Экспериментальная психология
2019. Том 12. № 2. С. 177–192
doi:10.17759/exppsy.2019120213
ISSN: 2072-7593 / 2311-7036 (online)
Сравнительный анализ двух новых концепций адаптивного обучения
Аннотация
Общая информация
Ключевые слова: адаптивное обучение, IRT, IRT анализ, метод паттернов, марковские процессы, вейвлет-анализ, самообучающиеся системы
Рубрика издания: Математическая психология
Тип материала: научная статья
DOI: https://doi.org/10.17759/exppsy.2019120213
Финансирование. Работа выполнена при поддержке Российского фонда фундаментальных исследований (проект № 17-29-07034).
Для цитаты: Куравский Л.С., Юрьев Г.А., Думин П.Н., Поминов Д.А. Сравнительный анализ двух новых концепций адаптивного обучения // Экспериментальная психология. 2019. Том 12. № 2. С. 177–192. DOI: 10.17759/exppsy.2019120213
Полный текст
1. Введение
В последние годы выросла популярность электронного обучения, охватывающего, в широком смысле, практически все формы и способы передачи знаний, умений и навыков с помощью информационных и коммуникационных технологий. Этот подход к обучению имеет как известные преимущества, так и недостатки, наиболее значимые из которых обусловлены отсутствием эффективной адаптации учебного процесса к индивидуальным особенностям и возможностям его участников. Проблемы, связанные с формированием индивидуальных траекторий обучения, сложны для решения и наиболее актуальны при обучении неформализуемым умениям и навыкам, включая решение математических, технических, алгоритмических, изобретательских и других близких по характеру задач.
В случае традиционного обучения эти проблемы обычно разрешаются в ходе взаимодействия обучающегося с квалифицированным преподавателем, который, ориентируясь на свой субъективный опыт, формирует такие траектории с допустимой учебным процессом степенью индивидуализации, контролируя все этапы передачи знания. Такая работа, как правило, не поддается автоматизации и является своего рода искусством. Следует отметить, что указанное построение индивидуальных траекторий требует в той или иной форме решения диагностических задач (Кибзун и др., 2008, 2012), которые обеспечивают выявление особенностей и возможностей обучающихся, ограничивая тем самым выбор доступных педагогических приемов.
Задача автоматизации адаптивного обучения неформализуемым умениям и навыкам к настоящему времени не имела удовлетворительного решения. Существующие средства организации электронного обучения (Осипов и др., 2007; Сологуб, 2012), включая системы управления обучением и учебным контентом, обходят рассматриваемую проблему, решая более доступные обобщенные задачи организации учебного процесса, но не его формирования. Причина этого заключается, в первую очередь, в трудностях формализации и отсутствии подходящего математического аппарата.
Одна из основных проблем адаптивного подбора заданий (как в системах адаптивного тестирования, так и обучения), опирающегося на оценки IRT (Rasch, 1980), обусловлена приблизительным равенством вероятностей правильного и неправильного выполнения заданий, что делает результаты тестирования зависимыми в основном от посторонних случайных факторов, не связанных с измеряемыми конструктами. В 2010—2012 гг. был разработан метод адаптивного тестирования (Kuravsky et al., 2012), построенный на и|)именении идентифицируемых марковских моделей с непрерывным временем и байесовской классификации.
Как развитие этого результата, в 2017 г. предложен новый вариант марковской модели адаптивного тестирования с дискретным временем (Kuravsky et al., 2017), предполагающий оценки конструктов с использованием предельных распределений вероятностей пребывания в состояниях, вычисленных с помощью матриц вероятностей переходов. В определенном смысле этот подход может рассматриваться как расширение IRT, поскольку модель Г. Раша используется в качестве его компонента.
Созданные марковские модели адаптивного тестирования стали основой при разработке адаптивного тренажера для обучения неформализуемым умениям и навыкам, необходимым для решения математических и других комплексных задач достаточно высокой сложности, требующих владения, как стандартной техникой построения рассуждений, так и элементами творческого мышления. Особенностями методов, используемых при выборе предъявляемых заданий и обеспечивающих преимущества нового подхода перед аналогами, являются:
— выявление и использование при построении расчетных оценок временной динамики изменения способности справляться с заданиями;
— возможность учета при построении расчетных оценок времени, затрачиваемого на выполнение заданий;
— меньшее по сравнению с другими подходами число заданий, которые следует предъявлять, что ускоряет процесс тестирования, либо позволяет получать более надежные оценки за сопоставимое время.
Представленный подход наиболее эффективен не при начальном знакомстве с учебным материалом, а в ситуациях, когда требуется привести в систему и упорядочить уже
полученные знания, умения и навыки в единую качественно новую структуру: в частности, при подготовке к экзаменам.
Одной из особенностей второго подхода, рассмотренного в работе, является возможность решать задачи адаптивного обучения в условиях наличия ограниченного объема результатов наблюдений. В таких случаях построение надежных выводов желательно выполнять непосредственно по эмпирическим данным, минимизируя необходимые теоретические построения. В качестве решения, согласующегося с указанными требованиями, был разработан метод паттернов (Куравский и др., 2018) для диагностики испытуемых по так называемым тестовым траекториям — последовательностям значений, представляющим результаты выполнения тестовых заданий в порядке их появления. Тестовые траектории могут содержать как временные ряды данных, разбитых по субтестам, так объединенные временные ряды, собранные в общую последовательность. В отличие от созданных ранее методов рассматриваемый подход позволяет:
— учитывать динамику результативности выполнения тестовых заданий;
— работать с диагностическими характеристиками, непрерывно зависящими от времени (что, как правило, имеет место при диагностике операторов сложных технических систем) (Grevtsov, 2008, Krasilshchikov et al., 2011);
— строить на своей основе адаптивные технологии тестирования, позволяющие, в зависимости от результатов конкретного испытуемого, изменять как количество предъявляемых тестовых заданий, так и их содержание, добиваясь заданного уровня надежности диагностической оценки.
Оба описанных выше подхода предназначены для адаптивного тестирования, направленного на оценку уровня способностей или сформированности навыков у испытуемого. В этой работе представлено их дальнейшее развитие, реализующее процедуры адаптивного обучения и, в частности, позволяющее:
— обеспечивать адаптивность не только в отношении числа предъявляемых заданий, но и в отношении содержания обучающих материалов;
— вместо бинарного представления результатов выполнения заданий (выполнено/не выполнено), учитывать суммарную трудность различных по этому показателю успешно решенных заданий как функцию времени;
— использовать задания, связанные с несколькими шкалами измерений.
Далее в работе представлены две концепции адаптивного обучения и сравнительный анализ различных аспектов их практического применения.
Адаптивное обучение с использованием самообучающейся вероятностной модели
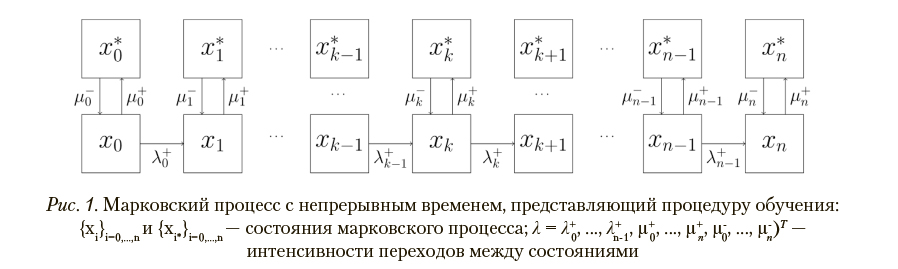
Процесс выбора заданий в системе производится с использованием марковских случайных процессов с дискретными состояниями и непрерывным временем. Подлежащими идентификации параметрами являются интенсивности переходов между состояниями. Динамика вероятностей пребывания в состояниях модели определяется системой обыкновенных дифференциальных уравнений Колмогорова в матричной форме:
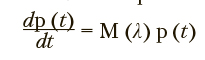
где 0 < t < T, p(t) — вероятности пребывания в состояниях процесса, Л — множество интенсивностей переходов между состояниями, M — матрица интенсивностей переходов между состояниями. Значения указанных интенсивностей определяются начальными распределениями вероятностей и наблюдаемыми частотами пребывания в состояниях Fi,d в моменты времени 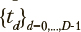 , где i — индексы состояний рассматриваемого марковского процесса; D — количество моментов времени, в которые фиксировались частоты
, где i — индексы состояний рассматриваемого марковского процесса; D — количество моментов времени, в которые фиксировались частоты 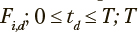 — конечный момент времени. Для описания того, как вероятности нахождения в заданных состояниях изменяются со временем, применяются процессы, организованные по схеме, изображенной на рис. 1. Эта схема представляет собой конечную цепь из 2n+2 состояний, в которой переходы из состояния
— конечный момент времени. Для описания того, как вероятности нахождения в заданных состояниях изменяются со временем, применяются процессы, организованные по схеме, изображенной на рис. 1. Эта схема представляет собой конечную цепь из 2n+2 состояний, в которой переходы из состояния 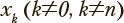 возможны только в следующее по порядку состояние xk+1 или состояние xk*. Из состояний x0 и xn доступны только состояния
возможны только в следующее по порядку состояние xk+1 или состояние xk*. Из состояний x0 и xn доступны только состояния 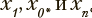 соответственно. Из состояния
соответственно. Из состояния 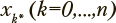 доступно только состояние xk. Для сетей указанного типа
доступно только состояние xk. Для сетей указанного типа 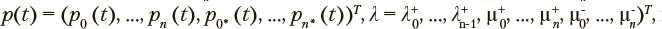 матрица M имеет порядок 2n + 2.
матрица M имеет порядок 2n + 2.
Содержательному уровню знаний, умений и навыков, имеющему номер k, ставятся в соответствие состояния xk и xk*. Для каждого номера k определяется свое множество заданий соответствующего содержания. Чем правее состояние, тем шире допустимый набор знаний, умений и навыков. Состояниям с большим номером могут (но не обязаны) соответствовать задания, включающие знания, умения и навыки для состояний с меньшим номером. В общем случае полный набор знаний, умений и навыков соответствует крайнему правому состоянию.
Более высокий содержательный уровень, как правило, требует знаний, умений и навыков, соответствующих предшествующим уровням (т. е. — в указанном смысле — с повышением содержательного уровня происходит накопление знаний, умений и навыков).
Под обучаемым далее понимается человек, проходящий процедуру обучения. Полагается, что каждый обучаемый имеет один из заданных уровней подготовки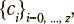 , где (z+1) — число уровней подготовки, причем каждому из указанных уровней подготовки (например, высокому, среднему или низкому) ставятся в соответствие задания с определенным уровнем трудности. Каждому содержательному уровню знаний, умений и навыков соответствуют задания всех уровней трудности.
, где (z+1) — число уровней подготовки, причем каждому из указанных уровней подготовки (например, высокому, среднему или низкому) ставятся в соответствие задания с определенным уровнем трудности. Каждому содержательному уровню знаний, умений и навыков соответствуют задания всех уровней трудности.
Например, могут быть использованы следующие уровни подготовки:
— умение выполнять действия по заданному образцу (низкий уровень);
— умение выполнять мыслительные операции, включая сравнение и анализ (средний уровень);
— умение творчески формировать новые способы решения задач из имеющихся правил и предписаний (высокий уровень).
Каждому сочетанию содержательного уровня и уровня подготовки соответствует свой набор задач. Количество задач в каждом наборе должно быть достаточным для проведения нескольких сеансов тренажа для одного обучаемого.
В случае пребывания обучаемого в состоянии xk, предъявляемое ему задание выбирается из множества, сопоставленного этому состоянию, случайным образом. Для каждого задания задается наибольшее допустимое время, отводимое для его выполнения.
Перемещения между состояниями определяются следующими правилами:
— если обучаемый, находясь в состоянии xk, правильно выполняет полученное задание, не превысив заданных ограничений по времени, он переходит в состояние xk+1;
— если обучаемый, находясь в состоянии xk, неправильно выполняет полученное задание, не превысив заданных ограничений по времени, он остается в состоянии xk;
— если обучаемый, находясь в состоянии xk и выполняя полученное задание, превышает заданные ограничения по времени, он переходит в состояние xk*;
— если обучаемый, находясь в состоянии xk* и выполняя полученное задание, превышает заданные ограничения по времени или неправильно выполняет полученное задание, не превысив заданных ограничений по времени, он остается в состоянии xk*;
— если обучаемый, находясь в состоянии xk*, правильно выполняет полученное задание, не превысив заданных ограничений по времени, он возвращается в состояние xk.
В начальный момент времени обучаемый находится в состоянии x0. По завершении процедуры тренажа он оказывается в одном из состояний, наилучшим образом соответствующих его уровню знаний, умений и навыков. Тренаж завершается либо при превышении общего лимита времени, отведенного на эту процедуру, либо после успешного выполнения задания в состоянии xn без превышения лимита времени, отведенного на это задание.
При выборе заданий для обучаемых используется информация, содержащаяся в матрицах успешных переходов. Значения свободных параметров марковских сетей идентифицируются путем сравнения наблюдаемых и прогнозируемых гистограмм, описывающих распределения частот пребывания в состояниях модели, а именно: вычисляются значения, обеспечивающие наилучшее соответствие наблюдаемых и ожидаемых частот попадания в определенное состояние системы в заданные моменты времени. При этом определяется набор интенсивностей А, обеспечивающий наименьшее значение статистики Пирсона
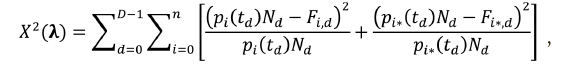
где 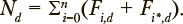 Эта статистика используется как мера соответствия модели наблюдениям. Идентификация марковских моделей с непрерывным временем проводится по выборкам обучаемых, отдельно для каждого из рассматриваемых уровней подготовки. Каждому уровню подготовки
Эта статистика используется как мера соответствия модели наблюдениям. Идентификация марковских моделей с непрерывным временем проводится по выборкам обучаемых, отдельно для каждого из рассматриваемых уровней подготовки. Каждому уровню подготовки 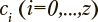 при этом ставится в соответствие свой уникальный набор оценок параметров модели λ, что позволяет в дальнейшем выявлять значение этого показателя, наилучшим образом согласующегося с наблюдениями.
при этом ставится в соответствие свой уникальный набор оценок параметров модели λ, что позволяет в дальнейшем выявлять значение этого показателя, наилучшим образом согласующегося с наблюдениями.
Для выполнения соответствующей процедуры необходимо задать систему уравнений 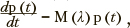 , начальные условия p (0), начальное приближение λ0, наблюдаемые частоты
, начальные условия p (0), начальное приближение λ0, наблюдаемые частоты 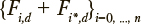 пребывания в состояниях модели, шаг интегрирования λt для численного решения системы уравнений и точность оценки. Для решения задачи идентификации разработан специальный численный метод (Куравский и др., 2015, 2017). В результате решения определяется вектор λ, оставляющий минимум функционалу X2(λ).
пребывания в состояниях модели, шаг интегрирования λt для численного решения системы уравнений и точность оценки. Для решения задачи идентификации разработан специальный численный метод (Куравский и др., 2015, 2017). В результате решения определяется вектор λ, оставляющий минимум функционалу X2(λ).
Марковские процессы, структура которых представлена на рис. 1, идентифицируются отдельно для каждого сочетания уровня подготовки и уровня трудности. Поскольку между уровнями подготовки и уровнями трудности здесь полагается взаимно-однозначное соответствие, для z+1 уровня подготовки требуется (z+1)2 идентифицированных сетей.
Трудность задания, предъявляемого обучаемому, соответствует текущей оценке его уровня подготовки. В начальный момент тренажа предъявляется задание с самым низким уровнем трудности и самым низким содержательным уровнем. После того как обучаемый, находящийся в некотором состоянии марковского процесса, завершает попытку выполнения очередного задания, вычисляются z+1 байесовских оценок вероятностей принадлежности его к рассматриваемым уровням подготовки (Kuravsky et al., 2016). При этом используются только те идентифицированные марковские процессы, которые соответствуют уровню трудности последнего предъявленного задания. Если наиболее вероятным оказывается уровень подготовки, не совпадающий с оценкой, сделанной после выполнения предыдущего задания, то обучаемому приписывается этот вновь вычисленный наиболее вероятный уровень подготовки, а сам он переводится в начальное состояние x0 (происходит «сброс состояния»). Для переходов в это начальное состояние целесообразно обеспечить некоторую «инертность», выполняя задания только в том случае, если указанная наибольшая вероятность превысит оценку вероятности текущего уровня подготовки не менее чем на заданное пороговое значение. По завершении попыток выполнения заданий самого низкого содержательного уровня «сбросы состояний» не происходят.
Таким образом, процесс тренажа сводится к предъявлению его участникам заданий, требующих для своего решения определенных знаний, умений и навыков при наличии определенного уровня подготовки. Формальная цель тренажа — привести обучающегося в крайнее правое состояние марковского процесса, что соответствует освоению всех знаний, умений и навыков при некотором уровне подготовки. В процессе тренажа используется адаптивный принцип выбора предъявляемых заданий, согласно которому их трудность должна соответствовать текущей оценке уровня подготовки обучаемых.
В процессе функционирования система дообучается на основе вновь поступающих данных о времени и успешности выполнения заданий обучаемыми. Самообучение обеспечивает:
— решение задачи оптимизации идентифицируемых параметров (интенсивностей перехода между состояниями марковского процесса) по мере накопления результатов наблюдений за обучением тех, кто работает на тренажере;
— решение задачи развития умений и навыков обучаемых за счет подбора заданий, способствующего их успешному выполнению, что стимулирует процесс обучения.
Для решения первой задачи после накопления достаточного объема результатов тренировок и, соответственно, расширения обучающей выборки проводится уточняющая идентификация параметров марковских процессов для всех рассматриваемых уровней подготовки.
Решение второй задачи подразумевает формирование квадратной матрицы Ui размера r х r (где r — число заданий, содержащихся в системе) успешных переходов для каждой из категорий ci = (i = 1, ..., I). Элементы матрицы переходов являются выборочными оценками вероятностей umn,i успешного выполнения задания m при условии выполненного задания n обучаемым, принадлежащим категории ci. В случае переходов с повышением содержательного уровня (из состояния xk в состояние xk+1) обучаемому предлагаются задания, которые имеют текущую оценку вероятности успешного выполнения, превышающую 0,75 (при их наличии в системе). Задания, удовлетворяющие этому условию, выбираются случайным образом. Если подобные задания отсутствуют, то матрица успешных переходов при их выборе не используется. Подобная организация выбора заданий способствует постепенному развитию умений и навыков за счет постановки перед обучаемыми реально достижимых целей в зоне ближайшего развития.
Программная реализация данного подхода выполнена в виде интернет-системы. Эта система позволяет настраивать обучающие материалы, а именно:
— вводить информацию о новых разделах и содержательных уровнях, представляющих собой темы, упорядочиваемые по степени сложности;
— создавать справочные материалы по темам с описанием различных способов решения тренировочных задач, аналогичных представленным;
— вводить задания с выбором различных алгоритмов проверки корректности ответа и указанием их трудности и допустимого времени, отведенного на решение.
В пилотной версии используются содержательные уровни, определяемые разделом дисциплины, и три уровня подготовки:
— умение выполнять действия по заданному образцу (низкий уровень),
— умение выполнять мыслительные операции, включая сравнение и анализ (средний уровень),
— умение творчески формировать новые способы решения задач из имеющихся правил и предписаний (высокий уровень).
3. Адаптивное обучение на основе многомерного статистического анализа вейвлет-представлений траекторий выполнения заданий и матриц рекомендуемых переходов
Полагается, что каждый обучаемый может быть отнесен к одному и только одному из заранее заданных классов, представляющих все допустимые сочетания возможных типов субъектов, проходящих обучение, и стадий обучения, каждая из которых предназначена для одного или нескольких указанных типов. Каждому из этих классов, обозначаемых индексами i ∈ {0, ..., I}, соответствует один и только один заранее определенный сценарий обучения. Множество этих сценариев включает формальный сценарий «Завершить обучение», не содержащий заданий. Совпадение сценариев обучения для различных классов допускается. Для каждого из классов i ∈ {0, ..., I}, определен один и только один последующий класс, которому соответствует рекомендуемый сценарий продолжения обучения. Переходы между указанными классами и, следовательно, сценариями обучения, представляются матрицами рекомендуемых переходов 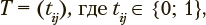 единичное значение tij. представляет переход из класса j в класс i, а нулевое — отсутствие такого перехода. Эти матрицы содержат динамически изменяемую эмпирическую информацию, обобщающую накопленный опыт. Процедура адаптивного обучения начинается со сценария, соответствующего так называемому начальному классу i0. В каждый момент обучения реализуется сценарий, соответствующий некоторому текущему классу i ∈ {0, ..., I}.
единичное значение tij. представляет переход из класса j в класс i, а нулевое — отсутствие такого перехода. Эти матрицы содержат динамически изменяемую эмпирическую информацию, обобщающую накопленный опыт. Процедура адаптивного обучения начинается со сценария, соответствующего так называемому начальному классу i0. В каждый момент обучения реализуется сценарий, соответствующий некоторому текущему классу i ∈ {0, ..., I}.
Фрагменты деятельности обучаемых с известными диагностическими показателями представлены результатами выполнения ими последовательностей заданий, соответствующих указанным сценариям обучения. Эти результаты вместе с информацией о классах обучаемых хранятся в соответствующей базе данных, образуя контрольные выборки для каждого из рассматриваемых классов.
Алгоритмические аспекты процесса адаптивного обучения, основанного на анализе вейвлет-представлений траекторий выполнения заданий (Laxhammar, Falkman, 2014) и матриц рекомендуемых переходов, представлены ниже.
Шаг 0. Определение начального сценария обучения. Первым по порядку реализуется сценарий обучения, соответствующий начальному классу i0, который на данном шаге рассматривается как текущий класс.
Шаг 1. Сбор данных. Обучаемому предъявляется или определенная индексом текущего класса последовательность заранее подготовленных заданий для каждой рассматриваемой характеристики (при этом считается, что задание связано только с одной измеряемой велт-итиной), или соответствующая текущему классу последовательность универсальных многомерных заданий, с каждым из которых связано сра.'зу i[('сколько измеряемых характеристик. Сфо рр| н р>о на и ыая в процессе выполнения предъявленных заданий последовательность результатов заносится в базу данных и подвергается анализу на последующих шагах. 11ри этом она иреобр^уется так, что каждый элемент запоминаемого временного ряда представляет собой кумулятивную сумму измеренных в логитах (Rasch, 1980) трудностей успешно выполненных заданий (от начала последовательности до текущего задания). Нулевые значения шкалы трудностей устанавливаются так, чтобы соответствовать минимальному уровню этой величинывлогитах.
Шаг 2. Удаление избыточной информации. Избыточная информация, содержащаяся в представленных выше временных рядах, удаляется с помощью метода главных компонентов (Vidal, 2016; Kong, 2017). Для этого вычисляются матрицы взаимных корреляций исследуемых временных рядов, решается алгебраическая проблема собственных значений и выясняется, насколько можно понизить размерность собственного подпространства главных компонентов с условием сохранения достаточно высокой доли (на практике, от 70% и выше) суммарной изменчивости наблюдений, представленной соответствующей дисперсией. Для каждого из оставшихся собственных направлений по одной из наибольших компонентных нагрузок выбирается представитель из числа субтестов или регистрируемых параметров (прямой переход к базису главных компонентов нецелесообразен из-за их неопределенной интерпретации). Цель этого — сохранить для последующего анализа только относительно независимые характеристики, заменяя группы существенно зависимых показателей одним представителем.
Шаг 3. Переход к интегральным характеристикам временных интервалов, используя дискретное вейвлет-преобразование. Временные ряды, представляющие процесс обучения, заменяются наборами вейвлет-коэффициентов, полученных в результате кратномасштабного анализа (Neal, 2010). При этом исходные исследуемые процессы как функции времени заменяются интегральными характеристиками, привязанными к временным интервалам в области их определения (Srivastava A., Feron E., 2011) Кратномасштабный анализ позволяет существенно сократить число показателей, необходимых для корректного представления процессов, поскольку число вейвлет-коэффициентов, используемых на последующих этапах, может быть существенно меньше, чем длина соответствующих исходных временных рядов.
Шаг 4. Вычисление матриц взаимных расстояний. Для каждой предметной области вычисляется матрица взаимных расстояний между полученными на шаге 3 вейвлет- представлениями процессов выполнения заданий каждым обучаемым. При этом матрицы взаимных расстояний для различных параметров, участвующих в анализе, складываются,
формируя итоговую матрицу. Размерность таких матриц равна объему выборки обучаемых, подлежащих анализу. Предполагается, что информация о результатах выполнения заданных контрольных последовательностей заданий (сценариев обучения) для каждого обучаемого хранится в соответствующей базе данных.
Шаг 5. Многомерное шкалирование для анализа взаимного расположения обучаемых в пространстве приемлемой размерности. Вычисленное взаимное расположение обучаемых в пространстве многомерного шкалирования (Trevor, Cox, 2001; Borg, Groenen, 2011) является основой для диагностических решений. Размерность пространства шкалирования определяется, исходя из условия достаточной дифференциации предусмотренных категорий обучаемых.
Шаг 6. Кластеризация обучаемых в пространстве шкалирования. Координаты расположения обучаемых в пространстве, полученном в результате многомерного шкалирования, являются входными данными для процедуры кластеризации (Gariel et al, 1999; Gaffn\v, Smyth, 1999, 2001; Li et al., 2010; Enriquez, Kurcz, 2012; Hung et al.. 2015; Wilson et al.. 2016; Eerland, Box, 2016). Цель — выявить субъектов, наиболее близких по результатам обучения.
Шаг 7. Вычисление расстояний до центров кластеров обучаемых или до ближайшего фрагмента деятельности по результатам выполнения последовательности заданий. В случае достаточно больших выборок, вычисляется расстояние до центров определенных на шаге 5 кластеров обучаемых в пространстве шкалирования. Если выборки малы, то определяется ближайший фрагмент деятельности из базы данных, что может быть выполнено двумя способами: либо непосредственно, вычисляя ближайший фрагмент деятельности в евклидовой метрике вейвлет-представлений, либо путем выявления такого фрагмента в итоговом пространстве шкалирования, используя ту же метрику.
Шаг 8. Распознавание классов обучаемых с помощью выборочных функций распределений расстояний до центров кластеров. Вероятностные оценки принадлежности обучающихся определяются с помощью выборочных функций распределений Fi(X) евклидовых расстояний X о центров кластеров, соответствующих распознаваемому классу i ∈ {0, ..., I} в результирующем пространстве шкалирования. Вычисленные величины 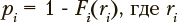 — евклидово расстояние до центра i-го кластера, рассматриваются как оценки вероятности принадлежности рассматриваемого обучающегося к заданным классам. Распределение по классам
— евклидово расстояние до центра i-го кластера, рассматриваются как оценки вероятности принадлежности рассматриваемого обучающегося к заданным классам. Распределение по классам 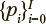 характеризует надежность полученной оценки. Данный подход фактически реализует в обобщенной форме идею линейного дискриминантного анализа, не требуя при этом наложения ряда ограничений на результаты наблюдений.
характеризует надежность полученной оценки. Данный подход фактически реализует в обобщенной форме идею линейного дискриминантного анализа, не требуя при этом наложения ряда ограничений на результаты наблюдений.
Шаг 9. Выбор текущего класса обучаемого или ближайших представителей разных классов с оценкой различий по конкретным параметрам. В В случае достаточно больших выборок, в пространстве шкалирования определяется класс индексом imax вероятность рi gринадлежности к которому, вычисленная на предыдущем шаге, является наибольшей. Если такой класс не является единственным или выборки малы, то определяется ближайший фрагмент деятельности с индексом ic из базы данных, что может быть выполнено либо непосредственно, вычисляя ближайший фрагмент деятельности в евклидовой метрике вейвлет-представлений, либо путем выявления такого фрагмента в итоговом пространстве шкалирования, используя ту же метрику. Выявленный класс с индексом imax или ic рассматривается далее как текущий.
Шаг 10. Определение нового текущего класса. Для текущего класса с помощью матрицы рекомендуемых переходов T пределяется последующий класс. Выявленный последующий класс далее полагается текущим. Если новому текущему классу соответствует формальный сценарий «Завершить обучение», то выполняется переход на шаг 11, иначе — переход на шаг 1.
Шаг 11. Останов.
Таким образом, адаптивность представленного подхода достигается за счет n^c^(^<^j^a оптимальных сценариев обучения с опорой на анализ динамики выполнения ywtmbw: заданий. Для этооо используются методы многомерного статистического анализа вейвлет-представлений траекторий выполнения заданий и информация, содержащаяся в матрицах рекомендуемых переходов. Для практических приложений важно, что рассмотренный подход применим при наличии в базе данных как достаточно больших, так и малых выборок фрагшнтовдеятелъностиобучсизмых.
Описания методов многомерного статистического анализа вейвлет-представлений траекторий выполнения заданий и их различные практические применения представлены в работах Л.С. Куравского с соавт. (Куравский и др., 2018; Kuravsky et al., 2019). Эти методы программно реализованы в Intelligent System for Flight Analysis (ISFA) с использованием системы графического программирования LabVIEW.
Сравнительный анализ представленных концепций адаптивного обучения
Общие комментарии
Подход, основанный на многомерном статистическом анализе вейвлет-представлений траекторий выполнения заданий, предполагает подбор оптимального сценария обучения на основе анализа динамики выполнения заданий и сопутствующей статистической информации. С точки зрения процесса обучения, подбор оптимального сценария обучения может быть более эффективным, чем подход с использованием самообучающегося марковского процесса, предполагающего наличие большого числа заданий для каждого содержательного уровня. Каждое задание, помимо характеристики принадлежности к содержательному уровню, обладает показателем трудности и ограничения на время выполнения. В качестве предварительного показателя временного ограничения можно использовать экспертную оценку, а после накопления необходимого для функционирования системы объема выборки — некоторую усредненную величину. Предполагается, что трудность заданий и их соответствие содержательным уровням определяется с помощью эксперта. Во втором подходе задача оценки ограничений времени выполнения для каждого задания не решается явно — предполагается, что наличие известных сценариев обучения корректно представляет временную динамику выполнения заданий для различных классов испытуемых.
Одной из важных задач, решаемых в процессе функционирования систем, основанных на втором подходе, является задача определения размерности пространства шкалирования для последующего достижения заранее установленного качества дифференциации обучаемых. Решение данной задачи зависит от начального объема хранимых сценариев обучения в базе, от результатов применения метода главных компонентов и от параметров вейвлет-преобразо- вания. Большой объем хранимых фрагментов деятельности обучаемых может сократить размерность результирующего пространства, упростив интерпретацию результатов кластерного анализа. Подход, основанный на использовании самообучающегося марковского процесса, в меньшей степени зависит от параметров промежуточных процедур. Оценка принадлежности испытуемого производится с помощью вычисления условных вероятностей по окончании времени обучения и пребывания испытуемого в фиксированном состоянии модели.
Системы обучения (в том числе адаптивные) предполагают повторение процедур обучения до достижения целевого уровня навыков. При этом базы данных систем должны располагать большим количеством различных заданий с определенными характеристиками, соответствующими различным уровням трудностей и содержательным уровням. Для
относительно простых содержательных уровней такая проблема может быть решена применением специальных алгоритмов генерации заданий, однако для более сложных уровней решение задачи может быть затруднительным. Кроме задачи генерации заданий для сложных содержательных уровней, для данного этапа характерна проблема автоматической проверки ответа в случае открытого характера заданий.
Оба подхода допускают автоматическое дообучение реализующей их системы по мере накопления эмпирических данных.
Первый подход позволяет обеспечить большую степень сокращения количества заданий, необходимых для предъявления испытуемым.
Необходимый объем эмпирических данных
В обоих подходах используются эмпирические данные. Идентификация моделей в случае первого подхода производится на основе эмпирических частот пребывания в состояниях модели, что может потребовать достаточно объемных выборок. Малые объемы выборок могут привести к неустойчивым оценкам значений свободных параметров и матриц успешных переходов. В то же время особенностью подхода на основе самообучающейся марковской модели является постоянное обновление и корректировка оценок компонентов этой матрицы.
Во втором подходе так же, как и в первом, используются заранее собранные эмпирические данные, однако его реализация допускает предельно малые выборки: на шаге 7 в качестве ближайшего объекта будет рассматриваться не центр кластера (случай большой выборки), а ближайший фрагмент деятельности, содержащийся в базе данных. Этот подход позволяет накапливать результаты наблюдений и, после появления в базе достаточного числа похожих фрагментов деятельности, объединить их в кластер.
Таким образом, второй подход допускает работу с меньшими объемами эмпирических данных, чем первый.
Программная реализация
Сложность программной реализации двух представленных подходов обусловлена выбором языка реализации. Учитывая нетривиальную математическую составляющую как первого, так и второго подходов, для реализации следует выбирать программные среды, дающие доступ к надежным средствам вейвлет-преобразований, численной оптимизации, решения систем дифференциальных уравнений и т. д.
Современные технологии адаптивного тестирования все чаще реализуются в виде ин- тернет-ресурсов — это позволяет эффективно накапливать и обрабатывать данные испытаний. Кроме того, веб-реализации позволяют существенно расширить круг испытуемых за счет возможности дистанционного прохождения тестов. Это справедливо и для систем адаптивного 015- учения: большой объем выборки позволяет накапливать информацию, необходимую для формирования и корректировки траекторий обучения конкретного испытуемого. Реализация приведенных в работе подходов к адаптивному ovowionnio может быть выполнена стандартными средствами веб-разработки, однако для наиболее сложных этапов обеих технологий рекомендуется либо использовать специализированные среды (LabVIEW, MATLAB, R, Julia, Python — с обязательным использованием пакета numpy), либо создавать соответствующие модули на языке C++.
Достаточно трудной частью реализации подхода, основанного на использовании самообучающихся марковских процессов, является идентификация моделей для каждого уровня подготовки. В общем случае этот процесс может занимать продолжительное в|)омя. Для роиio-
ния подобных задач был разработан метод дискретизации значимых параметров (Kuravsky et al., 2015; Куравский и др., 2017), существенно снижающий размерность пространства параметров, значения которых определяются в процессе решения задачи идентификации.
Учитывая необходимость идентификации систем дифференциальных уравнений, описывающих вероятностную динамику пребывания в состояниях марковских процессов, первый подход представляется более сложным, как в вычислительном плане, так и для программной реализации.
Финансирование
Работа выполнена при поддержке Российского фонда фундаментальных исследований (проект № 17-29-07034).
Литература
-
Кибзун А.И., Панарин С.И. Формирование интегрального рейтинга с помощью статистической обработки результатов тестов // Автоматика и телемеханика. 2012. № 6. 119—139.
-
Кибзун А.И., Вишняков Б.В., Панарин С.И. Оболочка системы дистанционного обучения по математическим курсам // Вестник компьютерных и информационных технологий. 2008. № 10. С. 43—48.
-
Куравский Л.С., Мармалюк П.А., Юрьев Г.А., Думин П.Н. Численные методы идентификации марковских процессов с дискретными состояниями и непрерывным временем // Математическое моделирование. 2017. Т. 29. № 5. С. 133—146.
-
Куравский Л.С., Юрьев Г.А., Ушаков Д.В., Юрьева Н.Е., Валуева Е.А., Лаптева Е.М. Диагностика по тестовым траекториям: метод паттернов // Экспериментальная психология. 2018. Т. 11. № 2. С. 77— 94. doi:10.17759/exppsy.2018110206
-
Осипов Г.С., Брянцев О.А. Модифицированный метод сводных показателей как метод оценки систем дистанционного обучения для морского флота // Эксплуатация морского транспорта. 2007. № 3 (49). С. 48—52.
-
Сологуб Г. Б.Построение фреймовых семантических моделей в интеллектуальной системе тестирования // Информационные и телекоммуникационные технологии. 2012. № 14. С. 87—93.
-
Aircraft trajectory clustering techniques using circular statistics. Yellowstone Conference Center, Big Sky, Montana, 2016. IEEE.
-
Bastani V., Marcenaro L., Regazzoni C. Unsupervised trajectory pattern classification using hierarchical Dirichlet Process Mixture hidden Markov model // 2014 IEEE International Workshop on Machine Learning for Signal Processing (MLSP) / IEEE. 2014. P. 1—6.
-
Borg I., Groenen P.J.F. Modern Multidimensional Scaling Theory and Applications // Springer. 2005. P. 140.
-
Cramer H. Mathematical Methods of Statistics. Princeton: Princeton University Press. 1999. 575 p.
-
Eerland W.J., Box S. Trajectory Clustering, Modelling and Selection with the focus on Airspace Protection // AIAA Infotech@ Aerospace. AIAA. 2016. P. 1—14.
-
Enriquez M. Identifying temporally persistent flows in the terminal airspace via spectral clustering // Tenth USA/Europe Air Traffic Management Research and Development Seminar (ATM2013) / Federal Aviation Administration (FAA) and EUROCONTROL. Chicago, IL, USA: 2013. June 10—13.
-
Enriquez M., Kurcz C. A Simple and Robust Flow Detection Algorithm Based on Spectral Clustering // International Conference on Research in Air Transportation (ICRAT) / Federal Aviation Administration (FAA) and EUROCONTROL. Berkeley, CA, USA, 2012. May 22—25.
-
Gaffney S., Smyth P. Joint probabilistic curve clustering and alignment // Advances in Neural Information Processing Systems. Vol. 17. Cambridge, MA: MIT Press, 2005. P. 473—480.
-
Gaffney S., Smyth P. Trajectory clustering with mixtures of regression models // Proceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining. 1999. P. 63—72.
-
Srivastava A., Feron E. Trajectory clustering and an application to airspace monitoring // IEEE Transactions on Intelligent Transportation Systems. 2011. Vol. 12. № 4. P. 1511—1524.
-
Grevtsov N. Synthesis of control algorithms for aircraft trajectories in time optimal climb and descent // Journal of Computer and Systems Sciences International. 2008. Vol. 47. № 1. P. 129—138.
-
Hung C., Peng W., Lee W. Clustering and aggregating clues of trajectories for mining trajectory patterns and routes // The VLDB Journal — The International Journal on Very Large Data Bases. 2015. Vol. 24. № 2. P. 169—192.
-
Krasilshchikov M.N., Evdokimenkov V.N., Bazlev D.A. Individually adapted airborne systems for monitoring the aircraft technical condition and supporting the pilot control actions. M.: MAI Publishing House, 2011. 440 p (in Russian).
-
Kuravsky L.S., Artemenkov S.L., Yuriev G.A., Grigorenko E.L. New approach to computer-based adaptive testing // Experimental Psychology. 2017. Vol. 10. № 3. P. 33—45. doi:10.17759/exppsy.2017100303
-
Kuravsky L.S., Margolis A.A., Marmalyuk P.A., Panfilova A.S. , Yuriev G.A. Mathematical aspects of the adaptive simulator concept // Psychological Science and Education. 2016. Vol. 21. № 2. P. 84—95. doi: 10.17759/pse.2016210210 (in Russian).
-
Kuravsky L.S., Margolis A.A., Marmalyuk P.A., Panfilova A.S., Yuryev G.A., Dumin P.N. A Probabilistic Model of Adaptive Training [Электронный ресурс] // Applied Mathematical Sciences. 2016. Vol. 10. № 48. 2369. URL: https://doi.org/10.12988/ams.2016.65168 (дата обращения 13.04.2019)
-
Kuravsky L.S., Marmalyuk P.A., Yurev G.A. Diagnostics of professional skills based on probability distributions of oculomotor activity// RFBR Journal. 2016. №. 3 (91). P. 72—82 (Supplement to “Information Bulletin of RFBR” № 24, in Russian).
-
Kuravsky L.S., Marmalyuk P.A., Yuryev G.A. and Dumin P.N. A Numerical Technique for the Identification of Discrete-State Continuous-Time Markov Models [Электронный ресурс] // Applied Mathematical Sciences. , 2015. Vol. 9. № 8. P. 379—391. URL: https://doi.org/10.12988/ams. 2015.410882. (дата обращения 13.02.2019)
-
Kuravsky L.S., Marmalyuk P.A., Yuryev G.A., Belyaeva O.B., Prokopieva O.Yu. Mathematical foundations of flight crew diagnostics based on videooculography data [Электронный ресурс] // Applied Mathematical Sciences. 2016. Vol. 10. № 30. P. 1449—1466. URL: https://doi.org/10.12988/ams.2016.6122 (дата обращения 3.02.2019).
-
Kuravsky L.S., Marmalyuk P.A., Yuryev G.A., Dumin P.N., Panfilova A.S. Probabilistic modeling of CM operator activity on the base of the Rasch model // Proc. 12th International Conference on Condition Monitoring & Machinery Failure Prevention Technologies. Oxford, UK, June 2015.
-
Kuravsky L.S., Yuriev G.A. Probabilistic method of filtering artefacts in adaptive testing // Experimental Psychology. 2012. Vol. 5. № 1. P. 119—131 (in Russian).
-
Kuravsky L.S., Yuryev G.A. Certificate of state registration of the computer program № 2018660358 Intelligent System for Flight Analysis v1.0 (ISFA#1.0). — Application № 2018617617; declared 18 July 2018; registered 22 August 2018. — (ROSPATENT).
-
Kuravsky L.S., Yuryev G.A. Detecting abnormal activities of operators of complex technical systems and their causes basing on wavelet representations [Электронный ресурс] // International Journal of Civil Engineering and Technology (IJCIET). Vol. 10 (2). P. 724—742. URL: http://www.iaeme.com/IJCIET/ issues.asp?JType=IJCIET&VType=10&IType=2. (дата обращения 19.03.2019)
-
Kuravsky L.S., Yuriev G.A., Dumin P.N. Estimating the Influence of Human Factor on the Activity of Operators of Complex Technical Systems in Civil Engineering with the Aid of Adaptive Diagnostics [Электронный ресурс] // International Journal of Civil Engineering and Technology. 2019. Vol. 10 (2). P. 1930—1941, http:// www.iaeme.com/IJCIET/issues.asp?JType=IJCIET&VType=10 &IType=02(дата обращения 11.01.2019)
-
Kuravsky L.S., Yuryev G.A. On the approaches to assessing the skills of operators of complex technical systems // Proc. 15th International Conference on Condition Monitoring & Machinery Failure Prevention Technologies. Nottingham, UK, September 2018. 25 p.
-
Laxhammar R., Falkman G. Online learning and sequential anomaly detection in trajectories // IEEE Transactions on Pattern Analysis and Machine Intelligence. 2014. Vol. 36. № 6. P. 1158—1173.
-
Li Z. et al. Incremental clustering for trajectories // Database Systems for Advanced Applications. Lecture Notes in Computer Science. 2010. Vol. 5982. P. 32—46.
-
Markov models in the diagnostics and prediction problems: Textbook / Edited by L.S. Kuravsky. 2nd Edition, Enlarged. Moscow: MSUPE Edition, 2017. 203 p. (in Russian).
-
Neal P.G. Multiresolution Analysis for Adaptive Refinement of Multiphase Flow Computations. University of Iowa, 2010. 116 p.
-
Rasch G. Probabilistic models for some intelligence and attainment tests. // Copenhagen, Danish Institute for Educational Research, expanded edition (1980) with foreword and afterword by B.D. Wright. Chicago: The University of Chicago Press, 1960/1980.
-
René Vidal, Yi Ma, Shankar Sastry. Generalized Principal Component Analysis [Электронный ресурс]/ New York: Springer-Verlag, 2016. URL: http://www.springer.com/ us/book/9780387878102 (дата обращения 13.04.2019)
-
Rintoul M., Wilson A. Trajectory analysis via a geometric feature space approach // Statistical Analysis and Data Mining: The ASA Data Science Journal. 2015.
-
Trevor F. Cox, M.A.A. Cox. Multidimensional Scaling, Second Edition. Chapman & Hall/CRC, 2001. 299 p.
-
Wilson A., Rintoul M., Valicka C. Exploratory trajectory clustering with distance geometry // International Conference on Augmented Cognition / Springer. 2016. P. 263—274.
-
Xiangyu Kong, Changhua Hu, Zhansheng Duan. Principal Component Analysis networks and algorithms [Электронный ресурс]. Springer, 2017. URL: http://www.springer.com/us/book/9789811029134 (дата обращения 13.04.2019)
Информация об авторах
Метрики
Просмотров
Всего: 1280
В прошлом месяце: 18
В текущем месяце: 9
Скачиваний
Всего: 466
В прошлом месяце: 2
В текущем месяце: 2