Summary
The joint cognitive activity issue was developed in the works of a large number of Russian and foreign researchers (L.S. Vygotsky, B.F. Lomov, V.V. Rubtsov, A.N. Leontiev, J. Wertsch, etc.). As J. Wertsch points out, the high relevance of this issue can be explained by two reasons: first, by the key importance of joint activity for the development of cognitive functions in ontogenesis; second, by the ecological validity — we perform most cognitive tasks not in isolation but in cooperation with other people [24]. According to L.B. Resnick, outside the laboratory and school, cognition is almost always cooperative [Shepherd, 2010]. B.F. Lomov in his works stresses the high importance of studying cognitive functions within the framework of joint activity, because these functions are revealed most fully in this activity [Rychkova, 2014].
Many researchers highlight the fact that human cognitive activity has a fundamentally social nature (L.S. Vygotsky, M. Tomasello, etc.). This thesis is often understood in the way that the higher mental functions are forming at a certain stage of child’s development through the cooperation with an adult [Vygotskii, 1984]. However, some researchers point out that adults’ cognition also has a socially mediated (co-operative) character, i.e., it is performed through another person [Goodwin, 2013; Verhagen, 2015; Walther, 2006].
In the terminology of C. Goodwin’s theory of co-operative action, when building some action, an individual provides to the public space semiotic resources or materials organizing this action. Participants of joint activity selectively use these resources for building their own actions, i.e., include structure of other people’s actions to the internal organization of their own activity [Goodwin, 2013].
In other words, in the process of cooperative action individuals almost instantly integrate the results of other person’s cognitive activity into their own cognitive activity. This propensity to integrate cognitions with the other person requires certain functions, one of which is the tendency to pick up the results of others’ cognitive activity. This picking up concerns (1) the schematic (conceptual) perception of the other person, (2) language constructs, (3) gestures and action structures [Hanks, 2000].
Goodwin’s syntactic priming is one example of the integration of cognitions with another person [Goodwin, 2013]. Tony says to Chopper, “Why don’t you get out of my yard?” to which Chopper replies: “Why don’t you make me get out of the yard?” This conversation demonstrates how Chopper picks up Tony’s lexical construction and integrates it into his own answer. He builds his action not from the scratch, but by performing operations with the material provided by the other person. First, he breaks down into two parts the linguistic structure provided by Tony. Second, he adds his own material (“make me”) to this structure, creating a fundamentally new action.
Another example of integration of cognitions with another person is a gaze following phenomenon. A number of studies have shown that this process is involuntary, automatic [Goodwin, 2017; Sprong, 2007]. If we see a person looking to the left, we involuntarily orient our attention to the same direction. This fact has been verified in many experiments [Friesen, 1998; Goodwin, 2017].
However, the phenomenon of “gaze following” is a part of the more complex process — modeling the perceptual activity of another individual [Zotov, 2015]. To illustrate, here is an example. If the observer sees a person with both hands suddenly raised up, he/she understands that such person perceives the situation within the “threat of firearms” scenario. The observer looks the same direction as the observed person and tries to find an object that falls into the category “aimed weapon”. In other words, the observer tries to model another person’s perceptual activity. The observer integrates the results of other person’s perceptual activity (the person saw the aimed weapon) into his/her own perceptual activity (identifies the object that falls into the relevant category). This modeling process requires complex operations of top-down categorization (from a general category to a specific object), and gaze following is a part of this complex process [Andrianova, 2017].
But the question remains whether the observer will integrate the results of the observed individual’s perceptual activity into own perceptual activity if there is no information about the direction of that individual’s gaze, and the observer can only infer what the individual sees from his/her behavior and facial expressions. In this situation, would the observer focus attention on the objects that are relevant to the categorical perception of the observed individual? Whether such integration, provided by top-down categorization, is an automatic, involuntary process, can it be consciously controlled? In order to answer these questions, two experiments have been performed.
Experiment 1
Participants. The study involved 70 healthy participants aged from 19 to 23 years (mean age — 20.1 years), who were randomly divided into the Group A (35 subjects) and the Group B (35 subjects).
Method. As instructed, participants in the Group A watched the videos of “silent” social scenes, lasting from 65 to 124 s. In the final part of each video, a character’s emotional reaction (fear, amazement, etc.) was demonstrated close-up, showing that he/she perceived an object of a certain category (something frightening, etc.). After the demonstration of the character’s emotional reaction the video was suddenly interrupted and the subjects had to shift their gaze to the fixation cross on the gray background (0.5 s) and then perform the task of searching for the target letter. The task consisted of the following. After the fixation cross, a sequence of video frames, not previously seen by the subjects, was shown for 5 s. where the subjects observed the scene from the character’s perspective, demonstrating what he/she saw. These frames included (1) a large and visually noticeable letter “O” or “X” and (2) a relatively small and inconspicuous object that caused the character’s emotional reaction and was in the focus of his/her attention. The instruction stated that the main task of the subjects was to search and identify the target letter (“O” or “X”) as quickly as possible and name it aloud. And only after that they could look at the objects in the video frames, including the object that caused the character’s emotion. At the end of each trial, subjects were asked to describe the content of the viewed videos and to explain the character’s behavioral reaction.
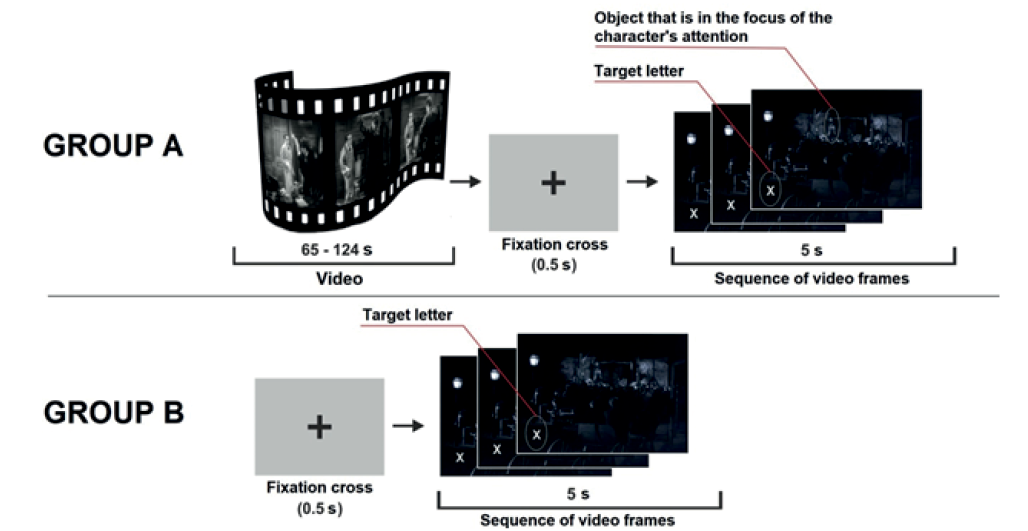
Fig. 1. Experimental procedure
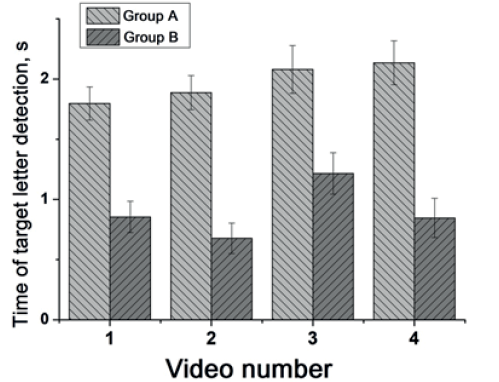
Fig. 2. Mean time of target letter detection in subjects of the Groups A and B for each video
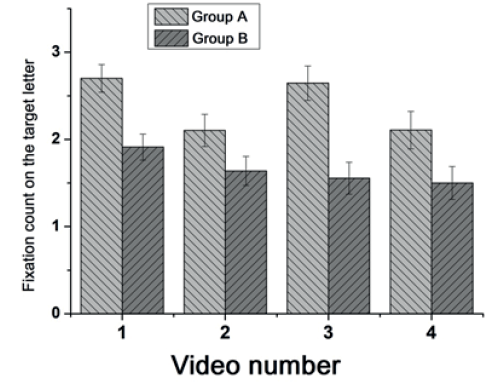
Fig. 3. Mean fixation count on the target letter in subjects of the Groups A and B for each video
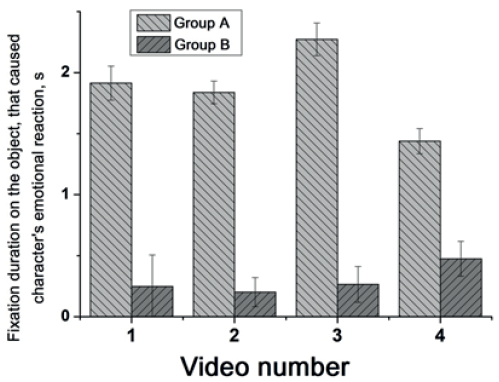
Fig. 4. The total fixation duration on the object, that caused character’s emotional reaction, in the subjects of the Groups A and B for each video
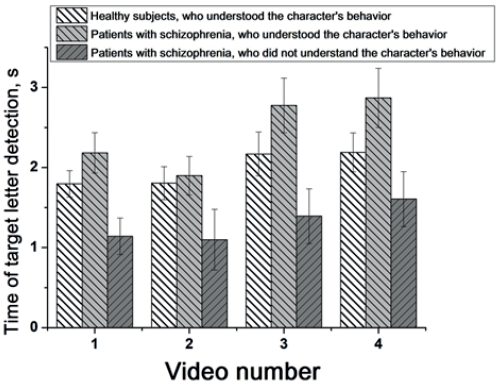
Fig. 5. Mean time for detecting the target letter in patients who understood and did not understand the character’s behavior and healthy subjects of the Group A for each video
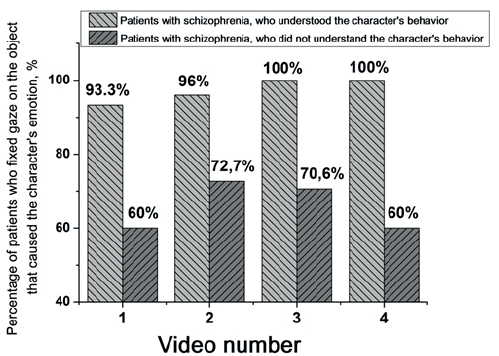
Fig. 6. Percentage of patients who understood and did not understand the character’s behavior, who fixed their gaze on the object that caused the characters’ emotional reaction for each video
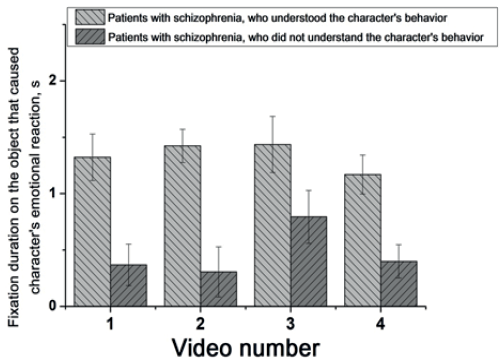
Fig. 7. The total fixation duration on the object, which caused the characters’ emotional reaction, in patients who understood and did not understand the character’s behavior for each video
Thus, the experimental procedure described above has modeled a “cognitive conflict” situation. We assumed that the task of searching for the target letter would conflict (interfere) with searching for the objects that caused the character’s emotional reaction.
The Group B subjects performed the same experimental procedure, with the exception that they didn’t watch the video frames. Each trial began with a demonstration of a fixation cross on a gray background (0.5 s). After that the subjects were presented with video frame sequences where they had to search for the target letters (Fig. 1).
Equipment and material. Videos of social scenes were presented on a 19-inch LCD color monitor with a resolution of 1280×1024 pixels. The distance from the screen to subject’s eyes was 60 cm. The angular sizes of the presented video fragments and scene frames were 25°×18°. Eye movements recordings were performed with the Tobii X120 non-contact eye movement recording system (Tobii Technology, Sweden) with a frequency of 120 Hz (spatial resolution of 0.3°). The subject had a calibration procedure before performing each sample. Eye movement recordings with low validity values were excluded from the analysis.
The study was performed on the material of four videos of social situations from the silent black-and-white movies chosen through the expert assessments: “Girl shy” (USA, 1924), “The kid brother” (USA, 1927) and “Speedy” (USA, 1928). We will give a description of two videos for the illustrative example.
The video 1 (the movie “The kid brother”). The sheriff’s son, by his father’s order, tries to shut down a street performance of scam artists. The scammers trick the sheriff’s son into handcuffs and hang him over the stage making him look like a laughingstock in public. The sheriff is walking not far from the performance place. A close-up shows him suddenly stopping, looking ahead and frowning his eyebrows. What he sees is hidden from the viewer. A fixation cross follows. Then comes the scenes that show the stage and the sheriff’s son hanging over it.
The video 2 (the movie “The Speedy”). The cab driver takes a passenger’s suitcases and walks to the cab. He sees his cab suddenly moves off and drives away. He throws the passenger’s suitcases on the sidewalk and runs after the cab. A close-up shows the surprised and sorrowful expression on the passenger’s face as he looks at the sidewalk. What he sees is hidden from the viewer. A fixation cross follows. Next comes the scenes showing a suitcase lying on the sidewalk and a thin stream of liquid flowing out of it.
The objects that caused characters’ emotional reactions were small (up to 3.0°) and had a low “visual saliency” level in all the frames used in the task of searching for the target letter. The target letter also had a small size (2.0°), but a high level of “visual saliency”. Visual saliency of the frame areas was assessed using the “Saliency Toolbox”. [Wertsch, 1989].
Registered parameters. The subjects’ eye movements were recorded while viewing each video and while performing the following task of searching for the target letter. The visual fixations and saccades were recorded using the “I-VT” algorithm [Miyake, 2000]. [Miyake, 2000]. The software “Tobii Studio 3.2.1” was used to calculate count and duration of fixations of the subjects’ eyes on the so-called dynamic areas of interest (AOIs), i.e., areas that move in exact accordance with the movement of objects (subjects, characters’ faces, etc.) on a video. The data have been analyzed using one-factor and multivariate analysis of variance methods with the SPSS v.23 package.
Results and Discussion
The verbal responses of the subjects have been analyzed for each video. It was found that 100% of healthy subjects successfully explained character’s behavior and correctly identified objects in the focus of their attention.
A one-factor analysis of variance (ANOVA) was performed for the letter detection time parameter. It was found that subjects who observed character behavior (the Group A), compared to subjects who did not observe it (the Group B), spent significantly more time detecting the target letter in the frames after the video 1 (F (2.12) = 24.7; p<0.001), 2 (F (2.12) = 40.7; p<0.001), 3 (F (2.12) = 10.8, p<0.05), and 4 (F (2.12) = 27.7, p<0.001) (Fig. 2).
In order to understand the reasons for these differences, a comparative analysis of the eye-movement parameters while performing the task of searching for the target letter have been performed in the two groups of subjects. A one-factor ANOVA showed that the Group A subjects compared to the Group B required more gaze fixations on the target letter to identify it in the frames after the video 1 (F (2.14) = 13.1, p<0.001), 2 (F (2.14) = 3.5, p<0.05), 3 (F (2.14) = 16.5, p<0.01), and 4 (F (2.14) = 3.6, p<0.05) (Fig. 3).
It was found that many subjects in the Group A, despite the instruction, first fixed their gaze on the object that caused the character’s emotion and only then shifted their gaze to the target letter. The percentage of such subjects was 61% for the video 1, 56% for the video 2, 64% for the video 3, and 53% for the video 4.
In addition, subjects in the Group A compared to subjects in the Group B spent significantly more time to visually analyze the object that caused the characters’ emotional reactions in the frames after video 1 (F (2.14) = 32.2, p<0.001), 2 (F (2.14) = 117.7, p<0.001), 3 (F (2.14) = 102.7, p<0.001) and 4 (F (2.14) = 35.4, p<0.001) (Fig. 4).
The results of the study have showed that healthy subjects who observed the character’s behavior, unlike healthy subjects who did not observe it, picked up the results of the character’s perceptual activity (e.g., “the sheriff noticed his hanging son”) and automatically integrated these results into their own perceptual activity even in the absence of information about the direction of the sheriff’s gaze. In other words, they involuntarily identified and analyzed the objects/elements of the situation that were perceived by the character and determined his emotional reaction, and only after that they performed the primary task of searching for the target letter.
The process of such integration will be analyzed using the example of the video 1. Subjects in the Group A know from the semantic context that the sheriff sent his son to shut down the street performance. They see the scammers hanging the sheriff’s son over the stage and continuing the show, then the subjects observe the emotional reaction of the sheriff who is walking nearby (he abruptly stops and frowns his eyebrows). This reaction is the so-called “material anchor” [Komogortsev, 2010], which makes it possible to identify what the character perceives at this particular moment. In C. Goodwin’s terms, it represents the material provided by the character to the public space [Goodwin, 2013]. Observers make the suggestion from the evaluation of the sheriff’s reaction that he perceives or “defines” the situation [Goffman, 2003] as “outrageous”. The Group A subjects, despite repeated instructions from the experimenters to prioritize searching for the letter, involuntarily model the sheriff’s perceptual activity by identifying and analyzing the element of the situation (“the sheriff’s hanging son”) that is in the focus of his attention and supports the sheriff’s perception of the situation as “outrageous”. Thus, the Group A subjects, as compared to the Group B subjects, spend more time analyzing the area of this element and searching for the target letter.
In addition, subjects in the Group A require more gaze fixations to identify the target letter than subjects in the Group B. This may be explained by the restructuring of cognitive activity as a result of switching from one type of activity (involuntary modeling of the perception of the observed character) to another type of activity (voluntary identification of the target letter). Thus, the Group A subjects, unlike the Group B subjects, are experiencing an interference effect: the conscious task of searching for the target letter conflicts (interferes) with the automatized process of analyzing the object/element of the situation that is in the focus of the character’s attention. The subjects need to inhibit the automatic process of selecting this object to perform the task of searching for the target letter [Resnick, 1987].
Furthermore, we assumed that the above-described interference effect is only present when the behavioral reactions of the people being observed are successfully understood, and that this effect will be absent when it is misunderstood.
In order to verify this assumption, experiment 2 was performed.
Experiment 2
Participants. The study involved 34 paranoid schizophrenia patients without intellectual disability aged from 19 to 42 years (mean age 30.2 years) being under treatment in the City Psychiatric Hospital №6 (Saint-Petersburg). The disease duration ranged from 1 to 11 years and averaged 4.5 years. All the patients with schizophrenia at the moment of the research were in the state of remission and did not manifest any signs of acute psychotic condition.
Procedure. The experimental procedure and stimulus material were similar to those used in the Experiment 1, when examining subjects of the Group A.
Results and Discussion
The verbal responses analysis had revealed that, unlike healthy individuals, patients with schizophrenia demonstrated considerable difficulties in understanding characters’ behavior. The data correspond with the multiple studies [Bora, 2009; Driver, 1999; Tomasello, 2014]. These difficulties manifested themselves in erroneous explanations of the characters’ emotional reactions at the end of the videos (e.g., after viewing the video 1, the patient said: “the person watched with interest what was being advertised there from the stage”, etc.). The percentage of the patients who understood the characters’ behavior was: for the video 1 — 44.1% (15 people), 2 — 67.6% (23 people), 3 — 47.0% (16 people), 4 — 41.2% (14 people).
The patients have been divided into 2 groups by the analysis of the responses for each video: persons who understood and did not understand the characters’ behavior.
The one-way analysis of variance was used for the letter detection time parameter. It was shown that patients who did not understand the characters’ behavior took significantly less time to identify the target letter than patients who understood it in the frames after the video 1 (F (1.89) = 16.1; p<0.001), 2 (F (1.89) = 19.5; p<0.05), 3 (F (1.89) = 9.1, p<0.01) and 4 (F (1.89) = 7.5, p<0.05) (Fig. 5). A comparison of letter detection time parameters between patients who did not understand the videos and healthy individuals in the Group A (see Exp.1 results) demonstrated that these patients performed significantly faster in searching for the target letter after each video (F (1.9) = 8.1; p<0.05), (Fig. 6). As shown in Fig. 5, patients who understood characters’ behavior were slower than healthy subjects in identifying the target letter in all the videos. This fact was associated with the phenomena of psychomotor retardation due to the medications taken, decreased level of activation, etc.
The parameters of eye-movement activity of patients who understood and did not understand characters’ behavior while performing the task of searching for the target letter had been analyzed.
Statistical analysis had revealed that patients who did not understand the characters’ behavior significantly less frequently fixed their gaze on the object that caused the character’s emotional reaction than patients who did understand it: in the video 1 (F (1,82) = 23.8; p<0.001), 2 (F (1.82) = 14.5; p<0.001), 3 (F (1.82) = 7.1, p<0.001) and 4 (F (1.82) = 18.5, p<0.001). The mean fixation count on the object in patients who did not understand the characters’ behavior and in patients who understood it are respectively: for the video 1 — 1.2±0.54 and 4.43±0.60; 2 — 1.45±0.78 and 4.76±0.51; 3 — 2.77±0.69 and 5.18±0.74; 4 — 2.38±0.65 and 6.4±0.77. The percentage of patients who understood and did not understand the characters’ behavior and made gaze fixations on the object that caused the characters’ emotional reaction for each video, is presented in fig. 6. As shown, the fixations on the given object for the frames of the video 1 were made by 93.3% of the patients who have understood the video, and 60% of the patients who have not understood it; 2 — 96% and 72.7%; 3 — 100% and 70.6%; 4 — 100% and 60%, respectively.
The one-factor ANOVA had showed that patients who did not understand the character’s behavior spent significantly less time focally analyzing the object that caused the characters’ emotional reactions compared to patients who did understand it: for the video 1 (F (1.82) = 17.6; p<0.001), 2 (F (1.82) = 19.2; p<0.001), 3 (F (1.82) = 3.7, p<0.01), and 4 (F (1.82) = 15.8, p<0.001) (Fig. 7).
The results of the experiment had shown that patients with schizophrenia who understood the character’s behavior, as well as healthy individuals, automatically identify and analyze the objects/elements of the situation perceived by the character and reasoning his emotional reaction and only after that perform the task of searching for the target letter. Whereas patients who did not understand the character’s behavior did not identify and analyze the aforementioned objects/elements of the situation. As a result, they had no difficulty in performing the task of searching for the target letter and performed that task more successfully than healthy individuals and patients who have understood character’s behavior. Thus, these patients had no effect of interference of the task of searching for the target letter with the automated process of analyzing the object that caused the characters’ emotional reaction.
General Discussion
The co-operative mode of cognitive activity organization is activated when we observe another person or engage in a joint activity together with him/her. The necessary condition for the activation of this mode is the presence of a “framework for cooperation” — a “joint project” [Walther, 2006], which we temporarily share with the other individual. In our study the formation of such a “project” occurs through the development and concretization of the behavioral conventional scenario of the observed character by the observer: on the one hand, the observer identifies objects and events that are significant for the “project” and, on the other hand, monitors how these objects and events are perceived by the observed character. The integration of the results of the other person’s cognitive activity into their own cognitive activity allows observers to go beyond their perception [27] and contribute to the “joint project”: to complete the results of the other person’s perceptual activity with the results of their own perceptual activity (for example, to identify objects and events relevant to the “project”, but not yet perceived by the other person).
The original experimental procedure was used to show for the first time that the integration described above has an automatic, involuntary character. These findings are corresponding to C. Goodwin’s theory of co-operative activity, according to which human actions are co-operative if a person builds them by performing systematic transformative operations with the material provided to the public space by another participant in the situation (linguistic expressions, gaze direction, facial expression, etc.) [Goodwin, 2013]. In our study, the character’s emotional reaction, actualized at the end of the video was such a material. The observers involuntarily picked up the results of the cognitive activity of the observed character and realized their own perceptual activity on its basis.
It has been found that patients with schizophrenia demonstrate a deficit in integrating the results of another person’s cognitive activity into their own cognitive activity, which leads to disturbances in understanding situations of social interaction. Patients make hypotheses about how participants in the observed situation perceive objects and events, but do not verify these perceptual hypotheses (do not identify and analyze objects and events perceived by the observed people) and, therefore, do not reveal that these hypotheses are incorrect. The received data can be applied in development of the new diagnostics methods of social cognition disorders in schizophrenia, and can be taken into account in development of new psychological correction programs.