Введение
Защита от сетевых угроз в настоящее время является одной из важнейших проблем информационной безопасности компьютерных систем. Применяемые в облачной среде стандартные средства ее поддержки, включая средства идентификации пользователей, ограничения прав доступа и объемов трафика, шифрование данных, программно-аппаратная защита низкого уровня и привлечение в особых случаях операторов в режиме ручного управления, не обеспечивают должную эффективность.
Практический опыт сопровождения компьютерных сетей выявил перспективность выявления возможных угроз на основе анализа поведения пользователей в реальном времени. В частности, компания Symantec применяет облачный сервис «Cloud Access Security Broker» (CASB) (https://www.symantec.com/content/dam/symantec/docs/solution-briefs/ secure-use-of-cloud-apps-and-services.pdf), в котором для каждой процедуры, выполняемой пользователем в облаке, методами машинного обучения определяется уровень риска, на основе которого программируется определенный тип поддержки безопасности.
Система LANeye (LANeye Network Intrusion Detection and Prevention Software) (http:// www.laneye.com/software/laneye-product-description.pdf) анализирует трафик пользователя по детерминированным правилам, не применяя методы машинного обучения и сравнивая значения наблюдаемых параметров с аналогичными показателями прошлой сессии.
В системе UEBA ( User and Entity Behavior Analytics), разработанной компанией Exabeam (https://www.exabeam.com/data-science/user-entity-behavior-analytics-scoring- system-explained/), применен комплексный метод выявления угроз от пользователей и аномалий в их поведении. Для этого строится набор различных индикаторов, основанных на статистическом анализе, предупреждениях о наличии вредоносных программ, а также на методах машинного обучения (таких как обнаружение доменов DGA — Domain Generation Algorithm — с помощью нейросетевых и других способов моделирования). Текстовые данные о пользователе переводятся в числовые с уменьшением размерности с помощью сингулярного разложения (https://www.exabeam.com/data-science/a-user-and- entity-behavior-analytics-system-explained-part-ii/), после чего полученные компактные данные классифицируются методом опорных векторов SVM (Support Vector Machine). Оценка пользователя формируется как сумма полученных индикаторов с динамически настраиваемыми весами.
Одной из наиболее актуальных научных задач, возникающих при создании подобных систем, является разработка современного математического аппарата для распознавания некорректного поведения пользователей компьютерных сетей, адаптированного к анализу данных, характеризующих сетевую активность, и пригодного для использования в рамках интеллектуальных систем для прогнозирования и выявления угроз. Подобные системы должны работать в облачной среде в автоматическом режиме и, по возможности, обладать способностью к самообучению.
К настоящему времени накоплен определенный опыт в решении этой задачи. Как средство ее решения, специалистами применялись многие хорошо известные методы классификации, включая:
— распознавание с помощью бинарных деревьев решений (Фаткиева, Левоневский, 2015; AlGhamdi et al., 2008);
— динамические и многопользовательские байесовские сети (Дайнеко, 2013; AlGhamdi et al., 2008);
— искусственные нейронные сети (Большев, 2011);
— анализ временных рядов (Фаткиева, 2012; Фаткиева, Левоневский, 2013);
— использование простейших статистических характеристик (Фаткиева, 2012);
— методы анализа графов;
— метод опорных векторов (Mingyuan et al., 2015);
— скрытые марковские модели (Banafar et al., 2014; Hong et al., 2015; Modi, Quadir, 2014);
— генетические алгоритмы (Hameed, 2014; Singh et al., 2016);
— ограниченные машины Больцмана (Hua et al., 2017);
— рассуждения по прецедентам (case-based reasoning) (Herrero et al., 2009; Wang et al., 2011);
— методы многомерного статистического анализа, включая кластерный и дискриминантный анализ.
Все они — за исключением классических методов многомерного статистического анализа и различных вариантов использования простейших статистических характеристик — в большей или меньшей степени продемонстрировали свою эффективность, однако общим слабым местом остается отсутствие неэвристических количественных критериев для обоснованного отнесения пользователей к проблемной категории. Указанные выше статистические методы в рассматриваемой предметной области, как правило, дают неприемлемые результаты (см. иллюстрацию их применения в разделе 2.1).
С целью преодоления возникшей проблемы, в этой работе предложены два подхода к распознаванию некорректного поведения пользователей компьютерных сетей, опирающиеся на:
— критерий для выявления отклонений в поведении пользователей: по характеристикам, усредненным на временных интервалах без учета содержательной динамики поведения;
— критерий для определения категорий пользователей по выполненным последовательностям типовых действий (т. е. с учетом содержательной динамики поведения).
Третий подход данного типа — метод паттернов, использующий возможности вейв- лет-преобразований для диагностики по тестовым траекториям, — представлен в работах (Куравский и др., 2018; Kuravsky, Yuryev, 2018).
Следует отметить, что предложенные методы являются средствами решения достаточно широкого класса задач психологической диагностики и педагогических измерений. В частности, они могут применяться для выявления определенных особенностей в поведении пользователей в социальных сетях, характеризующих психологическое неблагополучие. Критерий для определения категорий пользователей по выполненным последовательностям типовых действий (т. е. с учетом содержательной динамики поведения) найдет свое применение в педагогических измерениях, например, для анализа действий при подготовке к ЕГЭ с целью определения наиболее комфортной траектории обучения. Кроме того, рассмотренные средства имеют хорошие перспективы в исследованиях, связанных с психологией труда, включая оценку психологической усталости оператора сложных систем по изменившимся последовательностям типовых действий.
Количественный критерий для выявления отклонений в поведении
пользователей по характеристикам, усредненным на временных интервалах
без учета содержательной динамики поведения
Общее описание
Критерий для выявления отклонений в поведении пользователей при диагностике сетевых угроз опирается на применение самоорганизующихся карт признаков (Self-Organizing Feature Maps), или сетей Кохонена (Kohonen, 2001). Входной слой сети выполняет распределительные функции. На этот слой подаются закодированные (в том числе, если необходимо, используя схему «Один-из-N») интегральные характеристики деятельности пользователя за определённые периоды времени, состав и содержание которых могут меняться в зависимости от конкретной решаемой задачи. Выходной слой (топологическая карта) образует прямоугольную матрицу, составленную из элементов на радиальных базисных функциях. При последовательной обработке каждого обучающего примера выбирается расположенный ближе всего к нему нейрон («выигравший» нейрон). Затем, взяв взвешенную сумму прежнего центра соответствующего радиального элемента и обучающего примера, параметры выигравшего нейрона и нейронов из его окрестности корректируются так, чтобы они стали в большей степени похожи на входной пример. Окрестность в процессе обучения сжимается до нулевого отклонения от «выигравшего» нейрона. Результатом последовательности таких корректировок является то, что определенные участки сети «перетягиваются» в сторону обучающих примеров и похожие наблюдения активируют группы близко лежащих нейронов на топологической карте.
Для заданных категорий пользователей (в первую очередь, для пользователей, деятельность которых не представляет опасности для системы) вычисляются выборочные распределения расстояний до выигравшего нейрона. При этом предполагается, что пользователи с отклонениями в поведении присутствуют в обучающей выборке в определенной небольшой пропорции, не оказывая существенного влияния на результат обучения. Пользователи с относительно редким поведением фактически рассматриваются как потенциально опасные. Важно, что данное предположение позволяет не выполнять предварительное распознавание пользователей с отклонениями в поведении в исходных эмпирических данных. Если пользователь с относительно редким поведением рассматривается как неопасный, то его следует включить в обучающее множество. Если пользователь с опасным поведением похож на представителей «неопасных» классов, то его следует исключить из обучающего множества.
Полученные выборочные распределения в дальнейшем используются для проверки статистических гипотез о принадлежности пользователей к заданным классам. При этом в качестве статистики, для которой вычисляются вероятности, сопоставляемые с уровнем значимости, используется расстояние до выигравшего нейрона. Уровень значимости является параметром постановки задачи. Его стандартное значение — 0,05, однако, в зависимости от содержания прикладной задачи, этот показатель может варьироваться от 0,01 до 0,1.
Представленная технология распознавания типов пользователей представлена на рис. 1, где в условии p<p* использованы следующие обозначения: p* — уровень значимости для проверки гипотезы, р=1— 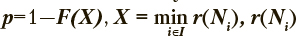 — евклидово расстояние от набора характеристик деятельности оцениваемого пользователя до нейрона N сети Кохонена, i e I — индекс нейрона, I — множество индексов нейронов, F(X) — выборочная функция распределения случайной величины X.
— евклидово расстояние от набора характеристик деятельности оцениваемого пользователя до нейрона N сети Кохонена, i e I — индекс нейрона, I — множество индексов нейронов, F(X) — выборочная функция распределения случайной величины X.
Если гипотезы о принадлежности к «безопасным» классам отвергаются при принятом уровне значимости (p<p*) или, при том же уровне значимости, при наличии соответствующих эмпирических данных не отвергаются гипотезы о принадлежности к «опасным» классам (p>p*), то пользователь идентифицируется как представляющий опасность.
Новизна рассмотренного подхода заключается в том, что:
— для формирования статистики, используемой для проверки гипотез о принадлежности к выявляемым классам пользователей, используются сети Кохонена, представляющие один из видов самообучающихся нейронных сетей;
— вычисленные с их помощью выборочные распределения используются для оценки вероятностей, сопоставляемых с уровнем значимости.
Пример построения критерия
Для построения критерия использовалась сформированная путем эксперимента обучающая выборка из 323 пользователей, 318 из которых принадлежали к 3 классам с «безопасным» поведением («programmer», «serfer» и «lazyman»), а 5 — к классу пользователей с отклонениями в поведении («violator»). Показатели пользовательской активности, на основе которых строились оценки, представлены в отчете (см. Отчет о прикладных научных исследованиях и экспериментальных разработках на тему «Разработка интеллектуальных алгоритмов выявления сетевых угроз в облачной вычислительной среде и методов защиты от них, основанных на анализе динамики трафика и определении отклонений в поведении пользователей». Этап 1. ФЦП «Исследования и разработки по приоритетным направлениям развития научно-технического комплекса России на 2014—2020 годы»).
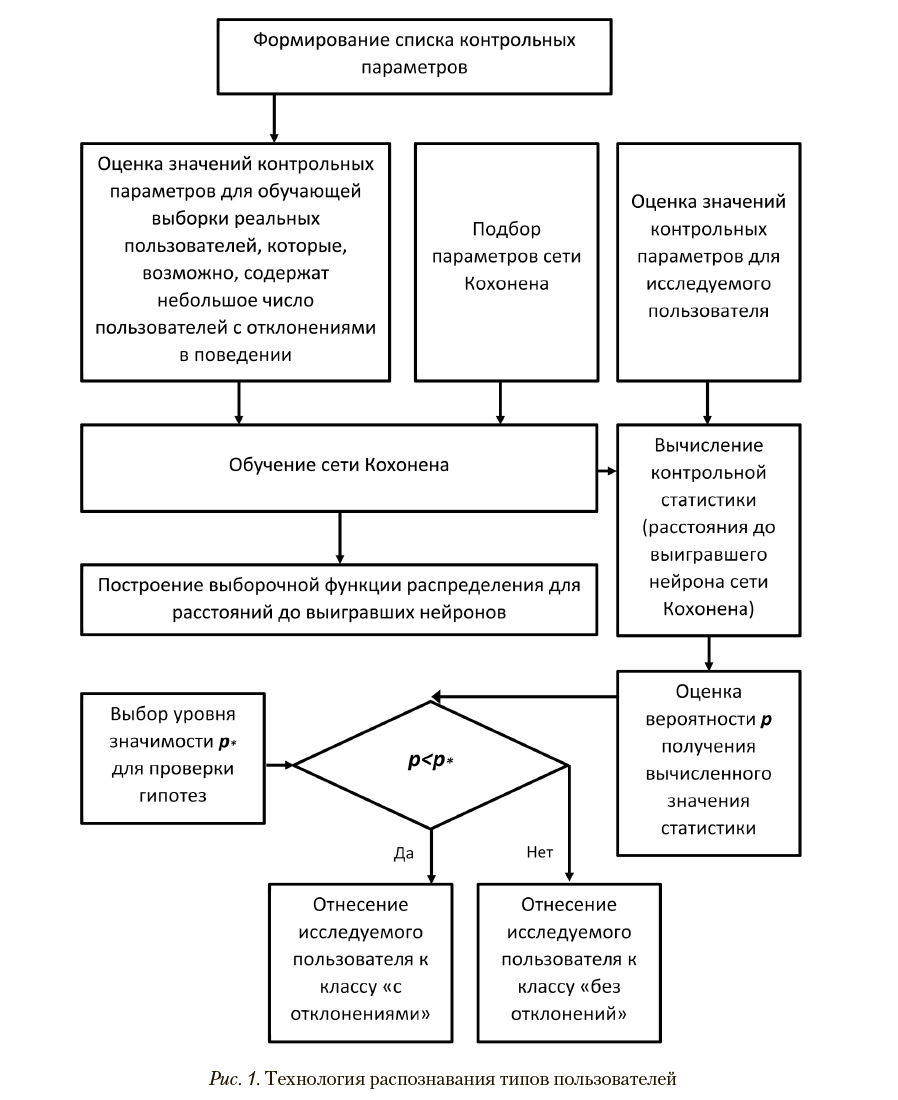
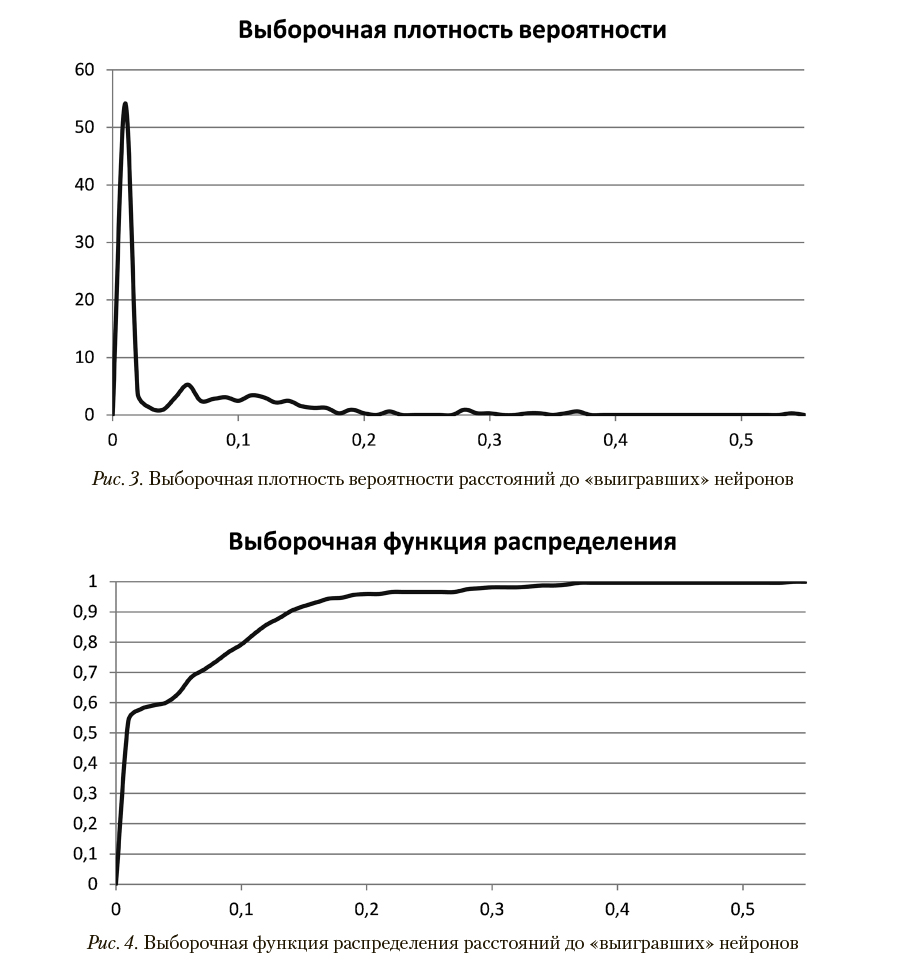
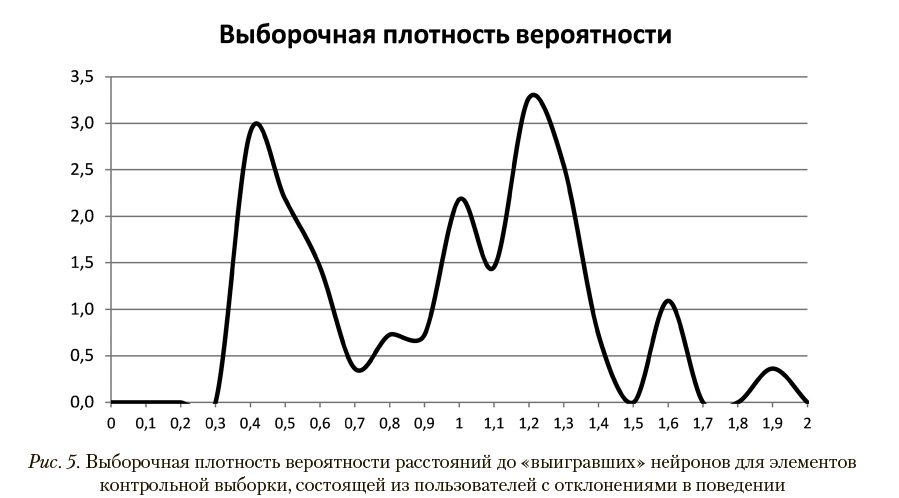
Топологическая карта сети, размеченная по этой выборке, представлена на рис. 2. Выборочная плотность вероятности и выборочная функция распределения расстояний до «выигравших» нейронов представлены, соответственно, на рис. 3 и 4.
Для оценки надежности распознавания использовалась контрольная выборка из 55 пользователей с отклонениями в поведении, параметры которых были выявлены в процессе экспериментов. Оценки расстояний до «выигравшего» нейрона для элементов указанной выборки позволили вычислить выборочную плотность распределения, показанную на рис. 5. Минимальное расстояние до «выигравшего» нейрона при этом составило 0,34,
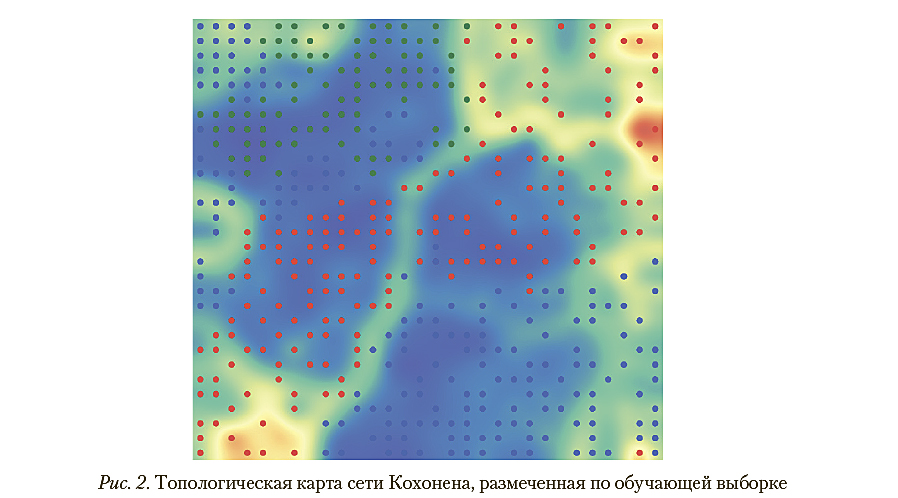
максимальное — 1,88. Выборочная функция распределения для обучающей выборки, представленная на рис. 3, позволяет утверждать, что вероятность появления расстояний до «выигравшего» нейрона, превышающих минимальное расстояние, равное 0,34, в случае пользователей без отклонений в поведении не превышает 0,015.
Поэтому проверки нулевых гипотез о том, что пользователи из контрольной выборки (с отклонениями в поведении) относятся к «безопасным» классам, привели к тому, что указанные нулевые гипотезы были отвергнуты при высоком уровне значимости (p<0,015), и все пользователи с отклонениями были правильно идентифицированы как не относящиеся к «безопасным» классам.
Имеющиеся экспериментальные данные свидетельствуют о высокой надежности распознавания как вследствие высокого уровня значимости при отвержении гипотез, так и вследствие полного отсутствия ошибок при распознавании пользователей с отклонениями для контрольной выборки. Таким образом, предложенный критерий для распознавания пользователей с отклонениями продемонстрировал высокую эффективность на доступных эмпирических данных.
Распределения значений рассматриваемых параметров не позволяют применить для классификации пользователей классический дискриминантный анализ вследствие отклонений от нормальности и статистически значимых отличий матриц ковариаций для разных типов пользователей, однако этот метод можно использовать для грубой оценки степени их дискриминации.
Статистика Уилкса для полного набора из 48 параметров составляет 0,18 (F(144,966)=5,1204; p<0,0001), что свидетельствует о статистически значимой, но относительно грубой дискриминации. Дискриминантный анализа Фишера1 обеспечил 75%-е распознавание типов пользователей, при этом «опасные» пользователи распознавались только в 47,3% случаев, что не является удовлетворительным результатом. Матрица классификации приведена в табл. 1.
Удаление 17 переменных, которые не значимы для распознавания типов пользователей, методом «Forward Stepwise» повысило значение статистики Уилкса до 0,20 (F(93,1015)=7,6180; p<0,0001), снизив процент корректного распознавания до 73,5%, при этом процент распознавания «опасных» пользователей уменьшился до 41,8% (см. матрицу классификации в табл. 2).
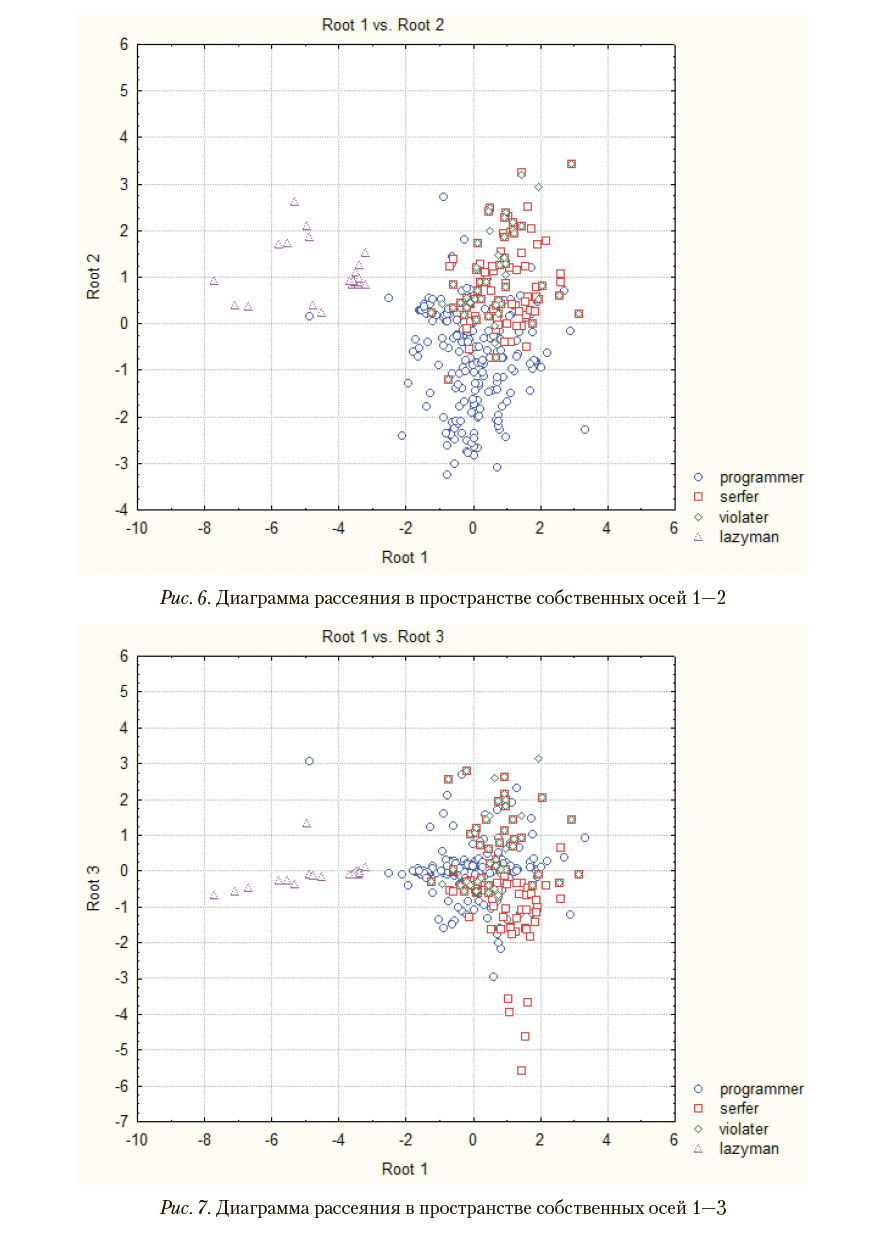
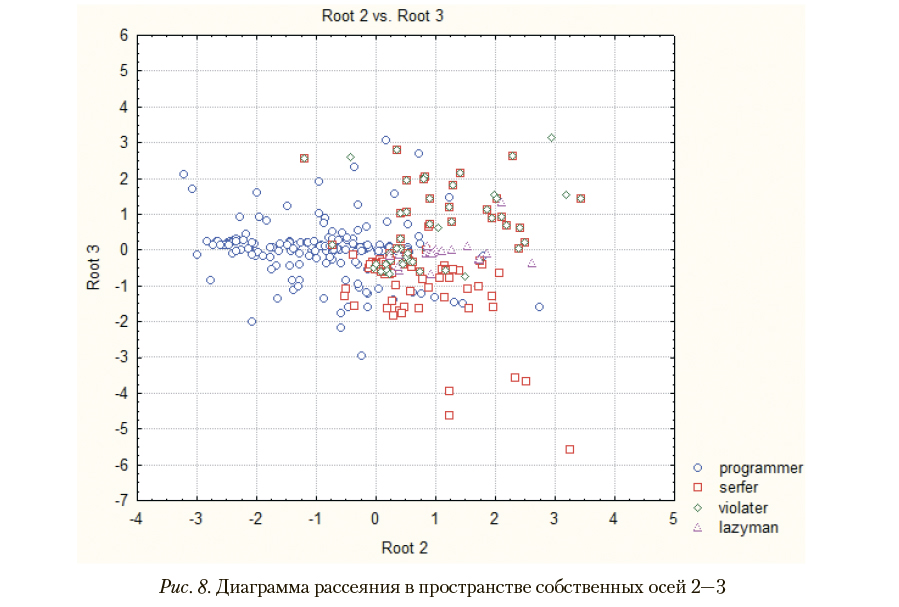
На рис. 6—8 приведены диаграммы рассеяния, качественно иллюстрирующие дискриминацию рассматриваемых типов пользователей при каноническом дискриминантном
Таблица 1
Матрица классификации в случае 48 параметров
|
|
Percent |
programmer |
serfer |
violater |
lazyman |
|
programmer |
90.0 |
180 |
16 |
3 |
1 |
|
serfer |
52.6 |
25 |
50 |
20 |
0 |
|
violater |
47.3 |
20 |
9 |
26 |
0 |
|
lazyman |
100.0 |
0 |
0 |
0 |
23 |
|
Total |
74.8 |
225 |
75 |
49 |
24 |
Таблица 2
Матрица классификации в случае 31 параметра
|
|
Percent |
programmer |
serfer |
violater |
lazyman |
|
programmer |
90.0 |
180 |
15 |
4 |
1 |
|
serfer |
50.5 |
29 |
48 |
18 |
0 |
|
violater |
41.8 |
21 |
11 |
23 |
0 |
|
lazyman |
100.0 |
0 |
0 |
0 |
23 |
|
Total |
73.5 |
230 |
74 |
45 |
24 |
анализе в собственном подпространстве, базис которого задает направления наибольшей неоднородности обучающей совокупности наблюдений. Для формирования указанного собственного подпространства выбираются собственные вектора, которые соответствуют первым по порядку наибольшим собственным значениям, объясняющим достаточно высокий процент наблюдаемой дисперсии.
Характеристики собственного подпространства, использованного для построения диаграмм рассеяния, приведены в табл. 3.
Таблица 3
Характеристики собственного подпространства, использованного для построения диаграмм рассеяния
|
No |
Eigenvalue |
Wilks’ Lambda |
Chi-Square |
df |
p-level |
|
0 |
1.49 |
0.20 |
566.93 |
93 |
0.000 |
|
1 |
0.80 |
0.50 |
243.25 |
60 |
0.000 |
|
2 |
0.10 |
0.91 |
34.58 |
29 |
0.219 |
Хорошо видно, что пользователи с опасным поведением не отделяются от остальных групп. Неудовлетворительный процент распознавания «опасных» пользователей и качественный анализ взаимного расположения пользователей различных типов в рассмотренном собственном подпространстве позволяют говорить о невозможности распознавания «опасных» пользователей с помощью классических методов дискриминантного анализа. В то же время критерий, опирающийся на возможности сетей Кохонена, эффективно решает эту задачу.
Таким, образом, можно утверждать, что предложенный критерий демонстрирует существенно более высокую эффективность, чем классические методы многомерного статистического анализа.
Количественный критерий для определения категорий пользователей
по выполненным последовательностям типовых действий с учетом
содержательной динамики поведения
Для представления динамики поведения пользователей используются марковские процессы с дискретными состояниями и дискретным временем (цепи Маркова). В этих моделях типовым действиям пользователей (таким как открытие, копирование, удаление, пересылка файлов, имеющих заданные форматы и диапазоны размеров, запуск определенных типов приложений и т. д.) соответствуют определенные состояния, а вероятности переходов между состояниями являются параметрами модели и определяются типом пользователя. Каждой категории пользователей l е {0, ..., z}, включая пользователей как с корректным, так и некорректным поведением, соответствует своя модель с уникальным набором вероятностей переходов между состояниями.
Поведение пользователей характеризуется последовательностями выполненных ими типовых действий, которые в терминах данной модели интерпретируются как последовательности состояний.
Динамика вероятностей пребывания в состояниях модели как функций дискретного времени определяется следующим матричным уравнением:
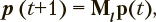 ,
,
где t — дискретное время; 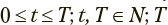 — конечный момент времени; N — множество натуральных чисел;
— конечный момент времени; N — множество натуральных чисел; 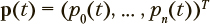 — представляет вероятности пребывания в состояниях модели в момент времени t; n — число состояний;
— представляет вероятности пребывания в состояниях модели в момент времени t; n — число состояний; 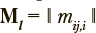 — стохастическая квадратная матрица вероятностей перехода между состояниями цепи Маркова порядка n,
— стохастическая квадратная матрица вероятностей перехода между состояниями цепи Маркова порядка n,
в которой 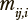 — вероятность перехода из состояния j в состояние i для пользователя категории l.
— вероятность перехода из состояния j в состояние i для пользователя категории l.
Идентификация рассмотренных марковских моделей выполняется, используя эмпирические данные о частотах переходов от одного типового действия к другому для каждой рассматриваемой категории пользователей. Каждая категория пользователей l имеет свою идентифицированную матрицу 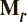 .
.
Отнесение пользователей к одной из заданных категорий 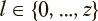 выполняется на основе выполненных им типовых действий, заданных последовательностью пройденных состояний
выполняется на основе выполненных им типовых действий, заданных последовательностью пройденных состояний 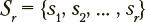 . При этом для каждой из указанных категорий вычисляется соответствующая байесовская оценка:
. При этом для каждой из указанных категорий вычисляется соответствующая байесовская оценка:
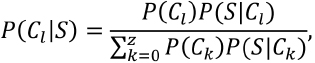
где C¡ — факт принадлежности пользователя к категории l; S — событие, представляющее собой прохождение последовательности состояний Sr; P(Cl) — априорная вероятность принадлежности пользователя к категории l; P(S| Cl) — вероятность прохождения последовательности состояний Sr при условии принадлежности к категории l; P(Cl|S) — вероятность принадлежности к категории l при условии, что пользователь прошел последовательность состояний Sr.
Для вычисления вероятностей используются элементы матриц Мl:
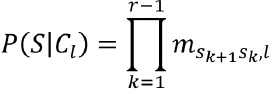
Категория пользователей, для которой достигается максимальная условная вероятность 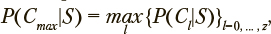 , обеспечивает требуемый выбор. Распределение вероятностей
, обеспечивает требуемый выбор. Распределение вероятностей 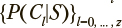 позволяет оценить его надежность.
позволяет оценить его надежность.
Примеры практического применения критериев данного типа представлены в работах (Куравский и др., 2016; Куравский, Юрьев, 2011; 2012; Куравский и др., 2017; 2018; Kuravsky et al., 2016).
Основные выводы и результаты
1. Разработан критерий для выявления отклонений в поведении пользователей при диагностике сетевых угроз, опирающийся на технику проверки статистических гипотез и использующий в качестве инструмента для формирования целевой статистики сети Кохонена, представляющие один из видов самообучающихся нейронных сетей. Особенностями подхода являются:
— оценка вероятностей, сопоставляемых с уровнем значимости, непосредственно по выборочным распределениям расстояний до выигравшего нейрона, полученным для обучающей выборки, без построения аналитического выражения целевой статистики;
— возможность обучения сети Кохонена на смешанной выборке, допускающей наличие в определенной небольшой пропорции потенциально опасных пользователей, что позволяет избежать необходимости их выявления на ранних этапах исследования, когда не известны соответствующие идентифицирующие признаки.
2. Предварительная оценка, проведенная с использованием доступных экспериментальных данных, выявила высокую эффективность предложенного подхода: для потенциально опасных пользователей гипотеза об их принадлежности к «безопасные» классам отвергалась при уровне значимости не более 0,015; все 100% потенциально опасных пользователей были распознаны. Применение классических методов многомерного статистического анализа, выполненное для сравнения различных подходов на тех же данных, выявило, что пользователи с опасным поведением не отделяются от остальных групп классическими способами. В частности, неудовлетворительный процент распознавания (<50%) опасных пользователей и качественный анализ взаимного расположения пользователей различных типов в рассмотренном собственном подпространстве позволили говорить о невозможности распознавания этой категории пользователей с помощью классических методов дискриминантного анализа.
3. Разработан метод определения категорий пользователей, включая пользователей с отклонениями в поведении, по выполненным последовательностям типовых действий, использующий для представления динамики поведения пользователей марковские процессы с дискретными состояниями и дискретным временем (цепи Маркова). Особенностями подхода являются:
— представление поведения пользователей последовательностями выполненных ими типовых действий, которые в терминах применяемой модели интерпретируются как последовательности состояний;
— использование для каждой категории пользователей, включая пользователей как с корректным, так и некорректным поведением, отдельной модели с уникальным набором вероятностей переходов между состояниями;
— отнесение пользователей к одной из заданных категорий на основе байесовских оценок и оценок правдоподобия.
Финансирование
Работа выполнена при финансовой поддержке Министерства образования и науки Российской федерации в рамках соглашения о предоставлении субсидии от «26» сентября 2017 г. № 14.579.21.0155 (Уникальный идентификатор соглашения — RFMEFI57917X0155) на выполнение прикладных научных исследований и экспериментальных разработок по теме: «Разработка интеллектуальных алгоритмов выявления сетевых угроз в облачной вычислительной среде и методов защиты от них, основанных на анализе динамики трафика и определении отклонений в поведении пользователей».
1Для вычислений использовался пакет статистического анализа STATISTICA.