Введение
Основной целью данного проекта является повышение культурного уровня текстовых писем в диалоговых переписках. Зачастую, люди не соблюдают моральные и этические нормы в цифровом пространстве, а иногда сами рвутся оскорбить собеседника в переписке. Для фильтрации подобного контента предназначены классификаторы токсичных сообщений, которые удаляют обнаруженные подозрительные сообщения. Такие системы имеют важный недостаток в том, что обнаруженное сообщение удаляется полностью, даже если в нем было лишь одно токсичное слово. Данный подход является слишком радикальным, поскольку при его неправильной классификации и отнесения к токсичному классу сообщение удаляется полностью и информация, передаваемая в нем, теряется.
Для использования разрабатываемой модели в диалоговых системах с потенциально высоким трафиком система с самого начала задумывалась как надежная, масштабируемая, поддерживаемая и адаптивная. Для выполнения поставленных требований необходимо предусмотреть мониторинг и использовать соответствующие технологии его реализующие. Чтобы упростить разработку и больше сосредоточиться на реализуемом продукте, было принято решение использовать услуги облачного провайдера для развертывания системы на его платформе.
Все вышесказанное можно перевести в задачу тегирования или в задачу классификации токенов сообщения. Но в отличии от обычной задачи классификации сообщения целиком, создаваемая система должна восстановить из полученных токенов и предсказаний исходное сообщение и скрыть только оскорбительные слова. А слово может быть представлено несколькими токенами, и один токен может включать несколько слов.
Обучающие данные
Используемым в настоящей работе датасетом является набор русскоязычных твитов [Рубцова, 2012]. Разметку было решено получить полуавтоматическим способом через более слабые модели, использующие методы ближайшего соседа и логистической регрессии. Первоначально был составлен словарь из токсичных слов, затем на малой подвыборке были получены метки слов в зависимости от нахождения в словаре. На полученном сэмпле обучались алгоритмы целевой модели, и затем они применялись к неразмеченным данным. Итеративно процесс повторялся несколько раз, расширяя словарь и заново переобучая базовые модели.
Поскольку данные, поступающие на вход системы, будут направлены на ее поломку, требуется всегда выдавать эмбеддинги для новых слов. Для решения этой проблемы была выбрана модель, основанная на BPE-кодировании, основанная на представлении эмбеддинга слова как суммы эмбеддингов n-грамм его букв. Подобной моделью можно назвать FastText, который для любого слова может выдать семантически близкое представление.
Модель классификатора
В качестве классификатора были опробованы архитектуры со сверточными, линейными, рекуррентными слоями. Общий вывод, который удалось сделать – чем сложнее архитектура, тем быстрее сеть переобучается и тем больше хороших слов попадают в «токсичный» класс. Например, сложно было отучить модель воспринимать такие слова как «копать», «мазь», «да» как нетоксичные. Архитектура такой системы представлена на рис. 1.
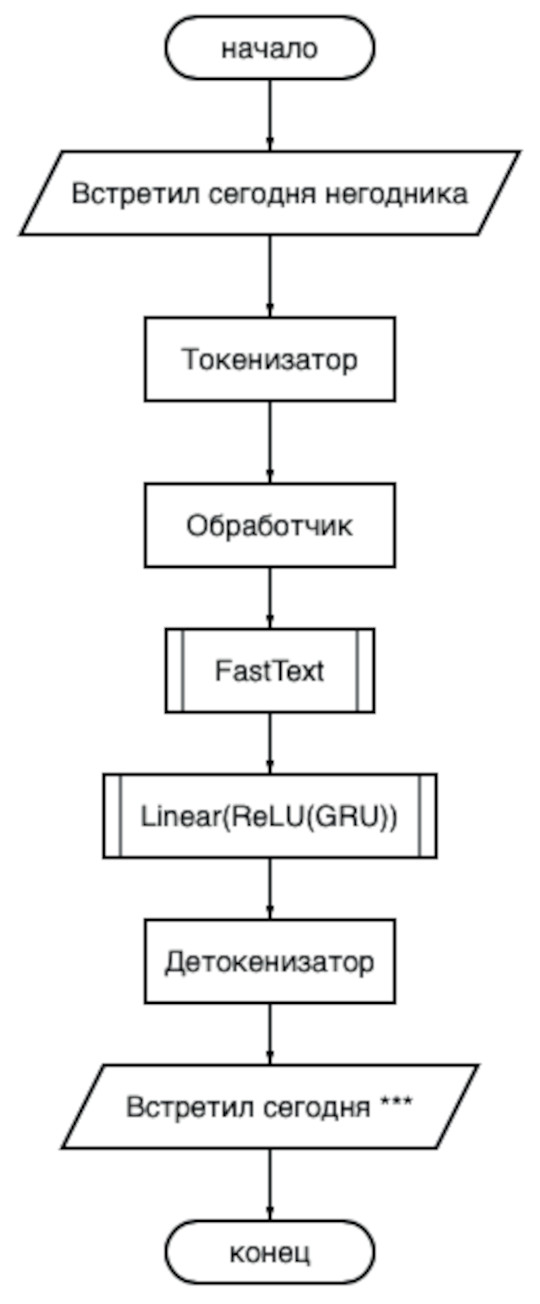
Рис. 1. Архитектура классификатора
На вход подается строка с сообщением, которая разбивается на токены в блоке токенизатора. Затем каждый токен попадает в обработчик, который представляет собой набор правил по очистке и фильтрации ненужных символов, например, удаление смайликов, незначимых спецсимволов, дублирований. Далее каждый токен получает свое представление в FastText блоке, чтобы потом быть обработанным классификатором. Сам классификатор представляет собой нейросеть, состоящую из слоев GRU, функции активации ReLU и линейного слоя на выходе. Получив показатели принадлежности положительному классу, из токенов собирается цензурированное сообщение в блоке детокенизатора.
Для оценки качества классификации выбрана метрика balanced accuracy из-за сильного дисбаланса классов нетоксичных и токсичных токенов. Предпочтение отдано именно этой метрике, поскольку ее значения коррелировали с наглядными результатами работы модели.
Развертывание модели
В качестве облачного провайдера выбран «Яндекс» из-за выгодных квот на предлагаемой им serverless технологии. Аренда виртуальной машины и кластера с базой данных – это недешевое удовольствие для системы на старте ее жизни. Serverless технология – это достаточно молодая область, но крайне перспективная. Ее особенность в том, чтобы предоставить пользователю услугу как сервис. Пользователь не занимается развертыванием системы, ее настройкой и поддержкой. Все это берет на себя провайдер. Пользователь же платит только за непосредственно используемые вычислительные мощности, характеризуемые, например, числом запросов к базе данных, числом вызовов функции, объемом используемого хранилища данных. В отличии от виртуальных хостов такие сервисы активны лишь во время обращения к ним. Все остальное время их ресурсы находятся в общем пуле ресурсов и масштабируются провайдером по мере необходимости.
Для реализации мониторинга за сдвигом распределения данных и таргета нужно где-то эти данные хранить. Как сказано выше, разворачивать полноценный кластер с БД – это дорого. Но нашлась альтернатива в виде serverless YDB, которая предлагала широкие возможности по масштабированию системы и экономила средства пользователя. Простые операции по вставке записей позволили хранить поступающие в модель данные и не терять в скорости ответа. Для аналитики и долгосрочного хранения можно организовать более «прохладное» хранилище, куда переливаются данные не чаще одного раза в час. В построенной системе такой перезаливкой занимается инструмент Data Transfer от Яндекса.
Таким образом, поступающие данные накапливаются в YDB (но нужно не забывать, что установлен лимит по TTL записей в БД - Time ti live) по минимальной стоимости, основной кластер может быть выключен и «поднят» только по мере необходимости перезаливки или непосредственной работы аналитиков.
Достоинства и недостатки
Готовая система тестировалась не только на отложенном наборе данных, но и при реальном диалоговом общении людей. Так удалось выявить некоторые неточности, связанные с ложным определением токсичных слов. Явный пример: «мы уехали отдыхать в город Пиза». Название города расценивается моделью как нечто, подлежащее скрытию. Причины данной ошибки можно назвать две: отсутствие в обучающей выборке употребительных примеров со словом «Пиза» и некачественный эмбеддинг от модели FastText. Первую причину можно устранить, добавив подобные предложения в обучающие данные, чтобы сеть научилась лучше улавливать семантику спорных слов (таких, как «хрен» или «очко», например). Вторая причина связана с применением квантизации, дабы ускорить процесс инференса и уложиться в лимиты провайдера.
Противоположным примером можно назвать сценарий использования редко употребительных или устаревших нецензурных слов, когда системой пропускаются токсичные слова. Такие примеры нетривиально придумать во время диалога, но их можно встретить в специальных словарях для телевидения, которые используют для цензурирования.
Не остались без проверки и наиболее распространенные оскорбления. Обычно, это образованные слова от нескольких типичных матерных корней. Успешно прошли через систему такие примеры как «прихлебатель – это угодливый человек», «из чего сделана похлебка?», «постарайся это не употреблять». Модель достаточно устойчива, несмотря на опечатки и шумовые символы, но существуют разнообразные способы, которые скрывают от реализованной модели истинный смысл. К этим способам можно отнести использование верхнего регистра, транслит, разбиение букв слова пробельными символами или же наоборот, склейка слов без пробелов. Обучение модели быть устойчивой к подобным сценариям является нетривиальной задачей, но для этого можно начать с добавления некоторых простых правил-обработчиков.
Вывод
Результатом работы является программное обеспечение, способное очищать текстовые сообщения от токсичного контента, развернутое на платформе мессенджера «Telegram» в виде бота @toxic_segmenter_bot. Данная площадка выбрана как популярное место общения разных групп общества.
В процессе разработки возникали сложные вопросы, касающиеся дизайна системы, проектных ограничений, развертывания системы. И по мере ответа на каждый из вопросов сложилось понимание того, что человек все равно сможет найти способы обойти систему, будь то картинки, аудио записи, смайлики или монолитный текст. Гонка за идеалом может быть бесконечной. Альтернативой является предложить людям осознанно отказаться от токсичного контента в своей жизни.