Введение
Обработка естественного языка (NLP) является областью, которая использует вычислительные методы для анализа и синтеза естественного языка и речи. Эта дисциплина пересекается с лингвистикой, изучая слова и языковые конструкции, и тесно взаимодействует с компьютерными науками и искусственным интеллектом.
NLP не только исследует основы языка, но и успешно применяется для разнообразных задач, начиная от поддержки образовательного процесса [1,2] и заканчивая исследованиями в области психиатрии, таких как изучение пациентов с шизофренией [Corcoran, 2020]. Интересно, что NLP также находит применение в неожиданных областях, включая анализ рентгенограмм легочной ткани [Chengyi, 2021].
Благодаря обработке естественного языка открываются уникальные возможности в решении различных задач, включая анализ настроений [Medhat W, Hassan, 2014]. Один из подходов, предложенный в работе [Onan, 2020], использует глубокое обучение для анализа сообщений в социальных сетях с помощью векторных представлений слов (например, fastText, word2vec и GloVe) и сверточных нейронных сетей (CNN).
Другие исследователи [Karthik, 2021] разработали новую систему рекомендаций продуктов, основанную на инновационной логике, которая предсказывает наиболее значимые продукты для онлайн-покупок в реальном времени, учитывая предпочтения клиентов и оценки продуктов. Еще одно исследование [Bose, 2020] показало, что, разделяя отзывы на 8 эмоциональных категорий, можно проанализировать поведение клиентов и улучшить их уровень удовлетворенности. Также проводились исследования с применением сложных архитектур нейронных сетей, таких как BERT [9, 10].
В данной работе мы стремимся заполнить пробел в исследованиях семантического анализа текста на русском языке с использованием современных нейросетевых архитектур. Мы сосредотачиваемся на анализе тональности отзывов об организациях на Яндекс Картах. Наша цель - разработать модель, автоматически классифицирующую отзывы как положительные, отрицательные или нейтральные, и оценить ее эффективность на реальных данных. Мы подготавливаем корпус текстов отзывов, включающий положительные, нейтральные и отрицательные отзывы, затем модель обучается на корпусе с использованием различных алгоритмов, и в конце происходит сравнение результатов.
Векторное представление текста
Теоретической базой для векторного представления слов считается дистрибутивная семантика. Она изучает семантическую близость слов на основе их распределения в текстовых корпусах [Zellig]. Это позволяет перевести информацию о словах в многомерные векторы с помощью линейной алгебры, что обеспечивает их компактное представление для вычислений [Li, 2017].
TF-IDF
TermFrequency-Inverse Document Frequency — это метод представления слов в векторной форме, учитывающий не только частоту встречаемости слова в документе (TF), но и его важность в контексте всего корпуса (IDF) [Sparck, 1972].
TF (Частота термина): отражает, насколько часто слово встречается в документе. Вычисляется как отношение числа вхождений слова к общему числу слов в документе.
IDF (Обратная частота документа): показывает, насколько уникально слово в контексте всего корпуса. Вычисляется как логарифм обратного отношения общего числа документов к числу документов, содержащих слово.
где |D| — число документов в коллекции;
— число документов из коллекции D D, в которых встречаться t.
Word2vec
Модель word2vec базируется на предположении о тесной связи между словами и частями речи в их векторных представлениях [Mikolov]. Её архитектура, основанная на контекстной близости слов, обычно включает следующие этапы: 1) токенизация словаря; 2) представление корпуса слов в векторной форме через one-hotencoding; 3) ввод полученных векторов слов в нейронную сеть; 4) расчет ошибки через вычисление функции потерь; 5) коррекция весов модели с использованием обратного распространения ошибки.
Word2vec предлагает две различные архитектуры: Skip-gram (по слову предсказывается контекст) и CBOW (по контексту предсказывается слово) [Mikolov, а].
Для модели Skip-gram условная вероятность генерации любого центрального слова с учетом окружающих слов контекста может быть смоделирована по следующе формуле:
где wc — центральное слово, wо — контекст, vi и ui — вектора центрального слова и контекста соответственно, v — размер словаря.
Параметрами модели skip-gram являются вектор центрального слова и вектор контекстного слова для каждого слова в словаре. В процессе обучения мы изучаем эти параметры, максимизируя функцию правдоподобия, что эквивалентно минимизации функции потерь:
Часто эта функция правдоподобия реализуется с помощью бинарного кросс-энтропийного лосса:
CBOW — метод обучения модели на основе текста, предсказывающий слово по его контексту. Формализуется следующим образом:
где wc — центральное слово, wо — контекст, vi и ui — вектора центрального слова и контекста соответственно, v — размер словаря.
Обучение CBOW аналогично обучению skip-gram. Оценка максимального правдоподобия модели CBOW эквивалентна минимизации функции потерь:
где (wo |wI ) — это целевая вероятность.
Классическая модель word2vec имеет проблемы с редкими словами, особенно в морфологически богатых языках, таких как французский, испанский и русский.
Методы
В работе применяются методы машинного обучения, такие как логистическая регрессия, градиентный бустинг (CatBoost), метод опорных векторов (SVM), мультиномиальный наивный байес, а также методы глубокого обучения, включая рекуррентные нейронные сети долговременной краткосрочной памяти (LSTM), сверточные нейронные сети (CNN) и трансформеры (Bert и GPT).
Логистическая регрессия
Логистическая регрессия применяется для прогнозирования вероятности принадлежности объекта к определенному классу. В многоклассовой классификации используется метод "Один против остальных" (One-vs-Rest, OvR), где создается K бинарных классификаторов (где K — количество классов), каждый из которых отличает один класс от всех остальных:
где P(Y=k) — вероятность принадлежности к классу k,
K — общее количество классов,
β0k, β1k, …, βnk — коэффициенты регрессии для класса k,
Модель выбирает класс с наибольшей предсказанной вероятностью.
Метод опорных векторов
Метод опорных векторов или SVM (Support Vector Machines) — линейный алгоритм для классификации и регрессии. Применяется широко и для линейных, и для нелинейных задач. SVM строит классифицирующую функцию F в виде:
где {·,·} — скалярное произведение, w — нормальный вектор к разделяющей гиперплоскости, b — свободный член.
Оптимизационная задача сводится к минимизации суммы квадратов весов для каждого бинарного классификатора с соответствующими ограничениями.
Градиентный Бустинг (CatBoostClassifier)
CatBoostClassifier - алгоритм машинного обучения на основе градиентного бустинга деревьев решений. Эффективно справляется с задачами классификации и регрессии [Dorogush, 2018], снижает переобучение и использует весь набор данных для обучения. Реализует случайную перестановку данных и вычисляет среднее значение меток для каждого элемента в соответствии с предшествующими элементами в перестановке. Предположим, что у нас имеется набор наблюдений D = {(Xi, Yi)} i=1...n, где Xi = (xi,1, . . .,xi,m) представляет собой вектор из m признаков, включающих как числовые, так и категориальные, а Yi ∈ R — это целевая переменная. Обозначим перестановку как σ = (σ1, . . ., σn). Тогда значение xσp,k заменяется соответствующим средним значением.
Мультиномиальный наивный Байес
В мультиномиальной модели документ рассматривается как последовательность случайных выборов слов из «мешка слов». Правдоподобие документа оценивается через вероятности совпадения выбранных слов с теми, что встречаются в документе. Наивное предположение заключается в том, что выбор каждого слова из мешка происходит независимо от выбора других слов.
В математической модели, где V = {wt}t=1|V | представляет собой словарь, каждый документ di представляется в виде вектора длины |di|, состоящего из слов, каждое из которых "вынуто" из словаря с вероятностью p(wt|cj). Правдоподобие принадлежности документа di классу cj определяется следующим образом:
где Nit — количество вхождений wt в di.
Априорные вероятности классов можно посчитать как:
Тогда классификация будет проходить как:
Сверточные нейронные сети (CNN)
Сверточные нейронные сети (CNN) - класс сетей, разработанных для обработки структурированных данных, в первую очередь изображений, широко применяются в компьютерном зрении [LeCun]. Они также могут использоваться для обработки текстовых данных, извлекая признаки из последовательности слов или символов.
В текстовых задачах CNN текст представляется матрицей встраивания, где каждое слово или символ представлено вектором. Сверточные слои применяются для извлечения локальных признаков, используя фильтры разных размеров окна. Затем выполняется операция объединения (pooling), например, максимальное или среднее объединение, для уменьшения размерности признаков. Полученные признаки передаются в полносвязные слои для классификации или других задач обработки текста.
CNN выделяют локальные паттерны и последовательности слов, что помогает модели анализировать различные языковые структуры, такие как n-граммы и контексты. Это полезно для классификации текста, анализа тональности, определения языка и других задач обработки.
Рекуррентные нейронные сети (RNN)
Рекуррентные нейронные сети (RNN) - модели глубокого обучения, которые обрабатывают последовательности с использованием рекуррентных связей, передающих информацию между временными шагами. Они развертываются по времени, применяя одни и те же параметры на каждом шаге, в отличие от стандартных сетей, которые передают информацию синхронно на каждом слое.
Сеть долговременной краткосрочной памяти LSTM (Long Short-Term Memory) была создана чтобы нивелировать недостатки базовой рекуррентной нейронной сети, такие как взрыв и затухание градиентов и проблемы с памятью сети [Hochreiter, 1997].
Рассмотрим ячейку памяти LSTM:

Рис. 1. Вычисление внутреннего состояния ячейки памяти в модели LSTM
LSTM включает в себя три вида шлюзов (Gate): входной, забывания и выходной. Выход скрытого слоя LSTM состоит из скрытого состояния и внутреннего состояния ячейки памяти. Только скрытое состояние передается на выходной слой, в то время как внутреннее состояние ячейки памяти остается полностью внутренним.
Трансформеры
Трансформер - модель, использующая только механизмы внимания без сверточных или рекуррентных слоев. Популярна в различных областях глубокого обучения, включая языковые задачи, обработку изображений и обучение с подкреплением [Vaswani, 2017]. Рассмотрим архитектуру:

Рис 2. Архитектура трансформера
И одним из важных механизмов работы трансформеров является механизм Self-Attention, его стоит разобрать более подробно. Механизм работы self-attention состоит из того, что на вход подаётся вектор слов x1, x2..xn, а на выходе мы получаем вектор представлений z1,z2…zn.
Для этого для каждого слова обучают три вектора k = key (ключ, куда мы смотрим), v = value (значение, что мы видим), q = query (запрос, откуда мы смотрим). Таким образом, для каждого слова будет считаться три вектора c помощью вектора весов: qj = Wqxj, kj = Wvxj, vj = Wvxj. Важность xi слова для обновления xj слова мы будем считать благодаря скалярному произведению qj на ki. Далее мы рассчитываем веса по формуле:
где d — размерность векторов, n — число слов входной последовательности.
После этого новое представление xj мы считаем, как:
Модификация self-attention — это Multi-head attention (MHA) (рис.3), где для каждого слова мы пересчитываем его представление несколько раз с разными весами. MHA позволяет модели совместно воспринимать информацию из разных представлений подпространства в разных положениях

Рис. 3. MHA, где несколько голов объединены, затем линейно преобразованы.
Данная архитектура лежит в основе популярных сетей, таких как Bert (состоящий только из блоков энкодера) и GPT (состоящий только из блоков декодера), которые были использованы в нашем исследовании.
Результаты и обсуждения
Рассматриваем "Geo Reviews Dataset 2023" от Яндекса - более 500 000 отзывов организаций в России, собранных за 2023 год. Ценный ресурс для исследований в области анализа тональности и оценки организаций.
Основные атрибуты включают:
-
Адрес организации (address)
-
Название организации (name_ru)
-
Список рубрик (rubrics)
-
Оценка пользователя от 0 до 5 (rating)
-
Текст отзыва (text)
При анализе данных было решено переопределить метки классов для достижения более сбалансированного состояния. Исходные пять категорий оценок (от 1 до 5) были объединены с целью упрощения задачи анализа тональности отзывов и обучения моделей.
-
Негативные отзывы:
-
Оценка 1: сильно негативный отзыв
-
Оценка 2: негативный отзыв
-
-
Нейтральные отзывы:
-
Оценка 3: нейтральный отзыв
-
-
Позитивные отзывы:
-
Оценка 4: очень позитивный отзыв
-
Оценка 5: сильно позитивный отзыв
-
Приведем часть данных в виде таблицы 1.
Таблица 1. Данные из набора Geo Reviews Dataset
|
|
address |
name_ru |
rating |
rubrics |
text |
|
0 |
Московская область, Электросталь, проспект Ленина, 29
|
Продукты Ермолино
|
5.0 |
Магазин продуктов; Продукты глубокой заморозки;
|
Замечательная сеть магазинов в общем, хороший ассортимент, цены приемлемые, а главное качество на высоте!!! … |
|
… |
… |
… |
… |
… |
… |
|
… |
… |
… |
… |
… |
… |
|
500 112
|
Краснодар, Прикубанский внутригородской округ, микрорайон имени Петра Метальникова, улица Петра Метальникова, 26
|
LimeFit
|
1.0 |
Фитнес-клуб
|
Не знаю смутят ли кого-то данные правила, но я была удивлена: хочешь, чтобы твой шкаф замыкался купи замочек. |
Слияние оценок в три категории обеспечило более гармоничное распределение между классами и позволило уменьшить несбалансированных классов в данных. В итоговом датасете представлено 117779 строк данных.
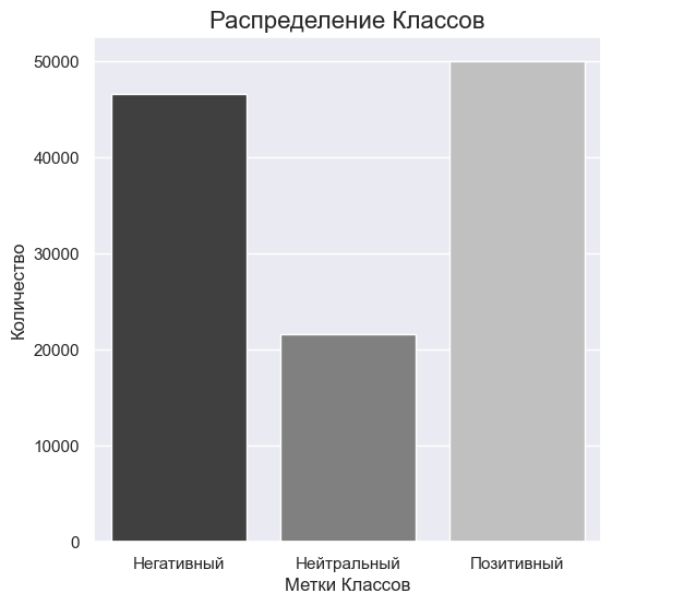
Рис. 4. Распределение меток классов
где:
-
F1weighted — взвешенная F1-мера,
-
F1i — F1-мера для класса i,
-
wi — вес класса i, рассчитанный как доля объектов класса i от общего числа объектов.
Качество решения задачи так же оценивалось с помощью матрицы ошибок.
Таблица 2 Матрица ошибок
|
Истинный класс |
|
a=0 |
a=1 |
a=2 |
|
y=0 |
Y00 |
Y01 |
Y02 |
|
|
y=1 |
Y10 |
Y11 |
Y12 |
|
|
y=2 |
Y21 |
Y22 |
Y23 |
|
|
|
Предсказанный класс |
|||
В таблице 2 первый индекс означает истинный класс, а второй предсказанный, таким образом правильно предсказанные классы располагаются по диагонали матрицы.
Применение классических методов машинного обучения
При решении поставленной задачи обратимся сначала к фундаментальным алгоритмам классификации используем логистическую регрессию, CatBoost, SVM и мультиномиальный наивный Байес для классификации текстов. Применяем метод TF-IDF для векторизации данных.
Логистическая регрессия
В ходе нашего исследования использовался GridSearchCV из sklearn.model_selection для подбора параметров. Наилучшие результаты достигнуты с параметрами: lr_C = 0.1, multi_class='ovr', max_iter=500, class_weight='balanced'. Это привело к F1-мере 0.78 и следующей матрице ошибок:
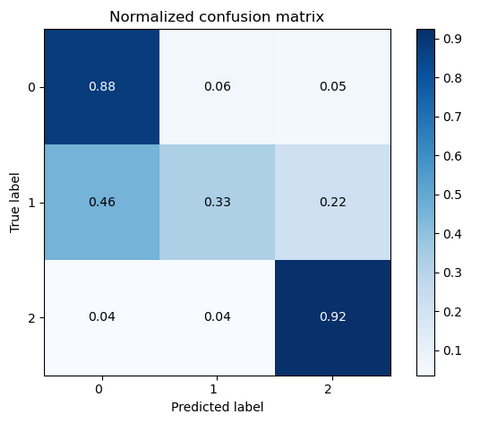
Рис. 5. Матрица ошибок для модели логистической регрессии
Метод опорных векторов
В модели мы использовали метод TF-IDF и дополнительные признаки. С помощью GridSearchCV подобрали оптимальные гиперпараметры: penalty = l2, class_weight = balanced, max_iter = 1000, multi_class='ovr'. Это привело к F1-мере 0.77 и следующей матрице ошибок:
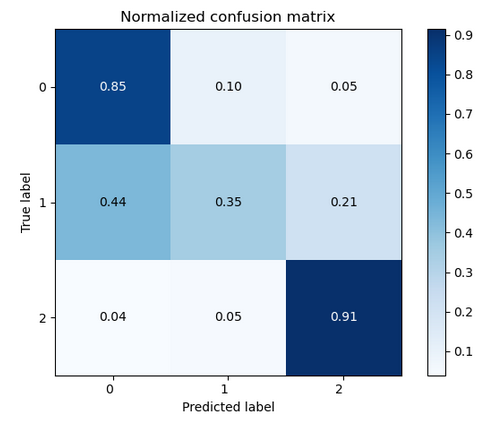
Рис 6. матрица ошибок для модели SVM
Градиентный Бустинг (CatBoostClassifier)
Были использованы следующие гиперпараметры модели: learning_rate = 0.1, depth = 10, iterations = 1000, и l2_leaf_reg = 5. Это привело к F1-мере 0.76 и следующей матрице ошибок:

Рис. 7. Матрица ошибок для модели CatBoostClassifier
Мультиномиальный наивный Байес
Модель мультиномиального наивного Байеса была запущена с исходными параметрами: alpha=0.1, fit_prior = True. В результате этих настроек удалось достичь F1-меры в 0.75, а сформирована матрица ошибок в следующем виде:

Рис. 8. Матрица ошибок модели мультиномиального наивного Байеса
Применение методов глубокого обучения
Сверточные нейронные сети(CNN)
CNN обучалась с помощью оптимизатора AdamW, lr=1e-4, batch_size = 512. Использовались Word2Vec эмбеддинги. Это привело к точности с F1-мерой 0.75 и соответствующей матрице ошибок:

Рис. 9 Матрица ошибок модели CNN
Рекуррентная нейронная сеть (LSTM)
LSTM была оптимизирована с AdamW, lr=1e-3. Достигнута точность F1-меры 0.79, сформирована матрица ошибок для подробного обзора результатов модели:

Рис. 10. Матрица ошибок LSTM
Трансформеры
Использовали три варианта модели BERT: базовая версия от DeepPavlov с 12 слоями, rubert-tiny2 с тремя слоями и была предпринята попытка сократить архитектуру до одного слоя и провести обучение на уменьшенной модели. Все архитектуры обучались с применением оптимизатора AdamW, lr=5e-5. Базовая BERT показала переобучение с низкой F1-мерой 0.26, указывая на необходимость корректировок для более устойчивых результатов:

Рис 11. Матрица ошибок BERT
Модель rubert-tiny2 продемонстрировала выдающуюся производительность, достигнув значения F1-меры на уровне 0.83. В результате этого успешного обучения была сформирована матрица ошибок:

Рис 12. Матрица ошибок rubert-tiny2 (не измененный)
Модель rubert-tiny2 с одним слоем проявила впечатляющую производительность с F1-мерой, достигшей значения 0.81. Этот результат подчеркивает эффективность уменьшенной архитектуры в сравнении с более глубокими моделями.

Рис 13. Матрица ошибок rubert-tiny2 c одним слоем
Для дополнительного анализа использовалась модель ruGPT3small от Сбербанка с двумя слоями и оптимизатором SophiaG [Liu, 2023], lr=8e-6. Достигнута F1-мера 0.79, сформирована матрица ошибок:

Рис 14. Матрица ошибок rugpt3small c двумя слоями
Применим алгоритм LIME для интерпретации результатов модели rubert-tiny2 с наивысшей точностью. Этот шаг поможет понять влияние факторов на решения модели, повышая интерпретируемость результатов.

Рис.15. Интерпретация результатов с помощью LIME
На рис. 15 можно увидеть благодаря весам каких слов данный текст был отмечен как негативный.
Заключение
Сравним эффективность моделей глубокого обучения с традиционными методами при решении задачи семантического анализа.
Таблица 3.
|
Название модели |
F1-мера |
Время, в минутах |
|
SVM+Tfidf |
0.77 |
< 1 |
|
Logis+Tfidf |
0.78 |
< 1 |
|
Catboost+Tfidf |
0.76 |
3.5 |
|
NaiveBayes+Tfidf |
0.75 |
< 1 |
|
CNN+word2vec |
0.75 |
22 |
|
LSTM |
0.80 |
2 |
|
ruBert_Base |
0.26 |
300 |
|
rubert-tiny2 |
0.83 |
60 |
|
rubert-tiny2_one layer |
0.81 |
10 |
|
ruGPT3small |
0.79 |
4 |
Лучшие результаты среди классических методов показала логистическая регрессия: высокое качество прогнозирования и быстрая производительность.
Исследование подтверждает превосходство модели на основе BERT по качеству в сравнении с другими методами обучения. Однако, обучение этой модели требует времени. Уменьшение числа слоев энкодера может ускорить работу без существенной потери качества.
В дальнейших исследованиях в области семантического анализа текста рекомендуется уделить внимание получению эмбеддингов с использованием трансформера BERT и их последующему применению в сочетании с рекуррентными нейронными сетями, которые продемонстрировали достаточно высокое качество по сравнению с другими методами машинного и глубокого обучения.