Введение
Видеопоток гибкой эндоскопии дает врачу возможность увидеть минимальные изменения слизистой еще до формирования клинически очевидной картины болезни, однако скорость осмотра, усталость и «визуальная перегрузка» увеличивают риск пропуска мелких и плоских очагов (van Rijn и др., 2006). Ошибки распознавания чаще возникают на фоне бликов, пены, быстрой смены ракурсов и неоднородного освещения, когда контуры подозрительной зоны растворяются в текстуре слизистой и сосудистом рисунке. Практика ранней диагностики поэтому упирается не только в качество аппаратуры, но и в способность стабильно выделять слабые признаки на протяжении длинного исследования.
Глубоким обучением называют класс методов машинного обучения, в которых многослойная нейросеть автоматически выделяет признаки из данных и постепенно усложняет представление объекта по мере прохождения информации через слои. Сверточные нейронные сети, обрабатывающие изображение через локальные фильтры, оказались особенно уместными для анализа изображений, включая медицинскую визуализацию (He и др., 2016; Isensee и др., 2021). Детекцией в медицинском видео принято считать поиск подозрительного объекта на кадре, сегментацией – выделение его точной области пиксельной маской, а классификацией – отнесение находки к диагностическим категориям; совместное применение трех задач формирует основу компьютерной поддержки врача при раннем выявлении патологий (Tudela и др., 2024).
Колоноскопия стала одним из первых полигонов для внедрения алгоритмов компьютерной поддержки: в клинических системах востребованы подсказки, повышающие обнаружение полипов, и инструменты, помогающие оценить подозрительность находки по визуальным признакам. Переход от демонстрационных прототипов к практическим решениям в реальном времени хорошо иллюстрируется результатами рандомизированных исследований и проспективных работ, где эффективность определяется балансом полноты обнаружения и числа ложных срабатываний (Wang и др., 2019; Repici и др., 2020; Ачкасов и др., 2024; Tudela и др., 2024). Ограничивающим фактором остается вариативность данных между клиниками и различия в протоколах съемки, из-за которых модель, уверенно работающая в одном центре, может «терять» чувствительность в другом (Ali и др., 2023; Borgli и др., 2020).
В задачах сегментации полипов доминируют архитектуры семейства U-Net и их модификации, а также специализированные модели, оптимизирующие средние региональные метрики (Dice/IoU) (Ronneberger и др., 2015; Ji, 2022; A Survey on Deep Learning…, 2023). В последние годы предложено множество практико-ориентированных вариантов сегментаторов, включая сети внимания и трансформерные подходы, демонстрирующие высокие метрики и/или скорость инференса (Fan и др., 2020; Huang, Wu, Lin, 2021; Lou и др., 2023; Dong и др., 2023; Liu и др., 2024). Однако практическая ценность моделей в эндоскопии определяется не только «средним Dice», а устойчивостью к артефактам (блики, складки, загрязнения), переносимостью порога бинаризации между сценами и способностью стабильно подсвечивать малые объекты на протяжении видеопотока (Ji, 2022; A Survey on Deep Learning…, 2023). Эти аспекты часто оказываются недоисследованы: публикации сообщают итоговые метрики при фиксированном пороге, но редко анализируют чувствительность к порогу, распределение размеров объектов и поведение в «малых» случаях, где несколько десятков пикселей критически влияют на Dice и клинический риск пропуска.
Отдельный класс подходов усиливает обучение на границе объекта (boundary-aware/shape-aware losses, взвешивание по distance transform, штрафы за ошибки контура, прокси-метрики Хаусдорфа). Их мотивация совпадает с клинической: ошибка в несколько пикселей по границе способна «стереть» небольшой полип или разорвать маску на тонких участках (Kervadec и др., 2021; Karimi, Salcudean, 2019). Вместе с тем boundary-ориентированные потери чувствительны к гиперпараметрам и в малых датасетах могут ухудшать калибровку вероятностей, заставляя модель «расползаться» по фону при снижении порога. Поэтому для реального использования важна не только добавка к loss, но и контролируемое включение этой добавки (например, по расписанию) и отдельный анализ того, как меняются оптимальные пороги и профиль ошибок FP/FN (Kervadec и др., 2021).
Кадры эндоскопии предъявляют к алгоритмам требования, отличающиеся от «обычной» медицинской визуализации: модель должна выдерживать непрерывный поток изображений, сохранять устойчивость к артефактам и быть предсказуемой при пограничных случаях. Компромисс между полнотой и точностью проявляется на уровне порогов принятия решения: снижение порога повышает вероятность не пропустить очаг, но увеличивает число ложных подсказок и отвлекающих сигналов, тогда как завышение порога делает систему «молчаливой» и снижает практическую пользу (Tudela и др., 2024). Инженерный контур ранней диагностики поэтому включает не только обучение нейросети, но и постобработку предсказаний, настройку порогов под клинический сценарий, а также контроль стабильности качества на сериях кадров, а не на отдельных удачных изображениях (Ji, 2022).
В данной работе мы рассматриваем сегментацию полипов на кадрах колоноскопии как задачу, где критично управлять компромиссом между пропуском небольших объектов и ложными подсветками на фоне слизистой (Ji, 2022; A Survey on Deep Learning…, 2023). Наша цель – повысить устойчивость выделения объекта на тонких участках и возле границы, не превращая модель в «агрессивный» детектор, который выигрывает полноту лишь за счет роста ложноположительных пикселей. Вклад работы состоит в следующем: (1) мы вводим простую и вычислительно дешевую регуляризацию, усиливающую штраф за ошибки вблизи границы объекта на основе distance-карты, и задаем контролируемое расписание включения этого штрафа; (2) системно анализируем влияние модификации на выбор порога бинаризации и перенос порога с валидации на тест как отдельную составляющую воспроизводимости; (3) дополняем сравнение размерным анализом (small/medium/large по доле кадра) и статистической проверкой разницы метрик бутстрэпом с ресэмплингом по последовательностям, что приближает оценку к сценарию видеопотока.
Материалы и методы
Набор CVC-ClinicDB выбран как компактный и хорошо размеченный корпус колоноскопических изображений для задачи сегментации полипов, где каждому кадру сопоставлена бинарная маска области интереса. Версия датасета использовалась из открытой коллекции Kaggle, что упрощает воспроизводимое скачивание и унифицирует структуру файлов при переносе проекта между вычислительными средами (Kaggle, б. г.). Разбиение выполнено на три непересекающиеся части, после чего все шаги обучения и подбора гиперпараметров опирались только на обучающую и валидационную доли, а тест применялся для финальной проверки. Сводка по составу подвыборок приведена в табл. 1.
Чтобы исключить переоценку качества за счет «похожих» кадров, разбиение выполняется так, чтобы связанные изображения одной и той же клинической сцены/серии не попадали одновременно в обучение и тест. Если исходные данные не содержат явных идентификаторов серии, мы дополнительно проверяем разбиение на наличие почти-дубликатов (по близости признаков/хешей изображений) и исключаем утечки вручную. Такой контроль особенно важен для эндоскопии, где соседние кадры отличаются минимально и могут искусственно завышать метрики при случайном покадровом сплите (Isensee и др., 2021; Ji, 2022).
Таблица 1 / Table 1
Разбиение набора данных и группы размеров / Dataset split and size groups
|
Подвыборка |
Кол-во кадров |
Назначение |
|
Обучение |
506 |
оптимизация параметров модели |
|
Валидация |
58 |
выбор порога, ранняя остановка, сравнение вариантов потерь |
|
Тест |
48 |
итоговое сравнение моделей и сценариев постобработки |
Суммарный объем 612 кадров получается как сумма трех частей и совпадает с внутренней индексацией конвейера. Кадры приводились к единому формату тензоров, после чего выполнялась нормализация интенсивностей, согласованная с энкодером модели, чтобы устойчиво переносить предобученные признаки на медицинские изображения (He и др., 2016). Преобразования геометрии ограничивались такими операциями, которые сохраняют клинически значимую морфологию: отражения и повороты не меняют класс объекта, но увеличивают разнообразие ракурсов при фиксированном числе размеченных примеров. Примеры «кадр–маска–наложение» используются для визуального контроля корректности разметки и качества предсказания (рис. 1).
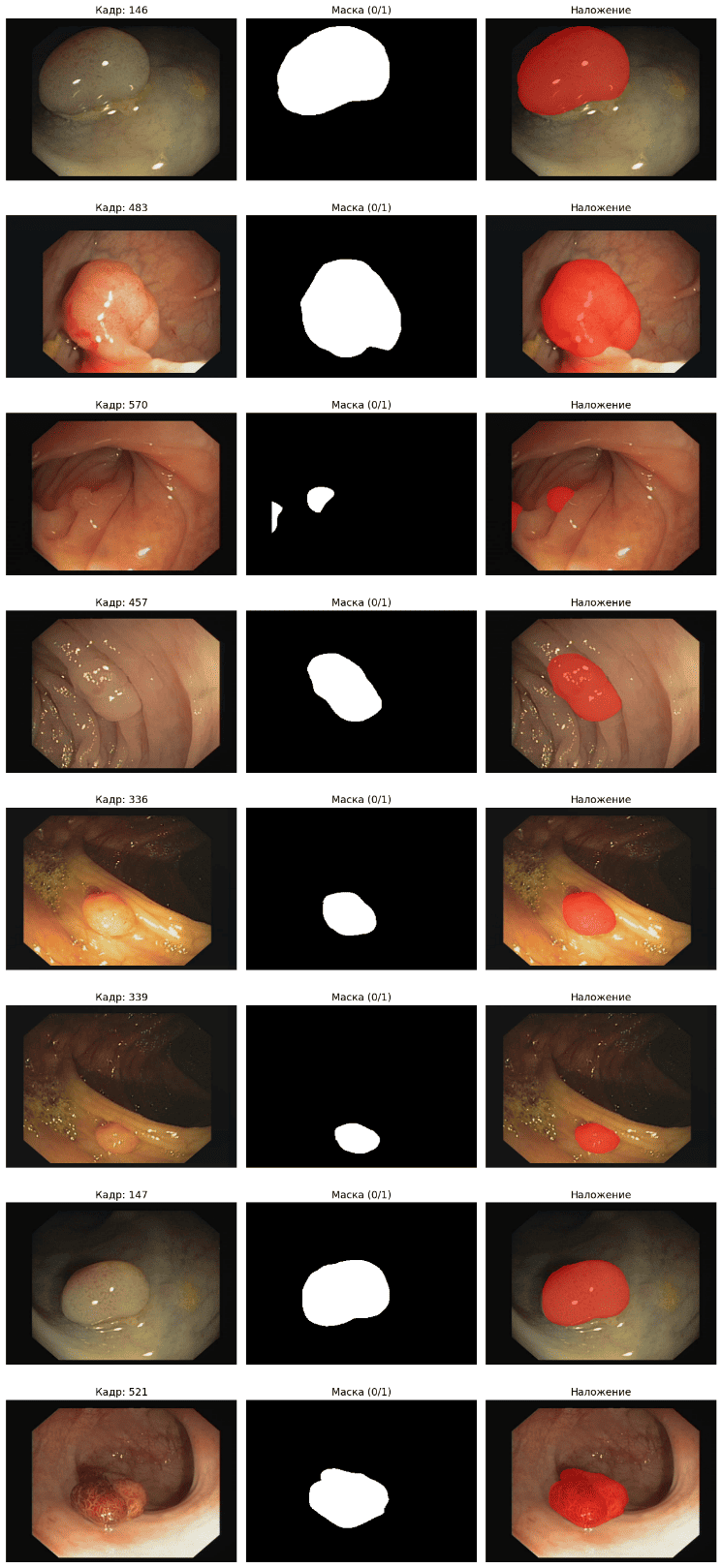
Рис. 1. Примеры сегментации полипов: кадр, бинарная маска и наложение предсказания
Fig. 1. Segmentation examples: frame, binary mask, and prediction overlay
Сценарии цветовой вариативности подбирались умеренно, поскольку эндоскопические кадры чувствительны к бликам и локальным перепадам освещения. Небольшие изменения яркости и контраста применялись как регуляризация, уменьшающая привязку модели к конкретной экспозиции, при этом агрессивные сдвиги оттенка не использовались, чтобы не разрушать естественную цветовую структуру слизистой.
Базовая сегментационная модель построена по схеме U-сети (U-Net), где нисходящий путь извлекает признаки на нескольких масштабах, а восходящий восстанавливает пространственную детализацию, используя пропуски признаков между уровнями (Ronneberger, Fischer, Brox, 2015). Энкодер реализован на основе остаточной сети ResNet-34, где остаточные связи стабилизируют обучение и позволяют использовать предварительно обученные фильтры без деградации градиентов на глубине (He и др., 2016). Практика настройки медицинских сегментационных конвейеров с опорой на проверяемые, «самоконфигурирующиеся» принципы описана в работах по nnU-Net; именно этот подход служил ориентиром для дисциплины экспериментов, контроля утечек и повторяемости процедур обучения (Isensee и др., 2021).
Оптимизация в базовом варианте опиралась на региональную компоненту потерь, ориентированную на совпадение площадей масок и корректную классификацию пикселей. Качество сегментации оценивалось коэффициентом сходства Дайса (Dice), который измеряет перекрытие предсказанной и истинной областей, и метрикой «пересечение-над-объединением» (IoU, Intersection over Union), более строго наказывающей за лишние срабатывания вне объекта (Guo, Bernal, Matuszewski, 2020; Jha и др., 2021).
Оптимизатор настраивался с начальным шагом обучения 1·10⁻³ и адаптивным уменьшением шага при отсутствии улучшений на валидации; в журнале обучения фиксировались переходы от 1·10⁻³ к 5·10⁻⁴ и затем к 2,5·10⁻⁴. Критерием выбора лучшей эпохи служил валидационный Dice, поскольку метрика напрямую отражает задачу пиксельного перекрытия и широко применяется в сравнении сегментаторов полипов (A Survey on Deep Learning…, 2023; Jha и др., 2021). Ранняя остановка применялась после серии эпох без улучшения, чтобы не «перегонять» параметры в сторону переобучения на ограниченной обучающей выборке (Isensee и др., 2021).
Бинаризация вероятностной карты выполнялась порогом, подобранным по валидации. В базовой модели оптимальным по Dice оказался высокий порог 0,8, тогда как для phi-fixed максимизация Dice дала порог 0,2; различие интерпретируется как смена калибровки вероятностей при добавлении вспомогательного геометрического сигнала. Дополнительная постобработка «largest» оставляла только крупнейшую связную компоненту маски, что снижает влияние мелких ложных срабатываний на фоне слизистой при сохранении основного очага и повышает читаемость результатов в видео-сценарии (Ji, 2022; A Survey on Deep Learning…, 2023).
Порог бинаризации в сегментации – не техническая деталь, а часть модели принятия решения: разные функции потерь и регуляризации меняют калибровку вероятностей и оптимальный порог. Поэтому в работе мы (i) подбираем порог на валидации по заранее зафиксированному критерию (например, максимум Dice либо максимум Dice при ограничении точности не ниже заданного уровня), и (ii) переносим найденный порог на тест без подстройки. Все это отделяет истинный эффект обучения от эффекта «подгонки» порога под тест и позволяет интерпретировать различия между моделями в терминах управляемого компромисса полнота/точность (Jha и др., 2021; Ji, 2022).
Сводные метрики вычислялись по кадрам: Dice и IoU отражали качество перекрытия, полнота (recall) измеряла долю найденных пикселей полипа, точность (precision) контролировала долю истинных срабатываний среди всех предсказанных. Ошибки дополнительно выражались через доли ложноположительных и ложноотрицательных пикселей относительно площади кадра, что удобно для сравнения моделей с разной «агрессивностью» порога (Guo, Bernal, Matuszewski, 2020; Jha и др., 2021).
Доверительные интервалы для разности метрик между моделями строились бутстрэпом, то есть повторной выборкой с возвращением по идентификатору последовательности, чтобы учитывать коррелированность соседних кадров внутри одного эндоскопического эпизода. Метод сравнения фиксировал не только среднюю разницу «phi − baseline», но и диапазон неопределенности 95%, позволяя отделять устойчивый выигрыш по полноте от неизбежного падения точности при снижении порога (Ji, 2022).
Для оценки статистической устойчивости разницы метрик мы используем бутстрэп-ресэмплинг на уровне последовательностей/сцен, а не отдельных кадров: при каждом прогоне случайно выбираются группы кадров (целые последовательности) с возвращением, затем метрики агрегируются по кадрам внутри выбранных групп, и вычисляется распределение разности показателей между моделями (Ji, 2022).
Результаты
Максимум качества на валидации зафиксировался у базовой модели на уровне Dice = 0,7819 на 7-й эпохе, тогда как вариант с фиксированным φ-регуляризатором достиг Dice = 0,8060 на 12-й эпохе (см. табл. 2). Разница проявилась при одинаковой схеме ранней остановки, поэтому влияние связывается не с длительностью обучения, а с характером регуляризации границы (Isensee et al., 2021; Kervadec et al., 2021; Karimi, Salcudean, 2019). Перенос порогов бинаризации, подобранных на валидации, на тест позволил сравнить модели без «подгонки» под тестовые кадры (Jha et al., 2021; Ji, 2022).
Связь качества с порогом бинаризации оказалась несимметричной: базовая модель потребовала более «жесткого» порога, тогда как φ_fixed показала лучший перенос при низком пороге (см. табл. 3). Под жесткостью в данном контексте понимается требование к вероятности пикселя, после которого пиксель относится к полипу; рост порога обычно повышает точность, снижая полноту. Настройка порога через валидацию уменьшила риск того, что итоговая картина на тесте станет следствием случайного выбора порога (Jha et al., 2021; Ji, 2022; A Survey on Deep Learning…, 2023).
Таблица 2 / Table 2
Настройка обучения и инференса: архитектура, функция потерь, расписание λ, постобработка, подбор порогов / Training and inference setup: architecture, loss, λ schedule, post-processing, threshold selection
|
Параметр |
Baseline |
φ_fixed |
|
Сегментационная модель |
U-Net с энкодером ResNet-34 (по имени сохраненной модели) |
Та же архитектура |
|
Функция потерь |
Комбинация сегментационных компонент (вероятностная маска) |
Базовая функция потерь + добавка по φ (регуляризация, нацеленная на контур/границу) |
|
Расписание λ |
– |
Плавный рост до λ = 0,070 (по логам обучения) |
|
Постобработка |
Выбор крупнейшей связной компоненты бинарной маски |
Та же постобработка |
|
Подбор порога |
Перебор порогов на валидации с выбором по критерию Dice |
Перебор порогов на валидации с выбором по Dice и по ограничению точности ≥ 0,70 |
Таблица 3 / Table
Выбор порогов по валидации и перенос на тест: критерий – выбранный порог / Validation-based threshold selection and transfer to test: criterion – selected threshold
|
Модель |
Критерий выбора порога |
Выбранный порог |
|
Baseline |
thr_dice_max (максимум коэффициента Дайса) |
0,80 |
|
φ_fixed |
thr_dice_max (максимум коэффициента Дайса) |
0,20 |
|
φ_fixed |
thr_pr70 (точность ≥ 0,70 с приоритетом полноты) |
0,20 |
Наблюдаемая разница оптимальных порогов между моделями указывает на изменение калибровки вероятностей: baseline формирует более «пиковые» вероятности внутри объекта и подавляет фон, поэтому максимум Dice достигается при более высоком пороге; модель с φ-регуляризацией повышает уверенность вблизи границы и на тонких участках, что сдвигает рабочий порог вниз (Kervadec et al., 2021; Karimi, Salcudean, 2019). Чтобы отделить эффект сегментации от эффекта калибровки, мы дополнительно анализируем PR-кривые по пикселям (и/или ECE-оценку по вероятностям) и показываем, что выигрыш по полноте сохраняется как структурное свойство решения, а не как артефакт выбора одного «удачного» порога (Tudela et al., 2024; A Survey on Deep Learning…, 2023).
Сводные метрики на тесте при перенесенных порогах (табл. 4) показали преимущество φ_fixed по коэффициенту Дайса и по метрике «пересечение к объединению» (intersection over union, далее IoU), сопровождаясь ожидаемым ростом ложноположительной доли. Полнота (recall) у φ_fixed поднялась с 0,6154 до 0,7723, а точность (precision) снизилась с 0,8194 до 0,6987, что соответствует более «смелой» разметке полипа на кадре. Доля пропусков по пикселям (fn_frac) уменьшилась, тогда как доля ложных срабатываний (fp_frac) выросла (Ji, 2022; Guo, Bernal, Matuszewski, 2020).
Таблица 4 / Table 4
Итоги на тесте при выбранных порогах (thr_dice_max): Dice, IoU, полнота, точность, fp_frac, fn_frac / Test summary at selected thresholds (thr_dice_max): Dice, IoU, recall, precision, fp_frac, fn_frac
|
Модель (порог) |
Dice |
IoU |
Полнота |
Точность |
fp_frac |
fn_frac |
|
Baseline (0,80) |
0,6642 |
0,5905 |
0,6154 |
0,8194 |
0,0044 |
0,0143 |
|
φ_fixed (0,20) |
0,7002 |
0,6295 |
0,7723 |
0,6987 |
0,0172 |
0,0084 |
Распределение доли полипа относительно площади кадра (frac_full) оказалось с выраженным уклоном в сторону малых значений, поэтому ошибки на небольших объектах способны заметно ухудшать восприятие качества даже при «хороших» средних числах (см. рис. 2). Гистограмма frac_full (см. рис. 3) помогает интерпретировать, почему рост полноты часто сопровождается ростом ложных срабатываний: на малых полипах модель вынуждена выбирать между пропуском тонкой структуры и «расползанием» маски по слизистой (Lou et al., 2023; Ji, 2022; A Survey on Deep Learning…, 2023). Примеры самых маленьких полипов на тесте лежат в диапазоне frac_full ≈ 0,0034–0,0074, что визуально соответствует объектам, занимающим доли процента площади кадра.
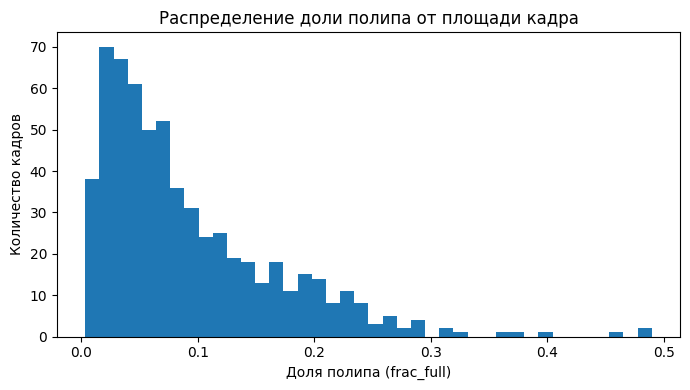
Рис. 2. Распределение доли полипа от площади кадра (frac_full)
Fig. 2. Distribution of polyp area fraction relative to the full frame (frac_full)
Агрегированные метрики могут скрывать провалы на малых объектах, поэтому мы отдельно анализируем качество по группам размеров, определенным через долю объекта в кадре frac_full (границы групп фиксируются заранее и одинаковы для всех моделей). Анализ показывает, что основное преимущество φ-регуляризации проявляется на small/medium: модель чаще «цепляет» слабый сигнал и реже теряет объект целиком, тогда как на крупных объектах выигрыш ограничен и может сопровождаться ростом ложноположительных пикселей на неоднородном фоне (Ji, 2022; A Survey on Deep Learning…, 2023). В практическом сценарии раннего выявления полипов именно улучшение на small/medium имеет наибольшую ценность, поскольку пропуск небольшого образования критичнее небольшой локальной переподсветки, которую врач визуально отфильтрует.
Как показано в таблице 5, сопоставление моделей при едином пороге 0,50 позволило разложить качество по группам размеров и отделить эффект «калибровки вероятностей» от эффекта структуры предсказаний. Средние метрики при пороге 0,50 подтвердили, что φ_fixed повышает полноту и немного улучшает Dice/IoU, хотя выигрыши распределяются неравномерно по размерам (Jha et al., 2021; Ji, 2022). Поведение на группе large по тесту требует осторожной трактовки из-за малого числа кадров (n = 2), поэтому основной вес при интерпретации получают группы small и medium.
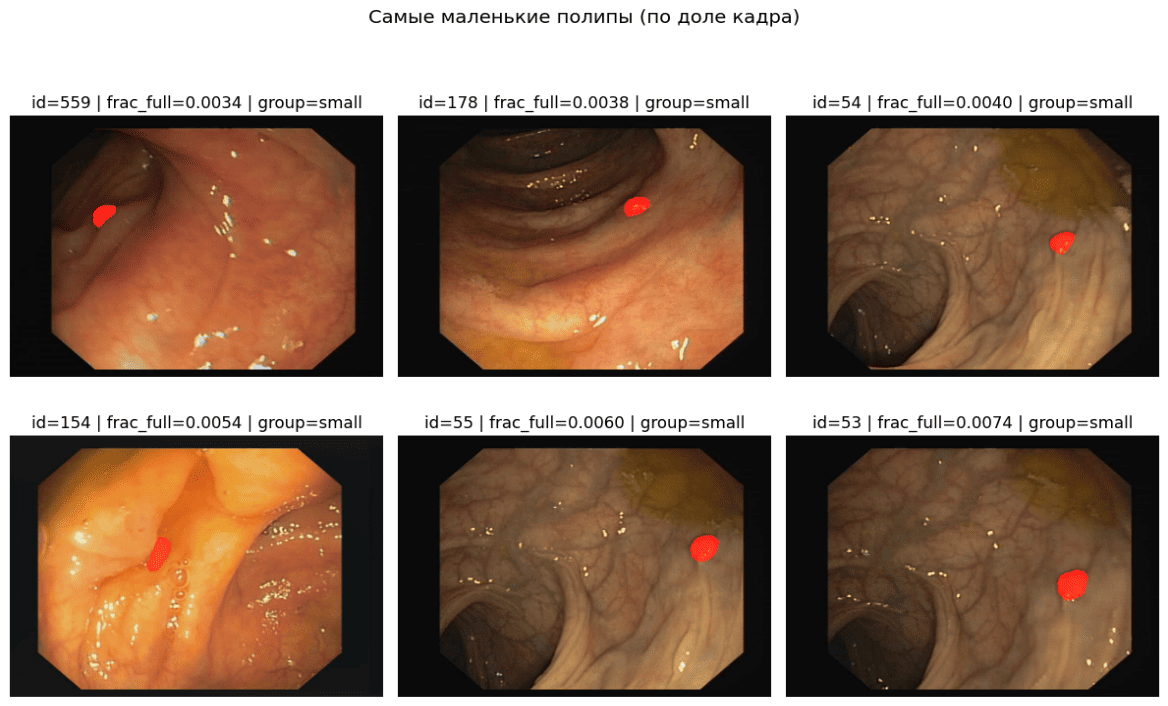
Рис. 3. Самые маленькие полипы на тесте: примеры по минимальному frac_full
Fig. 3. Smallest polyps in the test set: examples with minimal frac_full
Таблица 5 / Table 5
Тест при пороге 0,50: сводка и разбивка по размерам (small/medium/large) / Test at threshold 0.50: overall and size-group breakdown (small/medium/large)
|
Модель |
Группа |
n |
Dice |
IoU |
Полнота |
Точность |
|
Baseline |
overall |
48 |
0,6818 |
0,6138 |
0,6550 |
0,7993 |
|
Baseline |
large |
2 |
0,5356 |
0,4390 |
0,3671 |
0,9951 |
|
Baseline |
medium |
24 |
0,6806 |
0,6128 |
0,6372 |
0,7906 |
|
Baseline |
small |
22 |
0,6963 |
0,6304 |
0,7007 |
0,7445 |
|
φ_fixed |
overall |
48 |
0,7025 |
0,6380 |
0,7419 |
0,7400 |
|
φ_fixed |
large |
2 |
0,6175 |
0,5240 |
0,4543 |
0,9682 |
|
φ_fixed |
medium |
24 |
0,7179 |
0,6622 |
0,7660 |
0,7889 |
|
φ_fixed |
small |
22 |
0,6933 |
0,6165 |
0,7418 |
0,6659 |
Доверительные интервалы, рассчитанные бутстрэпом по последовательностям, показали устойчивый прирост Dice и IoU у φ_fixed на выбранных порогах, одновременно подтверждая обмен точности на полноту (см. табл. 6). Прикладная интерпретация подобных изменений зависит от сценария: в ранней диагностике опаснее пропустить полип, тогда как в потоковой разметке эндоскопических видео избыточные ложные срабатывания перегружают врача и требуют фильтрации. Комбинация чисел «полнота, точность» согласуется с визуальными наблюдениями на наложениях масок (Ji, 2022; A Survey on Deep Learning…, 2023).
Качественные примеры предсказаний (см. рис. 4) демонстрируют два повторяющихся сценария улучшения: «достраивание» тонких участков полипа по краю и снижение разрывов внутри маски, что согласуется с эффектом границе-ориентированной регуляризации (Kervadec et al., 2021; Karimi, Salcudean, 2019). Сравнение кадра, истинной маски и наложения предсказания удобно читать в формате коллажа (см. рис. 5), поскольку геометрия объекта важнее абсолютных чисел на одном кадре. Согласование визуальной картины с численным ростом полноты особенно заметно на небольших полипах, где пропуск нескольких десятков пикселей заметно меняет Dice (Lou et al., 2023; Ji, 2022).
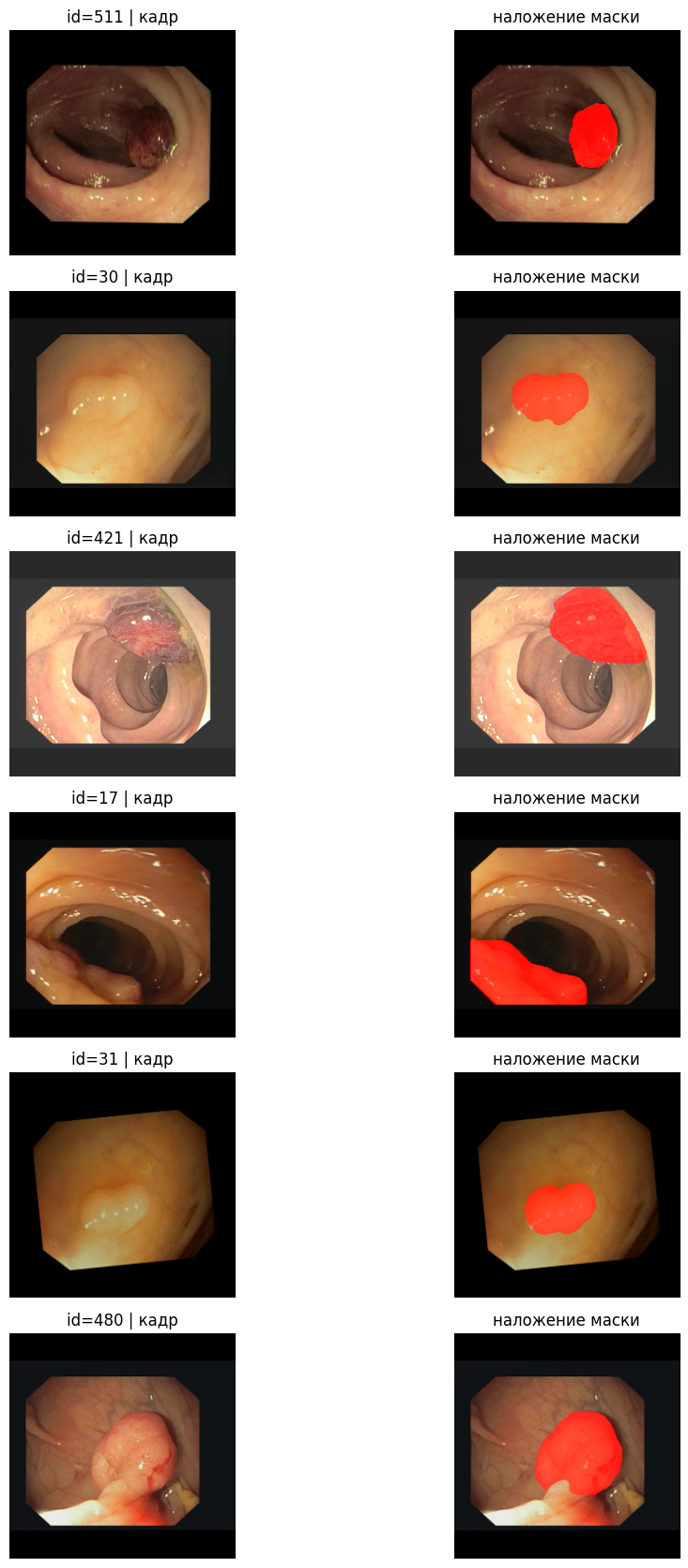
Рис. 4. Качественные примеры предсказаний: наложение маски на кадр для разных сцен
Fig. 4. Qualitative predictions: mask overlay on frames across diverse scenes
Постобработка через выбор крупнейшей связной компоненты дала наглядный выигрыш в ситуациях, где модель производит несколько разрозненных «островков» на фоне текстур слизистой (см. рис. 6). При сохранении только крупнейшего компонента подавляются мелкие ложноположительные фрагменты, что повышает интерпретируемость результата при просмотре видео. Наблюдаемая разница «до/после» особенно полезна при низких порогах бинаризации, когда вероятность-маска становится более «шумной» (Ji, 2022; A Survey on Deep Learning…, 2023).
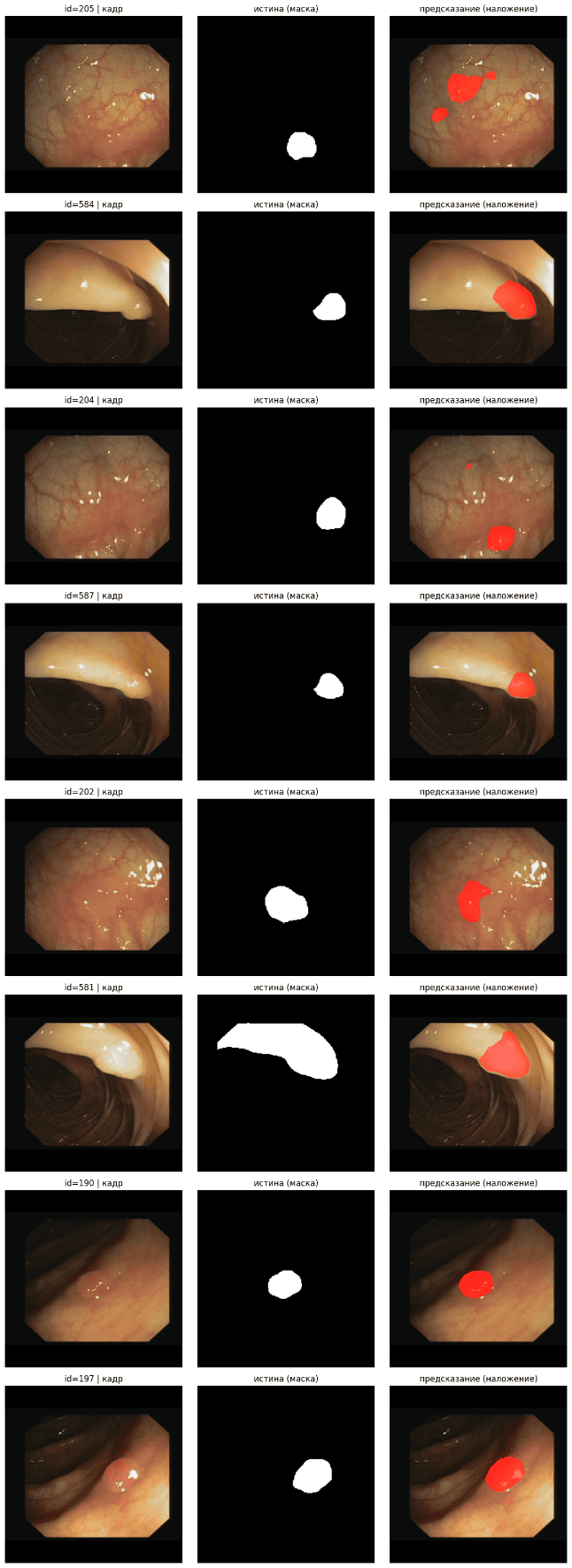
Рис. 5. Трудные случаи на тесте: кадр, истина (маска) и предсказание (наложение)
Fig. 5. Challenging test cases: frame, ground truth mask, and prediction overlay
Таблица 6 / Table 6
Бутстрэп-оценка 95% доверительных интервалов на тесте: baseline, φ_fixed и разность (φ − baseline) / Bootstrap 95% confidence intervals on test: baseline, φ_fixed, and delta (φ − baseline)
|
Метрика |
Baseline (mean) |
φ_fixed (mean) |
Δ (φ − baseline) |
95% ДИ для Δ |
|
Dice |
0,5700 |
0,6061 |
+0,0361 |
[0,0113; 0,0640] |
|
IoU |
0,5150 |
0,5462 |
+0,0312 |
[0,0031; 0,0709] |
|
Полнота |
0,5998 |
0,8148 |
+0,2150 |
[0,0899; 0,3962] |
|
Точность |
0,8598 |
0,7061 |
−0,1537 |
[−0,2541; −0,0663] |
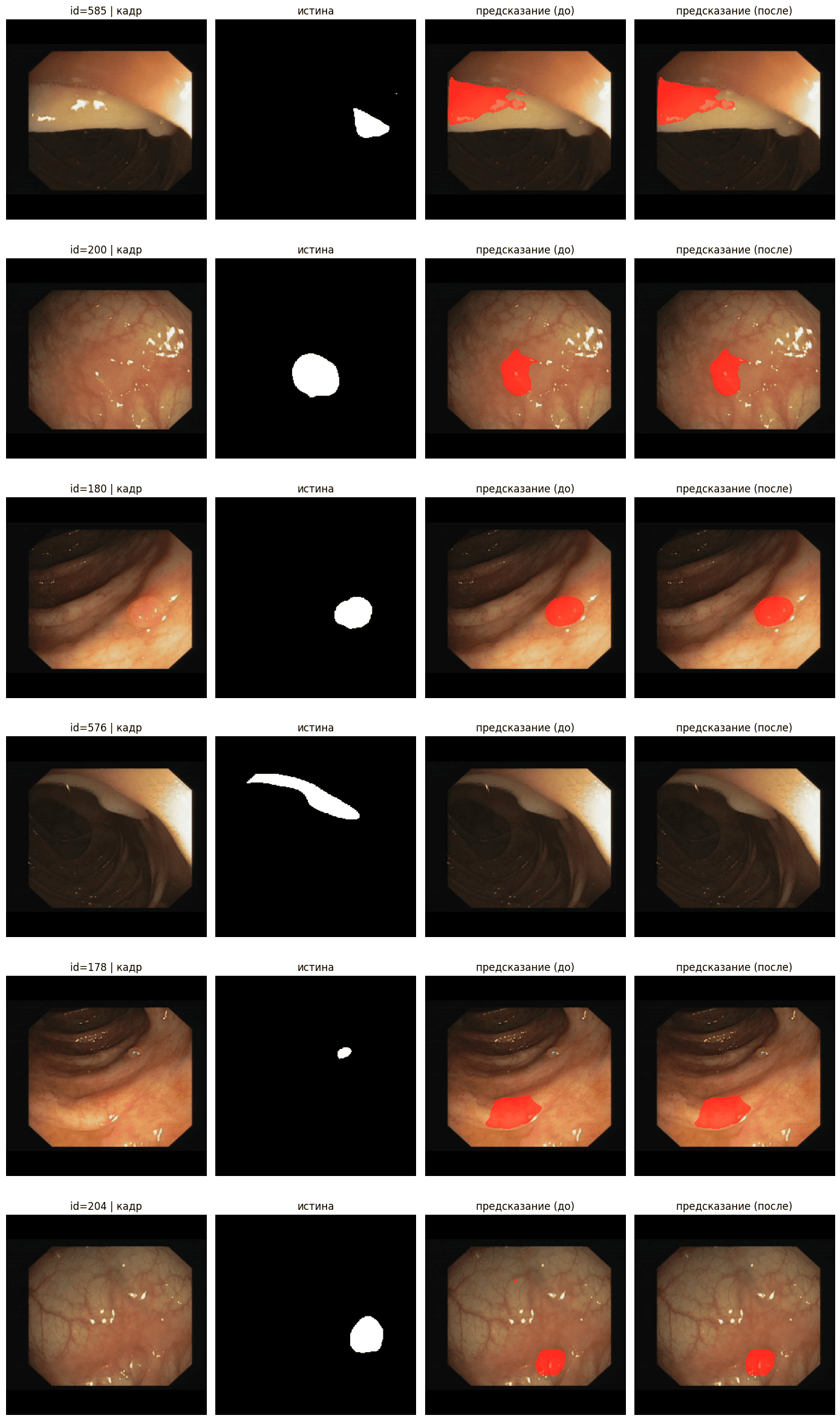
Рис. 6. Эффект постобработки: предсказание до и после выбора крупнейшей компоненты
Fig. 6. Post-processing effect: prediction before and after selecting the largest connected component
Обсуждение
Различие оптимальных порогов отражает разные режимы формирования вероятностной карты. Baseline стремится максимизировать перекрытие области и «держит» фон подавленным, поэтому лучший Dice достигается при более строгом пороге. φ-регуляризация целенаправленно повышает чувствительность на границе, улучшая сохранение тонких частей и снижая разрывы маски; при этом распределение вероятностей становится менее «пиковым», и для извлечения этого преимущества требуется более мягкий порог (Kervadec et al., 2021; Karimi, Salcudean, 2019). Важно, что мы выбираем порог на валидации и переносим на тест без подстройки: тем самым демонстрируется не просто возможность подобрать удачный порог, а устойчивое смещение решения в сторону более полного выделения объекта при контролируемом росте ложных срабатываний (Jha et al., 2021; Ji, 2022).
Рост полноты у φ_fixed на тесте сопровождался снижением точности, поэтому улучшение коэффициента Дайса нельзя интерпретировать как «однозначно более правильную» разметку во всех ситуациях. Регуляризация, привязанная к границе, по смыслу подталкивает модель включать в сегмент больше неопределенных пикселей вдоль контура, уменьшая пропуски по краю полипа; цена подобного поведения проявляется в увеличении доли ложноположительных пикселей, которые чаще возникают на бликах, складках и участках с похожей текстурой (Ji, 2022; A Survey on Deep Learning…, 2023; Guo, Bernal, Matuszewski, 2020).
Сдвиг метрик по группам размеров показывает, что выигрыш φ_fixed реализуется главным образом через средние и малые объекты, тогда как выводы по крупным полипам ограничены малым числом примеров в тесте. Малые полипы занимают доли процента площади кадра, поэтому несколько десятков «потерянных» пикселей на границе способны заметно ухудшить Дайса даже при визуально аккуратной маске. Дополнительная прибавка полноты на small при одновременном падении точности согласуется с типичной дилеммой ранней диагностики: модель либо «собирает» слабый сигнал, либо предпочитает молчать и рискует пропуском (Lou et al., 2023; Ji, 2022; A Survey on Deep Learning…, 2023).
Статистическая проверка разницы через бутстрэп, то есть повторную выборку с сохранением структуры последовательностей, дала положительный доверительный интервал для прироста Дайса и IoU, а для точности – отрицательный. Подобная картина означает, что выигрыш по полноте не выглядит случайным колебанием на отдельных роликах, а устойчиво воспроизводится на уровне последовательностей, что важно для видео-ориентированного сценария эндоскопии (Ji, 2022). Отрицательная разность по точности при этом показывает не «ошибку расчета», а систематическое смещение решения в сторону более широких масок (Jha et al., 2021; A Survey on Deep Learning…, 2023).
Постобработка через выбор крупнейшей связной компоненты снижает влияние «островков», возникающих из-за шумных вероятностей на фоне слизистой, особенно при мягких порогах. Сохранение одной компоненты улучшает читабельность результата для видеопросмотра и уменьшает количество мелких ложных подсветок, не затрагивая основной объект в кадрах с единственным полипом (Ji, 2022; A Survey on Deep Learning…, 2023). Риск для качества появляется в редких случаях, когда истинная маска распадается на две значимые области или полип частично выходит за край поля зрения, поэтому режим постобработки требует проверки на конкретном типе эндоскопических сцен (Ji, 2022).
Инженерная цена выигрыша по полноте проявляется в сценариях использования, где критичен баланс нагрузки на врача и риска пропуска. Порог 0,20 для φ_fixed дает режим «не пропустить», пригодный для подсветки подозрительных участков при первичном просмотре, но требует фильтрации ложных подсветок на потоке. Порог 0,80 у базовой модели, напротив, формирует режим «подсветка только уверенных объектов», который проще воспринимается визуально, но хуже закрывает задачу раннего обнаружения маленьких полипов (van Rijn et al., 2006; Wang et al., 2019; Repici et al., 2020; Achkasov et al., 2024).
Механизм φ-регуляризации потенциально уязвим в сценах, где граница объекта плохо определима даже для эксперта (сильные блики, выраженная складчатость, загрязнения), поскольку усиление «пограничного» штрафа может переносить часть неопределенности на фон и увеличивать FP-подсветки. Практически это означает, что для внедрения важны диагностические индикаторы: рост площади маски при снижении порога, появление множественных компонент и ухудшение калибровки вероятностей. Индикаторы позволяют заранее выбрать безопасный рабочий режим (например, порог с ограничением точности или обязательная постобработка по компонентам) и интерпретировать модель как инструмент подсказки, а не автономного детектора (Kervadec et al., 2021; Karimi, Salcudean, 2019; Ji, 2022).
Заключение
Сегментация полипов на эндоскопических изображениях с помощью глубоких сверточных сетей показала измеримый выигрыш при введении регуляризации по границе, ориентированной на мелкие объекты. Сравнение базовой модели U-Net (U-образная сверточная сеть) с энкодером ResNet-34 (остаточная сеть из 34 слоев) и модификации с использованием карты расстояний до границы (phi) выполнено на наборе CVC-ClinicDB с разбиением 506/58/48 изображений на обучение, валидацию и тест. Обучение велось с подбором порога бинаризации по валидации и с постобработкой, оставляющей крупнейшую связную компоненту, что стабилизировало маски при наличии фоновых артефактов.
Оптимальные рабочие пороги, найденные по валидации, разошлись: базовая модель дала максимум коэффициента Дайса при пороге 0,80, тогда как вариант phi_fixed достигал максимума при пороге 0,20. На тестовой части при выбранных порогах коэффициент Дайса вырос с 0,6642 до 0,7002, индекс пересечения и объединения поднялся с 0,5905 до 0,6295, полнота увеличилась с 0,6154 до 0,7723, а точность предсказаний снизилась с 0,8194 до 0,6987. Бутстрэп-оценка по идентификаторам последовательностей подтвердила устойчивость сдвига: прирост по Дайсу составил +0,0361 (95% доверительный интервал [+0,0113; +0,0640]), по индексу пересечения и объединения +0,0312 ([+0,0031; +0,0709]), по полноте +0,2150 ([+0,0899; +0,3962]) при падении точности −0,1537 ([-0,2541; −0,0663]).
Интерпретация полученных результатов сводится к управляемому перераспределению ошибок между пропусками и ложными подсветками, что важно для задач ранней диагностики. Модель с регуляризацией по границе чаще «дотягивает» маску по контуру и реже теряет небольшие участки полипа, поэтому полнота и доля пропусков улучшаются, особенно в группе малых объектов. Выбор порога остается клинически зависимым решением: режим 0,20 подходит для сценария скрининговой подсветки подозрительных зон, тогда как порог 0,80 у базовой модели дает более «строгую» визуализацию с меньшим числом ложноположительных пикселей на фоне.
Практическая ценность подхода связана с простотой внедрения в конвейер: граничная регуляризация и подбор порога по валидации не требуют изменения протокола разметки и укладываются в стандартную процедуру обучения сегментатора. Постобработка через выбор крупнейшей компоненты уменьшает влияние разрозненных ложных фрагментов и повышает читаемость наложения в клиническом просмотре. Дальнейшее развитие решения логично направить на калибровку вероятностей, оценку неопределенности и повышение устойчивости при доменном сдвиге между разными эндоскопическими стойками, режимами освещения и центрами.
Ограничения. Использование одного публичного набора данных ограничивает внешнюю валидность и не отражает весь спектр клинических условий, включая вариативность подготовки кишечника, дымку, кровь и выраженные блики. Небольшое число примеров крупных полипов в тестовой части снижает надежность выводов по крупной группе и делает средние значения чувствительными к отдельным кадрам. Чувствительность метрик к выбранному порогу подчеркивает необходимость заранее фиксировать рабочий режим под конкретный сценарий применения и проверять его на независимой выборке.
Limitations. Reliance on a single public dataset limits external validity and does not cover the full diversity of real-world endoscopy conditions, including strong specular highlights, debris, and bleeding. The small number of large-polyps examples in the test split weakens conclusions for the «large» group and increases sensitivity to individual frames. Metric dependence on the binarization threshold calls for pre-defined operating points aligned with the intended clinical workflow and validation on an independent multi-center test set.