассмотрим теперь описание простейшего варианта алгоритма образования кластера-коллекции в терминах приведенной выше формальной модели. Заметим, что в результате применения алгоритма построения кластера-коллекции мы должны получить набор элементов, отличающихся друг от друга хотя бы по одному признаку. К такому результату приводит, например, следующий алгоритм: сначала задается некоторый порог различия (или расстояния), при котором два элемента с разницей больше выбранного порога считаются различными. Очевидно, что результат (кластер-коллекция) будет зависеть от величины порога.
Далее раздельно для каждого признака (т.е. для каждой матрицы расстояний) применяется обычный метод кластерного анализа. По каждому признаку на основе результатов обычного анализа выбирается такое деление на кластеры, при котором расстояния между ними превышают заданный порог.
Затем рассматриваются одновременно все разбиения, выполненные по различным свойствам, и фиксируются все пересечения и разности множеств элементов, составляющих эти кластеры. Очевидно, что множества элементов, полученные таким способом, обладают следующим свойством: элементы двух различных множеств находятся хотя бы по одному признаку на расстоянии, превышающем выбранный порог. Если теперь возьмем по одному (любому) элементу из всех полученных множеств, то получим кластер-коллекцию.
Рассмотрим пример построения кластера-коллекции для наших экспериментальных данных. Напомним, что множество состоит из 9 элементов и имеются три матрицы попарных расстояний между ними. Пусть величина порога будет h=7. Проведя обычный кластерный анализ для каждой из трех матриц расстояний и применив описанную выше процедуру при величине порога h=7, получим следующие разбиения.
Для первой матрицы – три кластера:
![]()
Для второй – четыре кластера:
![]()
Для третьей – четыре кластера:
![]()
Выбирая в соответствии с описанной выше процедурой пересечения и разности всех полученных кластеров, получим в результате следующий набор множеств:
![]()
Таким образом, в кластер-коллекцию входят элементы А2 , А7 , А8, А9 и еще один (любой) элемент первого множества, например, А1 . Очевидно, что элементы кластера-коллекции А1, А2 , А7 , А8, А9 отличаются друг от друга хотя бы по одному признаку на величину, большую h=7. Так, например, элементы А1 и А2 отличаются лишь по одному третьему признаку, элементы А1 и А7 по второму и третьему, а, скажем, элементы А8 и А9 – по всем трем.
Метод латентных классов
Цель создания моделей с латентными переменными состоит в объяснении наблюдаемых переменных и взаимосвязей между ними: при заданном значении наблюдаемых переменных конструируется множество латентных переменных и подходящая функция, которая достаточно хорошо аппроксимировала бы наблюдаемые переменные, а в конечном счете плотность вероятности наблюдаемой переменной.
В факторном анализе основной акцент делается на моделирование значений наблюдаемых переменных из корреляций и ковариаций, а в методах латентно-структурного анализа – на моделирование распределения вероятности наблюдаемых переменных.
Метод латентных классов можно использовать для дихотомических переменных и порядковых шкал. Наблюдаемые переменные могут быть измерены в дихотомической шкале наименований, т.е. являются переменными (0,1) (xi =1 – наличие признака и xi =0 – отсутствие признака). Тогда наблюдаемые вероятности могут быть объяснены с помощью латентных переменных, т.е. с помощью латентных распределений и соответствующих условных распределений (Лазарфельд, 1996).
Объясняющее уравнение первого рода имеет вид:
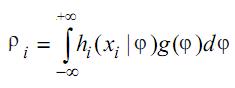
где наблюдаемые переменные – хi ; плотность вероятности наблюдаемых переменных – ρi ; множество латентных переменных – φ, плотность вероятности латентных переменных – g(φ). Объясняющее уравнение n-го порядка имеет вид:
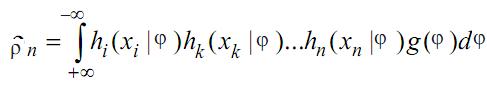
Основным предположением всех моделей латентных структур является локальная независимость. Это следует понимать так: для данной латентной характеристики наблюдаемые переменные независимы в смысле теории вероятностей. Аксиома локальной независимости имеет вид:
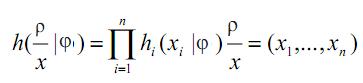
Условная вероятность называется операционной характеристикой вопроса, т.е. это вероятность получения правильной оценки того, что наблюдаемый признак j имеет место, если его латентная характеристика известна. Если φ непрерывна, то операционная характеристика называется характеристикой кривой, или следом.
По дискретности или непрерывности и по виду характеристической кривой различают следующие модели: модели латентных групп (латентную вероятность p группы можно обозначить через g, а операционную характеристику – через ![]() ); модель латентных профилей (обобщение модели латентных групп, когда наблюдаемые переменные считаются непрерывными); модель латентных расстояний, которая имеет в качестве характерной кривой функцию скачка.
); модель латентных профилей (обобщение модели латентных групп, когда наблюдаемые переменные считаются непрерывными); модель латентных расстояний, которая имеет в качестве характерной кривой функцию скачка.
Рассмотрим одну из моделей латентных групп (дискретная латентная характеристика). На основе модели Роста нами был реализован метод латентно-структурного анализа, или модель латентных классов для нормального распределения данных. Таким образом, решается следующая задача: по матрице ответов испытуемых на вопросы какого-либо теста структурируется само множество испытуемых по близости (похожести) профилей ответов.
Для этой цели сначала произвольно задаются два параметра, которые являются скрытыми – латентными, так как истинное их значение предстоит определить в процессе работы метода. Это :
- Относительное число испытуемых в классе (мы задавали его первоначально P(k) = 1/k).
- Характеристический параметр класса r(i, k) – матрица вероятности появления определенного ответа на i-й вопрос, если испытуемый относится к k-му классу. Он должен быть различным для разных классов. Мы задавали его и одинаковым для испытуемых, принадлежащих к одному классу, и различным для каждого класса. Предполагается, что условная вероятность такого события, как ответ испытуемого категории q на j вопрос, постоянна для всех испытуемых, принадлежащих к классу k. Вероятность появления ответа категории q(1,2,...,Q) равна вероятности q, являющейся суммой реализаций дихотомической случайной переменной.
В конце определяются для априорно заданного числа классов истинное относительное число испытуемых в классах и истинный параметр, определяющий вероятность появления определенного ответа на i-й вопрос, если испытуемый относится к k-му классу, что отражается в профилях, характеризующих именно данную группу испытуемых.
Мы вычисляли также наиболее вероятный профиль ответов испытуемых, принадлежащих к данному классу. Структура данных включает:
- Матрицу профилей ответов.
- Матрицу априорных вероятностей: вероятности определенного ответа на i-й вопрос при условии, что испытуемый относится к k-му классу.
- Относительное число испытуемых в классе.
В основе модели лежит формула Байеса, которая связывает априорную вероятность с апостериорной. Общая методология сводится к введению априорной плотности распределения параметров и последующему нахождению по формуле Байеса их апостериорной плотности распределения (с учетом экспериментальных данных).
Априорные распределения могут задаваться (1) стандартным способом (априорная вероятность пропорциональна числу классов); (2) исходя из профессиональных соображений, т.е. априорно задаются две латентные характеристики:
- Количество латентных классов (k) и соответствующее им относительное число испытуемых в классе Р(k);
- Параметр, определяющий вероятность определенного ответа на 1-й вопрос при условии, что испытуемый относится к k-му классу r(k).
Вероятность появления 1-го паттерна профиля :
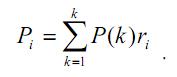
Далее по формуле Байеса вычисляется апостериорная вероятность:
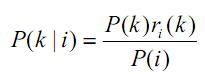
Алгоритм метода латентных групп.
Задаем:
а) количество латентных классов К,
б) количество вопросов М,
в) количество возможных категорий ответов Q,
г) количество испытуемых N,
д) начальное распределение.
Р(k) – относительное число испытуемых, которые входят в класс, например Р(k) = 1/k.
Задаем начальные значения характеристик параметров классов r(i,k) ; k = 1,..., k; i=1,…, M; r(i,k) – параметр, определяющий вероятность появления определенного ответа на i-й вопрос, если испытуемый относится к k-му классу.
Вводим Xij – ответ i-го испытуемого на j-й вопрос: i=1,…,N; j=1,...,M.
Определяем множество различных паттернов ответов: ![]() , где хij = aij ,aij – ответ на j-й вопрос. Считаем количество таких паттернов: n(i), i=1,…,L; n( i a ). Вычисляем вероятность появления паттерна i a при условии, что он генерируется испытуемым, относящимся к k-му классу:
, где хij = aij ,aij – ответ на j-й вопрос. Считаем количество таких паттернов: n(i), i=1,…,L; n( i a ). Вычисляем вероятность появления паттерна i a при условии, что он генерируется испытуемым, относящимся к k-му классу:
Вычисляем вероятность появления такого паттерна:
Вычисляем апостериорную вероятность того, что испытуемый относится к классу k, если он ответил i a :
Вычисляем математическое ожидание количества паттернов у испытуемых класса k:
Считаем оценку относительного числа испытуемых, относящихся к классу k:
Вычисляем математическое ожидание количества паттернов, в которых ответ на j-й вопрос есть x∈{ 0,...,1,Q), при условии, что отвечающие относятся к классу k:
Вычисляем оценку параметров:
Если , то мы получаем интересующие нас параметры классов, т.е
В противном случае процедура повторяется. Также нами были разработаны четыре варианта оценки кластерных разбиений. Есть множество испытуемых Х. ||X||=N – мощность множества Х равна N, т.е. N – испытуемых. В результате LSA мы получаем для каждого из К классов и N испытуемых:
– вероятность для i-го испытуемого принадлежать к k-му классу. Определяя max Pi, мы относим испытуемого i к классу, к которому он принадлежит, с максимальной вероятностью.
Разбивая множество Х на классы указанным выше образом, получаем: k X – множество испытуемых, попавших в k-й класс; – количество испытуемых, попавших в k-й класс. Тогда можно предложить следующие оценки разбиений: средняя «четкость» кластеров, наименьшая «четкость» кластеров, интегральная «четкость» кластеров, связность кластеров. Аналогично методу иерархической кластеризации, описанному выше, наиболее верно отражающей реальную структуру оказалась оценка, названная нами – связность кластеров.
Тогда возьмем два класса; их параметры – относительное число испытуемых в классе, вероятность для i-го испытуемого принадлежать к k-му классу. Из двух вероятностей выбирается большая, что и определяет класс, к которому «принадлежит» испытуемый (реально испытуемый может не принадлежать ни к одному из классов). Если при этом в одном из анализируемых классов не оказалось ни одного испытуемого, то суммарная вероятность по этому классу равна 0. Вызывает несомненный интерес тот факт, что именно «связность» работает в обоих методах, разработанных в лаборатории математической психологии, – методе латентных классов и методе иерархической кластеризации. При кластерном анализе это можно было оценить и визуально, изучая картинку дерева. В ЛСА это можно заметить следующим образом: до данного количества кластеров (определяемых этой оценкой) профили классов существенно отличаются друг от друга, а далее заметно лишь незначительное отличие. Данный метод позволяет выделить наиболее типичные паттерны восприятия стимулов и проанализировать их профили. Метод основан на вероятностном подходе, поэтому является более универсальным по сравнению с другими методами кластерного анализа. Наиболее часто метод ЛСА используется при адаптации методик, так как позволяет выделить типичные паттерны ответов и в соответствии с ними структурировать множество испытуемых, а для каждого типа оценить апостерионую вероятность. В представленной статье описаны различные методы кластерного анализа и показано, в каких случаях их можно применять с наибольшей эффективностью по отдельности, а также совместно друг с другом. Итак, в статье представлены стандартные методы, реализованные в наиболее часто используемых статистических пакетах, их развитие и усовершенствование, которое реализовано на данном этапе только в оригинальных пакетах, а также оригинальные методы, отсутствующие в статистических пакетах.