Введение
Проблема совместной познавательной деятельности (joint cognitive activity) разрабатывалась в трудах большого количества отечественных и зарубежных исследователей (Л.С. Выготский, Б.Ф. Ломов, В.В. Рубцов, А.Н. Леонтьев, Дж. Верч и др.). Как указывает Дж. Верч, высокая актуальность данной проблемы объясняется двумя обстоятельствами: во-первых, ключевым значением совместной деятельности для развития познавательных функций в онтогенезе; во-вторых, экологической валидностью — большинство когнитивных задач мы выполняем не изолированно, а в сотрудничестве с другими людьми [24]. Согласно Л.Б. Ресник, вне лаборатории и школы познание почти всегда совместно [Shepherd, 2010]. Б.Ф. Ломов в своих трудах отдельно подчеркивает высокую значимость изучения познавательных функций в рамках совместной деятельности, поскольку именно в ней данные функции раскрываются наиболее полно [Рычкова, 2014].
Многие исследователи делают акцент на том, что познавательная активность человека имеет фундаментально социальную природу (Л.С. Выготский, М. Томаселло и др.). Этот тезис часто понимается так, что высшие психические функции формируются на определенной ступени развития ребенка в ходе сотрудничества со взрослым [Выготский, 1984]. Однако некоторые исследователи указывают, что и у взрослых людей познание носит социально опосредованный (ко-оперативный) характер, т. е. осуществляется через другого человека [12; 21; 22].
В терминологии теории ко-оперативной деятельности (co-operative action) Ч. Гудвина, реализуя какое-либо действие, индивид предоставляет в публичное пространство (public space) организующие это действие семиотические ресурсы (semiotic resources) или материалы. Участники совместной деятельности выборочно используют эти ресурсы для построения своих собственных действий, т. е. включают структуру действий других людей во внутреннюю организацию своей собственной деятельности [Goodwin, 2013].
Иными словами, в процессе совместной деятельности индивиды практически мгновенно интегрируют результаты познавательной деятельности другого человека в свою собственную познавательную деятельность. Такая склонность к интеграции когниций с другим человеком требует определенных функций, одна из которых — тенденция подхватывать результаты его когнитивной активности. Это подхватывание касается (1) схематического (концептуального) восприятия, имеющегося у другого человека; (2) языковых конструкций; (3) жестов и структуры действий [Hanks, 2000].
Одним из примеров интеграции когниций с другим человеком является пример синтаксического прайминга Ч. Гудвина [Goodwin, 2013]. Тони говорит Чопперу: «Почему бы тебе не уйти из моего двора?» («Why don’t you get out my yard?»), на что Чоппер отвечает: «Почему бы тебе не заставить меня уйти из этого двора?» («Why don’t you make me get out the yard?»). Данный разговор демонстрирует, как Чоппер подхватывает лексическую конструкцию Тони и включает ее в собственный ответ. Он выстраивает свое действие не с нуля, а посредством выполнения операций с материалом, предоставленным другим человеком. Во-первых, он раскладывает на две части языковую структуру, предоставленную Тони. Во-вторых, он добавляет в эту структуру свой материал («заставить меня»), создавая принципиально новое действие.
Еще одним примером интеграции когниций с другим человеком является процесс отслеживания направления его взгляда (феномен «gaze following»). В ряде исследований было показано, что этот процесс носит непроизвольный, автоматический характер [Goodwin, 2017; Sprong, 2007]. Если мы видим человека, смотрящего влево, то непроизвольно ориентируем внимание в том же направлении. Этот факт был установлен во многих экспериментах [Friesen, 1998; Goodwin, 2017].
Однако феномен «gaze following» является частью более сложного процесса — моделирования перцептивной деятельности другого индивида [Зотов, 2015]. Приведем пример. Если наблюдатель видит человека, который вдруг поднимает обе руки вверх, то понимает, что тот воспринимает ситуацию в рамках сценария «угроза огнестрельным оружием». Он смотрит в том же направлении, что и наблюдаемый человек, и пытается найти объект, подпадающий под категорию «нацеленное оружие». Другими словами, наблюдатель пытается смоделировать перцептивную деятельность этого человека. Он интегрирует результаты его перцептивной активности (человек увидел нацеленное оружие) в свою собственную перцептивную деятельность (выявляет объект, подпадающий под соответствующую категорию). Процесс такого моделирования требует сложных операций нисходящей («top-down») категоризации (от общей категории к конкретному объекту), а отслеживание направления взгляда другого индивида является одной из составляющих этого сложного процесса [Андрианова, 2017].
Однако остаются открытыми вопросы: будет ли наблюдатель осуществлять интеграцию результатов перцептивной активности наблюдаемого индивида в свою собственную перцептивную активность, если у него не будет информации о направлении взгляда этого индивида, и о том, что тот видит, наблюдатель сможет заключить только по его поведению и мимике? Будет ли он в такой ситуации фиксировать внимание на объектах, соответствующих категориальному восприятию наблюдаемого индивида? Является ли такая интеграция, обеспечиваемая нисходящей категоризацией, автоматическим, непроизвольным процессом или его можно сознательно контролировать? С целью ответа на эти вопросы были проведены два эксперимента.
Эксперимент 1
Испытуемые. В исследовании приняли участие 70 здоровых лиц в возрасте от 19 до 23 лет (средний возраст — 20,1 лет), которые случайным образом были разделены на группу А (35 чел.) и группу Б (35 чел.).
Процедура. В соответствии с инструкцией испытуемые группы А просматривали видеоизображения «немых» социальных сцен длительностью от 65 до 124 с. В заключительной части каждого видеосюжета крупным планом была показана эмоциональная реакция персонажа (испуг, удивление и т. д.), свидетельствующая о том, что он воспринял объект определенной категории (что-то страшное и т. д.). После демонстрации эмоциональной реакции персонажа видеосюжет неожиданно прерывался и испытуемые должны были перевести взгляд на фиксационный крест на сером фоне (0,5 с), а затем выполнить задачу поиска целевой буквы. Данная задача состояла в следующем. После фиксационного креста в течение 5 с. предъявлялась последовательность кадров видеосюжета, ранее не виденных испытуемыми, с перспективы персонажа показывающих то, что он увидел. На этих кадрах присутствовали (1) крупная и визуально заметная буква «О» или «Х» и (2) относительно небольшой и малозаметный объект, вызвавший эмоциональную реакцию персонажа и находящийся в фокусе его внимания. В инструкции говорилось, что основная задача испытуемых — как можно быстрее найти и идентифицировать целевую букву («О» или «Х») и назвать ее вслух. Лишь после этого они могут рассматривать объекты на кадрах видеоряда, в том числе объект, вызвавший эмоцию персонажа. По окончании каждой пробы испытуемых просили описать содержание просмотренного видеосюжета и объяснить поведенческую реакцию персонажа.
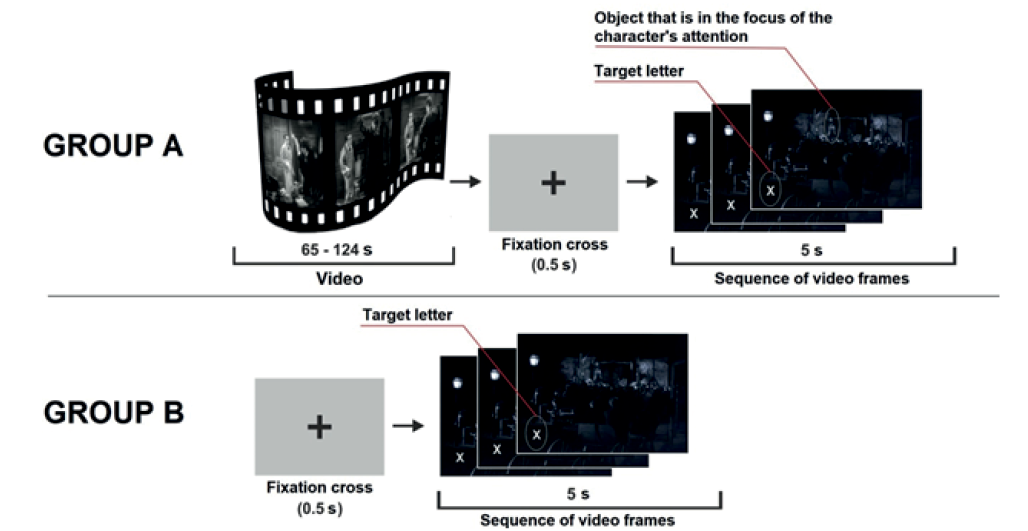
Рис. 1. Процедура эксперимента
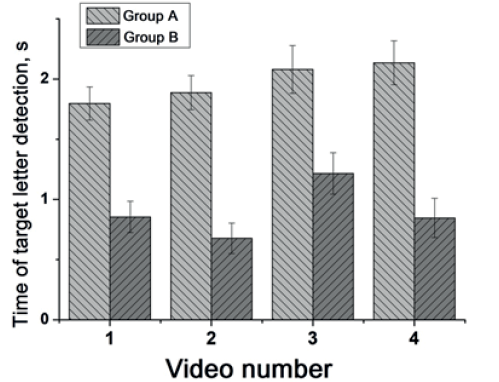
Рис. 2. Среднее время обнаружения целевой буквы у испытуемых групп А и Б для каждого видеосюжета
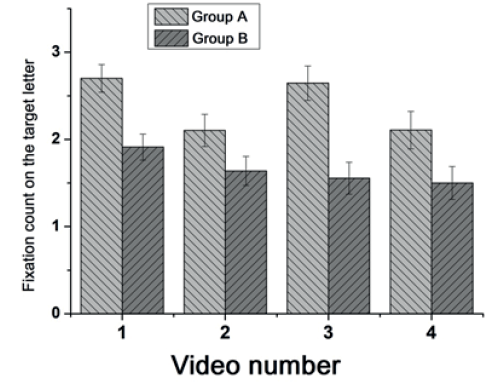
Рис. 3. Среднее количество фиксаций на целевой букве у испытуемых групп А и Б для каждого видеосюжета
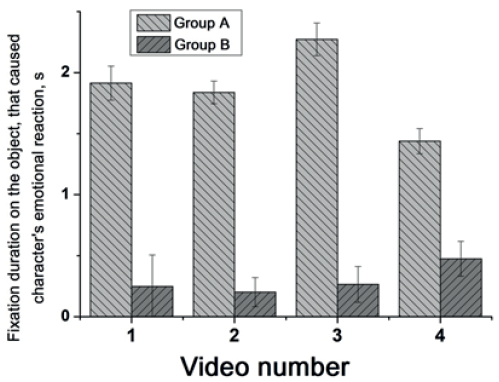
Рис. 4. Суммарная длительность фиксаций взгляда на области объекта, вызвавшего эмоциональную реакцию персонажа, у испытуемых групп А и Б для каждого видеосюжета
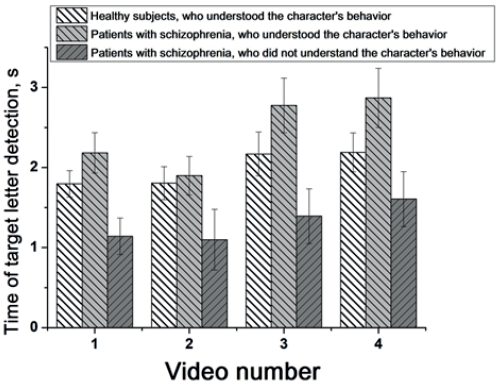
Рис. 5. Среднее время обнаружения целевой буквы у пациентов, понявших и не понявших поведение персонажа, и здоровых лиц группы А для каждого видеосюжета
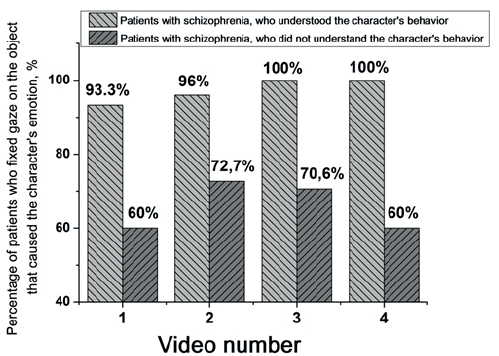
Рис. 6. Доля понявших и не понявших поведение персонажа пациентов, зафиксировавших взгляд на объекте, вызвавшем эмоциональную реакцию персонажа, для каждого видеосюжета
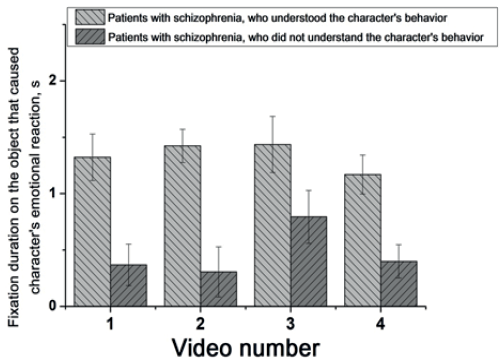
Рис. 7. Суммарная длительность фиксаций взгляда на области объекта, вызвавшего эмоциональную реакцию у персонажа, у пациентов, понявших и не понявших поведение персонажа, для каждого видеосюжета
Таким образом, вышеописанная экспериментальная процедура моделировала ситуацию «когнитивного конфликта». Мы предположили, что задача поиска целевой буквы будет конфликтовать (интерферировать) с поиском объектов, вызвавших эмоциональную реакцию персонажа.
Испытуемые группы Б выполняли такую же экспериментальную процедуру, за исключением того, что им не демонстрировались видеофрагменты. Каждая проба начиналась с демонстрации фиксационного креста на сером фоне (0,5 с), после чего испытуемым предъявлялись последовательности кадров видеосюжета, на которых они искали целевые буквы (рис. 1).
Оборудование и стимульный материал. Видеоизображения социальных ситуаций предъявлялись на 19-дюймовом цветном ЖК-мониторе с разрешением 1280×1024 точек. Расстояние от экрана до глаз испытуемого составляло 60 см. Угловые размеры предъявляемых видеофрагментов и кадров сцен составляли 25×18°. Запись движений глаз осуществлялась при помощи системы бесконтактной регистрации движений глаз Tobii X120 (Tobii Technology, Швеция) с частотой 120 Гц (пространственное разрешение 0,3°). Перед выполнением каждой пробы испытуемый проходил процедуру калибровки. Записи движений глаз с низкими значениями валидности были исключены из анализа.
Исследование проводилось на материале четырех видеоизображений социальных ситуаций из немых черно-белых художественных фильмов «Застенчивый» (США, 1924), «Младший брат» (США, 1927) и «Гонщик» (США, 1928), отобранных с помощью экспертных оценок. Для примера представим описание двух видеоизображений.
Видеосюжет 1 (фильм «Младший брат»). Сын шерифа, по указанию отца, пытается остановить уличное представление, которое проводят мошенники. Мошенники обманом надевают на него наручники и подвешивают над сценой, выставляя на посмешище перед публикой. Шериф проходит недалеко от места, где проходит представление. Крупным планом показано, как он внезапно останавливается, смотрит вперед и нахмуривает брови. То, что он видит, скрыто от зрителя. После этого следует фиксационный крест. Затем следуют кадры, на которых издалека показана сцена и подвешенный над ней сын шерифа.
Видеосюжет 2 (фильм «Гонщик»). Таксист берет чемоданы пассажира и идет к такси. Он видит, как его такси вдруг трогается с места и уезжает. Он бросает чемоданы пассажира на тротуар и бежит за такси. Крупным планом показано удивленное и горестное выражение на лице пассажира, смотрящего на тротуар. То, что он видит, скрыто от зрителя. Затем следует фиксационный крест. После этого следуют кадры, на которых показан лежащий на тротуаре чемодан и вытекающая из него тонкая струйка жидкости.
На всех кадрах, использованных в задаче поиска целевой буквы, объекты, вызвавшие эмоциональные реакции персонажей, обладали небольшим размером (до 3,0°) и низким уровнем «визуальной яркости». Целевая буква также обладала небольшим размером (2,0°), но высоким уровнем «визуальной яркости». Оценка «визуальной яркости» областей кадров проводилась с помощью инструментария «Saliency Toolbox» [Wertsch, 1989].
Регистрируемые показатели. Движения глаз испытуемых регистрировались в течение просмотра каждого видеосюжета и при выполнении последующей задачи на поиск целевой буквы. Распознание зрительных фиксаций и саккад осуществлялось с помощью алгоритма «I-VT» [Miyake, 2000]. При помощи программного обеспечения «Tobii Studio 3.2.1» осуществлялся расчет количества и длительности фиксаций взгляда испытуемых на так называемых динамических областях интереса (Dynamic AOIs), т. е. областях, перемещающихся в точном соответствии с движением объектов (предметов, лиц персонажей и т. д.) на видеоизображении.
Обработка данных производилась с помощью методов однофакторного и многофакторного дисперсионного анализа с использованием пакета SPSS v.23.
Результаты и их обсуждение. Был проведен анализ вербальных ответов испытуемых для каждого видеосюжета. Установлено, что 100% здоровых лиц дают успешные объяснения поведения персонажей и верно идентифицируют объекты, находящиеся в фокусе их внимания.
Для показателя времени обнаружения буквы был проведен однофакторный дисперсионный анализ ANOVA. Установлено, что испытуемые, наблюдавшие за поведением персонажа (группа А), по сравнению с испытуемыми, его не наблюдавшими (группа Б), тратят достоверно больше времени на обнаружение целевой буквы в кадрах после видеосюжета 1 (F (2,12) = 24,7; p<0,001), 2 (F (2,12) = 40,7; p<0,001), 3 (F (2,12) = 10,8; p<0,05) и 4 (F (2,12) = 27,7; p<0,001) (рис. 2).
Для понимания причин указанных различий был проведен сравнительный анализ параметров глазодвигательной активности у двух групп испытуемых при выполнении задачи на поиск целевой буквы. Однофакторный дисперсионный анализ ANOVA показал, что испытуемым группы А, по сравнению с испытуемыми группы Б, требуется большее количество фиксаций взгляда на целевой букве для ее идентификации в кадрах после видеосюжета 1 (F (2,14) = 13,1; p<0,001), 2 (F (2,14) = 3,5; p<0,05), 3 (F (2,14) = 16,5; p<0,01) и 4 (F (2,14) = 3,6; p<0,05) (рис. 3).
Установлено, что, несмотря на инструкцию, многие испытуемые группы А сначала фиксируют взгляд на объекте, вызвавшем эмоцию персонажа, и лишь потом переводят взгляд на целевую букву. Доля таких испытуемых составила для видеосюжета 1 — 61%, 2 — 56%, 3 —64%, 4 — 53%.
Помимо этого, испытуемые группы А по сравнению с испытуемыми группы Б затрачивают достоверно больше времени на визуальный анализ объекта, вызвавшего эмоциональную реакцию персонажа, в кадрах после видеосюжета 1 (F (2,14) = 32,2; p <0,001), 2 (F (2,14) = 117,7; p<0,001), 3 (F (2,14) = 102,7; p <0,001) и 4 (F (2,14) = 35,4; p <0,001) (рис. 4).
Результаты эксперимента показали, что здоровые лица, наблюдавшие поведение персонажа, в отличие от здоровых лиц, его не наблюдавших, подхватывают результаты перцептивной активности персонажа (например, «шериф заметил подвешенного сына») и автоматически интегрируют их в собственную перцептивную активность даже при отсутствии информации о направлении его взгляда. Иными словами, они непроизвольно выделяют и анализируют объекты/элементы ситуации, воспринятые персонажем и обосновывающие его эмоциональную реакцию, и лишь после этого выполняют первоочередную задачу поиска целевой буквы.
Проанализируем процесс такой интеграции на примере видеосюжета 1. Из смыслового контекста испытуемые группы А знают, что шериф отправил своего сына остановить уличное представление. Они видят, что мошенники подвешивают сына над сценой и продолжают представление, затем они наблюдают эмоциональную реакцию прогуливающегося поблизости шерифа (он резко останавливается и нахмуривает брови). Эта реакция является так называемым «материальным якорем» [Komogortsev, 2010], позволяющим идентифицировать, что именно в данный момент воспринимает персонаж. В терминах Ч. Гудвина, она представляет собой материал, предоставленный персонажем в публичное пространство [Goodwin, 2013]. Из оценки реакции шерифа наблюдатели выдвигают предположение о том, что он воспринимает или «определяет» наблюдаемую им ситуацию (define the situation) [Гофман, 2003] как «возмутительную». Далее испытуемые группы А, несмотря на неоднократные указания экспериментаторов о первоочередности поиска буквы, непроизвольно моделируют перцептивную активность шерифа, выделяя и анализируя элемент ситуации («подвешенный сын шерифа»), который находится в фокусе его внимания и поддерживает у шерифа восприятие ситуации как «возмутительной» для него. Соответственно, испытуемые группы А, по сравнению с испытуемыми группы Б, уделяют фокальному анализу области данного элемента больше времени и дольше ищут целевую букву.
Помимо этого, испытуемым группы А, по сравнению с испытуемыми группы Б, требуется большее количество фиксаций взгляда для идентификации целевой буквы. Это может объясняться перестройкой познавательной деятельности в результате переключения с одного вида активности (непроизвольного моделирования восприятия наблюдаемого персонажа) на другой вид активности (произвольную идентификацию целевой буквы). Таким образом, у испытуемых группы А, в отличие от испытуемых группы Б, отмечается эффект интерференции: сознательная задача поиска целевой буквы конфликтует (интерферирует) с автоматизированным процессом анализа объекта/элемента ситуации, находящегося в фокусе внимания персонажа. Для выполнения задачи поиска целевой буквы испытуемым необходимо затормозить автоматический процесс выделения данного объекта [Resnick, 1987].
Далее мы предположили, что вышеописанный эффект интерференции присутствует только в случае успешного понимания поведенческих реакций наблюдаемых людей, а при условии его ошибочного понимания этот эффект будет отсутствовать.
С целью проверки этого предположения был проведен эксперимент 2.
Эксперимент 2
Испытуемые. В исследовании участвовали 34 интеллектуально сохранных больных параноидной шизофренией в возрасте от 19 до 42 лет (средний возраст — 30,2 лет), проходивших лечение в СПб ГКУЗ «Городская психиатрическая больница № 6». Длительность заболевания находилась в пределах от 1 года до 11 лет и в среднем составила 4,5 лет. Все больные шизофренией на момент обследования находились в состоянии ремиссии и не обнаруживали признаков острого психотического состояния.
Процедура. Экспериментальная процедура и стимульный материал были идентичны тем, которые применялись в эксперименте № 1 при обследовании испытуемых группы А.
Результаты и их обсуждение.
Анализ вербальных ответов показал, что, в отличие от здоровых лиц, больные шизофренией обнаруживают выраженные трудности понимания поведения персонажей, что согласуется с данными многочисленных исследований [8; 9; 20]. Эти трудности проявляются в ошибочных объяснениях эмоциональных реакций персонажей в конце видеосюжетов (например, после просмотра видеосюжета 1 больная говорит, что «человек посмотрел с интересом, что же там рекламируют со сцены» и т. д.). Доля пациентов, понявших поведение персонажей, составляет: для видеосюжета 1 — 44,1% (15 чел.), 2 — 67,6% (23 чел.), 3 — 47,0% (16 чел.), 4 — 41,2% (14 чел.).
По результатам анализа ответов для каждого видеосюжета пациенты были разделены на лиц, понявших и не понявших поведение персонажей.
Для показателя времени обнаружения буквы был проведен однофакторный дисперсионный анализ ANOVA. Установлено, что пациенты, не понявшие поведение персонажей, затрачивают достоверно меньше времени на обнаружение целевой буквы, чем пациенты, его понявшие, в кадрах после видеосюжета 1 (F (1,89) = 16,1; p<0,001), 2 (F (1,89) = 19,5; p<0,05), 3 (F (1,89) = 9,1; p<0,01) и 4 (F (1,89) = 7,5; p<0,05) (рис. 5). Сопоставление показателей времени обнаружения буквы у пациентов, не понявших видеосюжеты, и у здоровых лиц группы А (см. результаты эксперимента 1) свидетельствует, что эти больные достоверно быстрее справляются с задачей поиска целевой буквы после каждого видеосюжета (F (1,9) = 8,1; p<0,05) (рис. 6). Как видно из рис. 5, пациенты, понявшие поведение персонажей, медленнее, чем здоровые испытуемые, идентифицируют целевую букву во всех видеосюжетах, что связано с явлениями психомоторной заторможенности вследствие принимаемого медикаментозного лечения, сниженного уровня активации и пр.
Были проанализированы параметры глазодвигательной активности пациентов, понявших и не понявших поведение персонажей, при выполнении задачи поиска целевой буквы.
Статистический анализ показал, что пациенты, не понявшие поведение персонажей, достоверно реже, чем пациенты, его понявшие, фиксируют взгляд на объекте, вызвавшем эмоциональную реакцию у персонажа: в кадрах видеосюжета 1 (F (1,82) = 23,8; p<0,001), 2 (F (1,82) = 14,5; p<0,001), 3 (F (1,82) = 7,1; p<0,001) и 4 (F (1,82) = 18,5; p<0,001). Среднее количество фиксаций на области этого объекта у пациентов, не понявших поведение персонажей, и пациентов, его понявших, составляет соответственно: для видеосюжета 1 — 1,2±0,54 и 4,43±0,60; 2 — 1,45±0,78 и 4,76±0,51; 3 — 2,77±0,69 и 5,18±0,74; 4 — 2,38±0,65 и 6,4±0,77. На рис. 6 представлена доля пациентов, понявших и не понявших поведение персонажей, совершивших фиксации взгляда на объекте, вызвавшем эмоциональную реакцию у персонажа, для каждого видеосюжета. Как видно, фиксации на данном объекте для кадров видеосюжета 1 совершают 93,3% пациентов, понявших видеосюжет, и 60% пациентов, его не понявших; 2 — 96% и 72,7%; 3 — 100% и 70,6%; 4 — 100% и 60% соответственно.
Также однофакторный дисперсионный анализ ANOVA показал, что пациенты, не понявшие поведение персонажей, по сравнению с пациентами, его понявшими, затрачивают достоверно меньше времени на фокальный анализ объекта, вызвавшего эмоциональную реакцию у персонажа: для кадров видеосюжета 1 (F (1,82) = 17,6; p<0,001), 2 (F (1,82) = 19,2; p<0,001), 3 (F (1,82) = 3,7; p<0,01) и 4 (F (1,82) = 15,8; p<0,001) (рис. 7).
Результаты эксперимента показали, что больные шизофренией, понявшие поведение персонажа, как и здоровые лица, автоматически выделяют и анализируют объекты/элементы ситуации, воспринятые персонажем и обосновывающие его эмоциональную реакцию, и только после этого осуществляют задачу поиска целевой буквы. Тогда как больные, не понявшие поведение персонажа, не выделяют и не анализируют вышеуказанные объекты/элементы ситуации. В результате они не испытывают трудностей при выполнении задачи поиска целевой буквы и справляются с данной задачей успешнее, чем больные, понявшие поведение персонажей, и здоровые лица. Таким образом, у данных пациентов отсутствует эффект интерференции задачи поиска целевой буквы с автоматизированным процессом анализа объекта, вызвавшего эмоциональную реакцию у персонажа.
Общее обсуждение результатов
Ко-оперативный режим организации познавательной деятельности активируется тогда, когда мы наблюдаем за другим человеком или участвуем вместе с ним в совместной деятельности. Необходимым условием для активации данного режима является наличие «основы для кооперации» — «совместного проекта» [Walther, 2006], который мы временно разделяем с другим индивидом. В нашем исследовании формирование такого «проекта» происходит за счет развития и конкретизации конвенционального сценария поведения наблюдаемого персонажа наблюдателем: с одной стороны, наблюдатель выделяет объекты и события, значимые для «проекта», а с другой стороны, осуществляет мониторинг того, как эти объекты и события воспринимаются наблюдаемым персонажем. Интеграция результатов когнитивной активности другого человека в собственную когнитивную активность позволяет наблюдателям выйти за пределы своего восприятия [27] и внести вклад в «совместный проект»: дополнить результаты перцептивной активности другого человека результатами собственной перцептивной активности (например, выявить объекты и события, релевантные «проекту», но пока еще не воспринятые другим человеком).
С использованием оригинальной экспериментальной процедуры впервые было показано, что описанная выше интеграция носит автоматический, непроизвольный характер. Полученные результаты соответствуют положениям теории ко-оперативной деятельности Ч. Гудвина о том, что действия человека ко-оперативны в том случае, если он выстраивает их посредством выполнения систематических преобразующих операций с материалом, предоставленным другим участником ситуации в публичное пространство (языковыми выражениями, направлением взгляда, лицевой экспрессией и др.) [Goodwin, 2013]. В нашем исследовании в качестве такого материала выступала эмоциональная реакция персонажа, реализуемая в конце видеосюжета, отталкиваясь от которой, наблюдатели непроизвольно подхватывали результаты когнитивной активности наблюдаемого персонажа и реализовывали собственную перцептивную активность.
Было выявлено, что у больных шизофренией отмечается дефицит интеграции результатов когнитивной активности другого человека в собственную когнитивную активность, что приводит к нарушениям понимания ситуаций социального взаимодействия. Больные выдвигают гипотезы о том, как участники наблюдаемой ситуации воспринимают объекты и события, но не подтверждают данные перцептивные гипотезы (не выделяют и не анализируют объекты и события, воспринятые наблюдаемыми людьми) и, соответственно, не выявляют то, что эти гипотезы оказываются ошибочными. Полученные данные могут применяться в разработке новых методов диагностики нарушений социального познания при шизофрении, а также учитываться при разработке новых психокоррекционных программ.