Введение
В быстро развивающемся мире технологий построение прогнозов на основе данных с использованием методов машинного обучения приобретает всё большую актуальность. Современных мощностей хватает для того, чтобы эффективно обрабатывать большие объёмы данных, автоматизировать процессы и делегировать машинам задачи, которые ещё не так давно могли быть решены только человеком.;
В данной работе рассматривается задача предсказания рейтинга нового фильма по данным (жанр, длительность и т.д.), известным ещё до его выхода. Такая оценка может быть полезной для различных групп людей и организаций. Например, для инвесторов, которые хотят вложить деньги в производство фильма; для студий и кинокомпаний, разрабатывающих фильмы; для режиссёров, сценаристов и актёров, присматривающих проекты для участия. Не говоря уже о миллионах людей, не связанных с киноиндустрией, но покупающих билеты в кинотеатры, основываясь лишь на собственных ожиданиях, так как реальный рейтинг ещё не успел сформироваться. Иными словами, это мощный фактор, который может иметь вес при принятии очень разнообразных решений.
Задача рассматривается в большом количестве публикаций, многие из которых вышли относительно недавно. Например, в [Баев] описано исследование, в котором предлагается строить прогноз с помощью линейных и метрических методов машинного обучения, а также классической полносвязной нейросети. В [Кирилина] помимо основной задачи прогнозирования кассовых сборов фильмов рассматривается задача прогнозирования пользовательской оценки, которая решается методами Random forest, gradient boosting и k nearest neighbors. Таким образом, можно сделать вывод, что настоящее время задача является достаточно актуальной.
Постановка задачи
В качестве источника данных была выбрана база данных IMDB [IMDB Datasets [https]. Выбор обусловлен тем, что это крупнейшая в мире БД о кинематографе, и рейтинги, представленные в ней, пользуются авторитетом во всём мире. На её основе был сформирован файл со следующими характеристиками, описывающими кинокартину:
titleType – тип/формат (например, фильм, короткометражка, сериал, видео и т. д.);
isAdult – 0: не для взрослых; 1: для взрослых;
startYear – год выпуска;
runtimeMinutes – время в минутах;
genres – список жанров, поставленных в соответствие фильму;
directors – id режиссёра;
(director) primaryProfession – список профессий режисёра;
(director) knownForTitles – список фильмов, за которые режиссёр известен;
writer – id cценариста;
average rating – средневзвешенный рейтинг.
Также в датасете присутствует столбец tconst, содержащий уникальные идентификаторы фильмов.
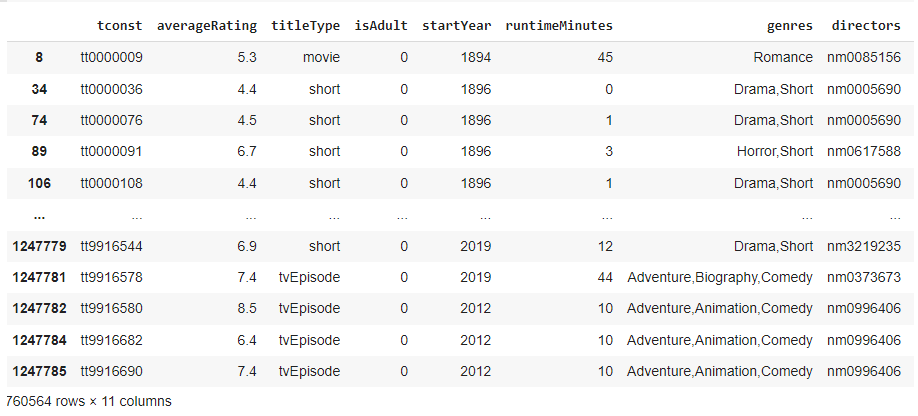
Рис 1. Сведённый датасет (часть 1)
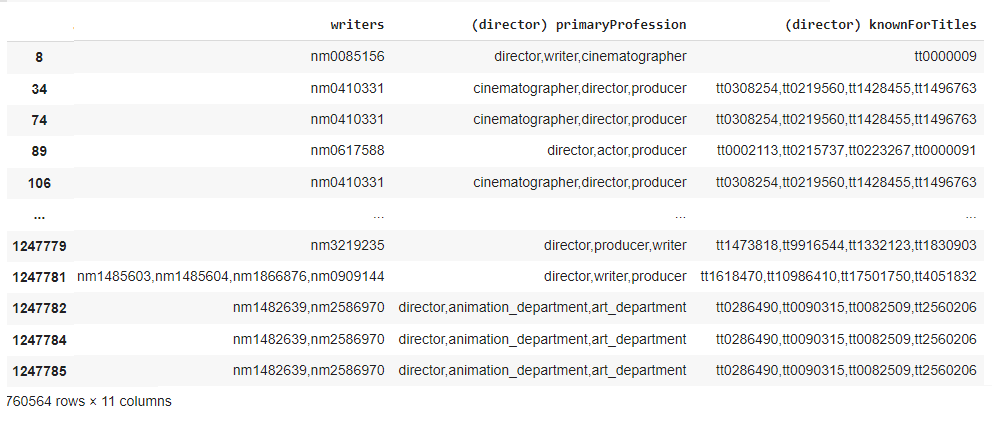
Рис 2. Сведённый датасет (часть 2)
Так как данные регулярно обновляются, зафиксируем дату обращения – 15.11.2022.
Итак, чтобы построить прогноз, нужно решить задачу регрессии, состоящую в построении алгоритма, отображающего множество объектов, описываемых признаками, во множество target-меток. На значения признаков ограничения не накладываются, а значение target-метки может быть любым вещественным числом.
В нашем случае target-меткой будем считать переменную average rating, принимающую значения в отрезке от 0 до 10, а признаками – 9 оставшихся показателей, описывающих фильм. Однако следует отметить, что это число будет меняться в ходе преобразований.
Для нахождения оптимального решения будем строить разные алгоритмы путём обучения стандартных моделей на основе собранных данных, а затем выберем лучший из них.
В качестве функционала качества будем использовать метрику MAE – средний модуль отклонения ответа алгоритма от истинного значения
(1)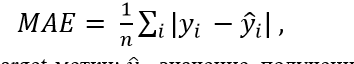
где – истинное значение target-метки; - значение, полученное от алгоритма;
n – число объектов, по которым получен прогноз.
Выбор обусловлен классом решаемой задачи, а также отличной интерпретацией – значение MAE для данной задачи в точности равно баллу, на который в среднем ошибается алгоритм.
Таким образом, лучшим будем считать тот алгоритм, для которого значение MAE на тестовой выборке (части исходного датасета, отведённой для получения прогноза и оценки качества) будет наименьшим.
Для дальнейшей работы будем использовать язык Python, а также вычислительные ресурсы Colab от компании Google [Google Colab [Электронный].
Предобработка Данных
Признаки (тип/формат) и director (id режиссёра) являются категориальными. Признак “titleType” имеет 10 уникальных значений, поэтому для представления в числовом формате применим стандартную технику бинаризации, т.е. для каждого уникального значения сделаем отдельный бинарный столбец, в котором будет стоять 1, если данный тип соответствует фильму и 0, если не соответствует. В результате получим 10 новых признаков.
Признак же содержит в себе 157557 уникальных значений. Создавать бинарные признаки будет слишком затратным с точки зрения памяти действием, поэтому воспользуемся популярным методом и закодируем каждое значение частотой, с которой оно встречается в датасете. Значениями признаков являются массивы строк. Метод кодирования частотой здесь не подходит, т.к. в этом случае одно и то же значение получат только фильмы, полностью совпадающие по спискам жанров, то есть удовлетворяющие очень сильному условию схожести. В других же случаях схожесть будет игнорироваться. Бинаризация же применима, но реализуется немного сложнее. Следует отметить, что признак (director) knownForTitles содержит большое число уникальных значений, поэтому для него придётся ограничиться, например, 500 самыми распространёнными фильмами с целью экономии ресурсов. Проведём соответствующие преобразования, а также удалим признак tconst, который не понадобится нам в дальнейшем. В результате получим новый датасет, состоящий из 358 столбцов. Рис 3. Преобразованный датасет
Другие признаки, а также target-метка являются являются числовыми и не требуют никаких дополнительных преобразований. Следует отметить, что при обучении определённых моделей могут понадобиться дополнительные преобразования датасета.
Обучение моделейРазобьём наш датасет на обучающую и тестовую выборки таким образом, чтобы в тестовую выборку попали самые поздние фильмы (так так подобная ситуация лучше всего моделирует реальный мир, в котором мы будем получать новые объекты из будущего). Для этого нужно отсортировать все объекты по признаку startYear и разделить датасет. После этого обучим модели Linear Regression, kNN, Random Forest, Gradient Boosting. Конечно, речь идёт о версиях, адаптированных под задачу регрессии. Для первых четырёх моделей есть хорошие реализации в библиотеке scikit learn, а для последней будем использовать LGBMRegressor из библиотеки LightGBM и CatBoostRegressor из библиотеки CatBoost, так как они являются более мощными и почти всегда лучше работают на практике. Получим следующие значения MAE на тестовой выборке: 0.958; 1.050; 0.943; 0.947; 0.946. Как видим, результаты не сильно отличаются, но формально Random Forest оказался чуть более точным. Следует отметить, что при плохо подобранных гиперпараметрах показатели могут стать хуже, в данном случае значение 0.943 достигнуто моделью RandomForest при следующей конфигурации:
- max_depth = 61;
- n_estimators = 1750;
- min_samples_split = 3;
- max_features='sqrt'.
Другие гиперпараметры были взяты по умолчанию.
Для демонстрации работы модели возьмём случайный объект и сделаем на нём предсказание:
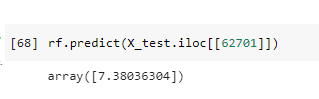
Рис. 4. Получение предсказания
Выведем реальное значение target-метки:
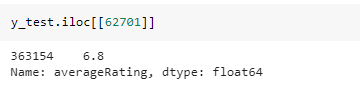
Рис 5. Получение реального значения
Видим, что отклонение составило около 0.5 балла. Посмотрим на описание объекта в первоначальном датасете (т.е. на уровне сведённых сырых данных):
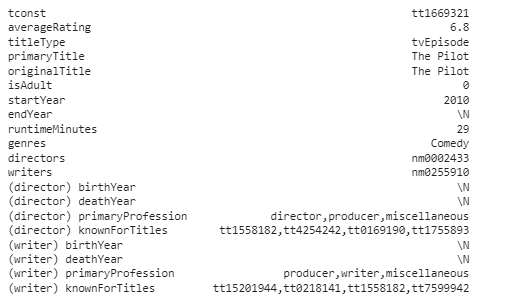
Рис 6. Описание объекта
Видим, что в данном случае речь идёт об одной из серий некоторого комедийного сериала, выпущенной в 2010 году.
Заключение
Таким образом, можно сказать, что методы машинного обучения могут решать поставленную задачу с достаточно высокой точностью в терминах MAE, что открывает большие возможности для прикладного применения. Конечно, требования к метрикам зависят от конкретной задачи, и вполне возможно, что в реальной ситуации полученных значений будет недостаточно. Однако было показано, что подход является достаточно перспективным, также при необходимости его можно дорабатывать с целью повышения точности.