1. Введение
Измеряемые психологами параметры, как правило, не представляют исследуемые характеристики в форме, удобной для непосредственной интерпретации и определения надежных критериев, необходимых для психологической диагностики. Поэтому в случае многомерных измерений исследователи стараются выявить несколько латентных факторов, отвечающих за изменчивость наблюдаемых параметров, и, определив их природу, использовать далее полученную информацию для анализа собранных данных.
При этом, обеспечивая минимальные потери полезной информации, параметры, которые легко измерить, по возможности заменяют на параметры, которые легко интерпретировать. При последующем анализе определяются функциональные зависимости наблюдаемых параметров от выявляемых факторов. В итоге выявляется вся структура причинных связей между факторами и наблюдаемыми переменными, а также, если потребуется, непосредственные значения факторов, необходимые для идентификации состояния испытуемых.
Для того чтобы выполнить приведенные выше требования, были разработаны эмпирические математические модели и соответствующие методы многомерного статистического анализа (Лоули, Максвелл, 1967; Bishop, Fienberg, Holland, 1975; Bollen, 1989; Goldstein, 2003; Loehlin, 1987). Наиболее приемлемыми в рассматриваемой ситуации являются исследовательские (эксплораторные) и проверочные (конфирматорные) факторные модели и методы их исследования. Оба подхода работают с выборочными матрицами ковариаций или корреляций наблюдаемых переменных. Исследовательский анализ предполагает наличие некоторого неизвестного заранее числа некоррелированных факторов с неопределенной интерпретацией2, тогда как при конфирматорном факторном анализе факторы, их интерпретация и причинные связи с наблюдаемыми переменными, а также корреляционные связи между латентными факторами определяются постановкой задачи. Конфирматорные модели позволяют с помощью несложной процедуры оценивать статистическую значимость каждого своего компонента.
Поскольку в задачах, наиболее часто встречающихся на практике, обычно известны гипотезы о причинах возможных влияний на наблюдаемые переменные, то последний подход, как правило, предпочтительней.
Во многих психологических задачах актуально исследование временной динамики наблюдаемых переменных, которые в различных контрольных точках формально рассматриваются как отдельно анализируемые величины. Для выявления статистических связей между влияющими на них факторами разработан симплекс-метод конфирматорного факторного анализа (Jöreskog, 1970). Однако практическое применение этого подхода обусловлено рядом серьезных ограничений, которые зачастую делают его использование невозможным. В частности, для анализа пригодны только ковариационные и корреляционные матрицы с симплексной структурой; факторное взаимодействие можно исследовать только для смежных контрольных точек, при этом невозможно связать факторы с периодами времени, к которым они относятся, и т. д. Кроме того, существенным недостатком традиционного конфирматорного факторного анализа является необходимость решения трудоемкой задачи многомерной локальной оптимизации для оценки величин свободных параметров модели, что, как правило, не позволяет найти глобальный минимум и приводит к неоднозначности решения.
Чтобы преодолеть указанные проблемы, был разработан представленный далее новый подход, опирающийся на возможности вейвлет-преобразований и обучаемых факторных структур. К его особенностям и преимуществам относятся:
– возможность нахождения оценок свободных параметров модели прямыми (неитерационными) методами, гарантирующими однозначное оптимальное решение;
– гибкие средства для исследования взаимодействия факторов;
– применимость для анализа ковариационных и корреляционных матриц произвольной структуры.
2. Основные этапы анализа
Основные этапы предложенного подхода представлены на рис. 1. Выборки коэффициентов, полученных в результате дискретных вейвлет-преобразований временных рядов значений исследуемого параметра и соответствующих различным периодам наблюдений, в последующем конфирматорном факторном анализе рассматриваются как значения наблюдаемых переменных, которые позволяют выявить временную историю факторных влияний и оценки факторного взаимодействия. Представление данных, полученное с помощью вейвлет-преобразований, дает возможность выявить различия в характеристиках процесса в различных шкалах, что особенно важно при большом количестве контрольных моментов времени, связанных с проведением измерений. Идентификация свободных параметров факторной модели (обычно корреляций или ковариаций) выполняется с помощью новой прямой (неитерационной) процедуры, которая опирается на метод максимального правдоподобия и является альтернативой традиционному итерационному способу решения задач локальной оптимизации.
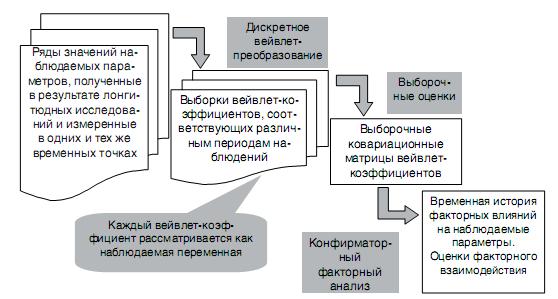
Рис. 1. Основные этапы анализа
2.1. Вейвлет-преобразования
Рабочие представления анализируемых процессов формируются с помощью вейвлетпреобразования, которое позволяет выявлять различия в их характеристиках при различных шкалах измерений на всем протяжении интервала наблюдений. Если исследуемый процесс есть функция одной переменной, то его вейвлет-спектр – функция двух аргументов, один из которых характеризует период составляющих компонентов, а другой – смещение вычисляемых показателей вдоль оси времени. Для вычисления вейвлет-спектров используются вейвлеты – особые функции в форме коротких волн («всплесков») с нулевым интегральным значением и локализацией по оси независимой переменной, способные к сдвигу по этой оси и масштабированию.
Вейвлет-анализ имеет очевидные преимущества перед традиционным спектральным анализом, поскольку он обеспечивает корректные результаты в случае нестационарных процессов и содержит более полную информацию о поведении изучаемого объекта. Это сделало данный подход популярным среди исследователей разных специальностей. Далее применялся дискретный вариант этого метода, позволивший представить анализируемые процессы в виде элементов определенного метрического функционального пространства с вейвлет-базисом.
2.2. Альтернативный вариант конфирматорного факторного анализа
Основные компоненты конфирматорного факторного анализа представлены на рис. 2.
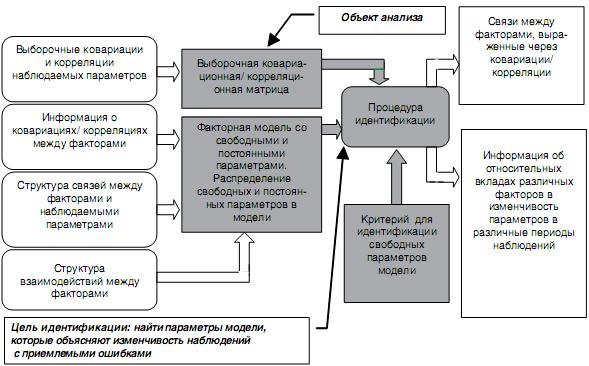
Рис. 2. Основные компоненты конфирматорного факторного анализа. (В случае нескольких типов наблюдаемых случайных процессов для вейвлет-коэффициентов формируется смешанная ковариационная матрица)
Конфирматорный факторный анализ предполагает наличие строго определенной факторной модели изучаемого явления. Факторная модель, связывающая латентные и наблюдаемые переменные, формируется, опираясь на знание предметной области. Гипотезы о структуре модели должны основываться на анализе природы исследуемых факторов. Можно делать количественные предположения о значениях факторных нагрузок и корреляциях между факторами, а также проверять гипотезы о структуре и свойствах моделей, подбирая их оптимальные варианты (Neale, Cardon, 1992). Параметры моделей подбираются так, чтобы обеспечить наилучшее, с точки зрения заданного критерия, приближение к ковариационным (корреляционным) матрицам наблюдаемых переменных.
Объектами данного вида анализа являются ковариационные или корреляционные матрицы наблюдаемых переменных. Цель работы – выявить значения параметров модели, которая с приемлемыми ошибками объясняет изменчивость наблюдений.
При использовании этого подхода:
– ненулевые (свободные) факторные нагрузки и число исследуемых факторов в модели определяются заранее;
– допускаются корреляции между ошибками измерений;
– факторные нагрузки и ковариации между латентными переменными могут быть свободными параметрами модели или приравниваться к заданным константам;
– допускается анализ нескольких групп моделей;
– можно проверять, насколько согласуются ограничения, налагаемые на параметры модели, с результатами наблюдений.
Для определения оценок свободных параметров модели методом максимального правдоподобия в качестве минимизируемого критерия используется функция
F = [ln|S| – ln|S| + tr(SS-1) – q] (N–1),
где S – выборочная ковариационная матрица наблюдаемых переменных, Ó – прогнозируемая ковариационная матрица наблюдаемых переменных, |Ó| и |S| – определители матриц Ó и S, tr(SS-1) – след матрицы (SÓ~1), N – объем выборки, использованной для вычисления матрицы S, q – число наблюдаемых переменных (Лоули, Максвелл, 1967).
Элементы прогнозируемой ковариационной матрицы представляют собой аналитические выражения относительно свободных параметров модели. В случае многомерного нормального распределения наблюдаемых переменных значения критерия Fописываются распределением ÷2.
Для определения свободных параметров модели необходимо численно решить итерационными методами достаточно трудоемкую задачу локальной многомерной оптимизации. Из этого в общем случае вытекает невозможность определения глобального минимума, так как в результате решения находится один из локальных минимумов, выбор которого зависит от начального приближения. Таким образом, решение неоднозначно.
2.2.2.
Альтернативный вариант конфирматорного факторного анализа:
основные принципы подхода
Для определения свободных параметров модели традиционный конфирматорный факторный анализ предполагает решение трудоемкой задачи многомерной локальной оптимизации. Это приводит к невозможности определения глобального минимума и неоднозначности решения. Предлагаемый альтернативный вариант конфирматорного факторного анализа позволяет находить единственное оптимальное решение прямыми (неитерационными) методами. Процедура решения включает в себя следующие этапы:
– составление переопределенной системы алгебраических уравнений, выражая выборочные дисперсии и ковариации через аналогичные факторные показатели3;
– решение полученной системы прямым (неитерационным) методом, используя метод максимального правдоподобия4 (Куравский, Корниенко, 2007; Kuravsky, Kornienko, 2007).
– проверку адекватности полученных моделей наблюдениям, опираясь на статистические критерии согласия.
Чтобы избежать составления сложных для решения нелинейных систем уравнений относительно коэффициентов корреляции и факторных нагрузок, используется путевая модель дисперсионных составляющих (Neale, Cardon, 1992), в которой факторные нагрузки равны единице. Каждой наблюдаемой дисперсии и ковариации ставится в соответствие алгебраическое уравнение, которое связывает ее выборочную оценку с соответствующей прогнозируемой величиной, выраженной аналитически через неопределенные дисперсии и ковариации латентных переменных (Bollen, 1989; Loehlin, 1987). В путевых диаграммах5 для этого, в частности, могут быть использованы правила обхода путей6. В результате получается система, число уравнений которой равно числу наблюдаемых дисперсий и ковариаций. Для вычисления оценок максимального правдоподобия и проверки адекватности модели необходимо, чтобы значения наблюдаемых переменных описывались многомерным нормальным распределением, а число уравнений в исследуемой системе превышало число свободных параметров модели.
3 Как правило, они являются свободными параметрами модели.
4 В другой форме, нежели при традиционном конфирматорном факторном анализе.
5 В путевых диаграммах (рис. 3–7 и 11) овалы (круги) соответствуют латентным переменным, прямоугольники соответствуют наблюдаемым переменным, однонаправленные стрелки соответствуют причинным связям, двунаправленные стрелки соответствуют ковариациям, дисперсиям или корреляциям.
6 Обход начинается против причинной связи, затем происходит поворот по ковариационной связи, после чего движение продолжается вдоль причинной связи. При движении запрещается дважды обходить ковариационную связь.
Представим полученную переопределенную систему n уравнений в матричной форме:
Ax=b,
где A – матрица системы, коэффициенты которой определяются факторной моделью; b – вектор-столбец n выборочных дисперсий и ковариаций, определяемых результатами наблюдений; x – вектор-столбец m искомых дисперсий и ковариаций латентных переменных.
Теперь рассмотрим вектор å =Ax*–b, представляющий полученную методом наименьших квадратов невязку псевдорешения x* переопределенной системы. Полагая в общем случае, что компоненты вектора невязок коррелированны, выразим их невырожденную ковариационную матрицу как ó2V.
Сделав замены
b=V1/2b0 и A= V1/2A0,
где V=V1/2V1/2.6, перейдем к системе A0x=b0,
ковариационная матрица вектора невязок å0=V~1/2å которой имеет вид ó2E, где E – единичная матрица.
Если рассматриваемая система невырождена (rank A = m, где m – число свободных параметров модели), вектор невязки å0 имеет многомерное нормальное распределение, а
x* = (A0TA0)-1A0Tb0 = (ATV-1A)-1ATV-1b –
псевдорешение, полученное методом наименьших квадратов, то это псевдорешение является оценкой максимального правдоподобия, а статистика X2=(b0–A0x*)T(b0–A0x*)/ó2=(b~Ax*)TV-1(b–Ax*)/ó2
имеет распределение ÷2 с n-m степенями свободы (Королюк, Портенко, Скороход, Турбин, 1985).
Указанная статистика X2 позволяет, при заданных выше предположениях, проверять гипотезу о представимости выборочных дисперсий и ковариаций, составляющих вектор b, дисперсиями и ковариациями латентных переменных, содержащихся в исследуемой модели. Область принятия гипотезы есть X2≤÷2n-m;á , где á есть уровень значимости критерия.
При реализации данного подхода удобно сделать следующие упрощающие предположения, обусловленные особенностями искомого решения:
– компоненты вектора невязок å являются некоррелированными;
– значения среднеквадратических отклонений различных компонентов вектора невязок å составляют одну и ту же фиксированную долю (процент) от соответствующих компонентов вектора b7.
Чтобы обеспечить сопоставимость оценок, указанная доля (процент) подбирается так, чтобы равенство X2= ÷2n-m;á выполнялось при á=0,05. Для оценки степени допустимости вычисленной характеристики для нее удобно установить разумное критическое значение, например, 0,1. Таким образом, вместо уровня значимости появляется новый показатель – критический процент.
Преимуществом предложенного подхода является то, что он не сводит решение к трудоемкой процедуре многомерной локальной оптимизации, которая не гарантирует нахождение глобальных минимумов, обеспечивая при этом однозначность результата.
Рассмотренный метод решения позволяет выявлять характер взаимных связей между свободными параметрами факторной модели путем прямого расчета по матричным формулам, численно вычисляя оценки одних характеристик для заданного множества сочетаний значений других.
Для ряда моделей для обеспечения корректного результата на оцениваемые дисперсии и ковариации следует налагать дополнительные условия в форме неравенств, выражающие положительность значений дисперсий и корректность соотношений между связанными дисперсиями и ковариациями. В этом случае в качестве решения принимается вектор xc, удовлетворяющий указанным условиям и ближайший к найденному псевдорешению x* в евклидовой метрике. Для поиска вектора xc решается несложная задача линейной оптимизации. Гипотеза о представимости выборочных дисперсий и ковариаций, составляющих вектор b, дисперсиями и ковариациями латентных переменных, составляющими вектор xc, проверяется, как и ранее, с помощью статистики
X2=(b–Axс)TV-1(b–Axс)/ó2,
имеющей распределение ÷2 с n-m степенями свободы.
Как и в традиционном конфирматорном факторном анализе, рассматриваемый метод дает возможность строить заключения о статистической значимости различных компонентов модели, используя статистические критерии согласия.
Для этого следует сравнить статистики X2 для двух моделей: полной модели, содержащей исследуемый компонент, и упрощенной модели, в которой этот компонент отсутствует8. Гипотезу о том, что полная модель согласуется с результатами наблюдений, будем обозначать как Hf. Выявление степени значимости исследуемого компонента производится, если отвергать гипотезу Hf нет оснований. Сначала следует оценить свободные параметры упрощенной модели. Полученное значение статистики X2 для упрощенной модели сравнивается с аналогичной характеристикой для полной модели.
Поскольку разность указанных статистик асимптотически распределена как ÷2 с числом степеней свободы, равным разности в числах степеней свободы полной и упрощенной моделей, эта разность используется для проверки нулевой гипотезы Hr о том, что упрощенная модель согласуется с результатами наблюдений, против альтернативной гипотезы Hf.
Если гипотеза Hr не отвергается при заданном уровне значимости, то исследуемый компонент признается статистически незначимым и делается вывод о том, что имеющиеся данные не свидетельствуют о его влиянии на данную характеристику. Если гипотеза Hr отвергается (а гипотеза Hf принимается), то можно говорить о влиянии исследуемого компонента на эту характеристику.
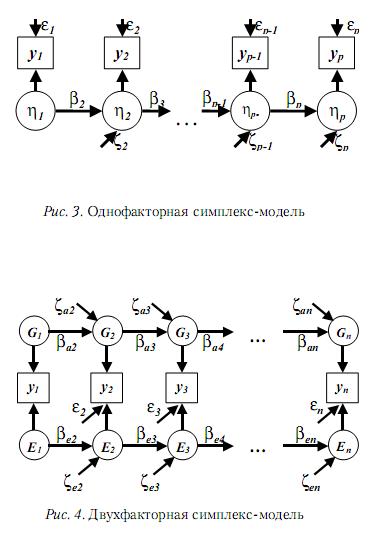
2.3. Традиционный подход к лонгитюдным исследованиям: симплекс-модели
Симплекс-модели (Jöreskog, 1970) в лонгитюдных исследованиях обычно используются в случае, когда корреляционные матрицы наблюдаемых параметров имеют симплексную структуру, что подразумевает меньшие корреляции между параметрами при больших временных интервалах между точками измерений. Примеры типичных одно- и двухфакторных симплекс-моделей представлены на рис. 3 и 4 в форме путевых диаграмм, где çi, Gi и Ei – факторы, воздействующие в i-й точке измерений, âi – факторные нагрузки, æi – случайные воздействия, некоррелированные с çi!1 (инновации), yi – наблюдаемые переменные, åi – ошибки измерений.
Связи между факторами в различные моменты времени представлены авторегрессионными зависимостями:
ηi=βi ηiJ1+ζi, Gi=βai GiJ1+ζai и Ei=βeiEiJ1+ζei.
Модели измерений выражаются как yi=λiηi+εi, где ëi – нормализующие коэффициенты для однофакторной модели и как
yi=Gi+Ei+eiдля двухфакторной модели.
2.4. Альтернативные факторные модели
для анализа результатов вейвлет-
преобразований
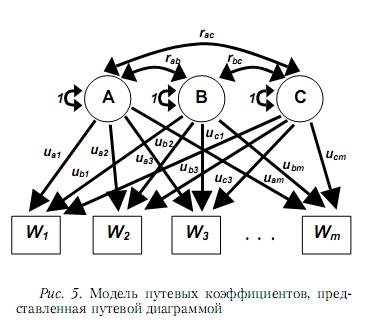
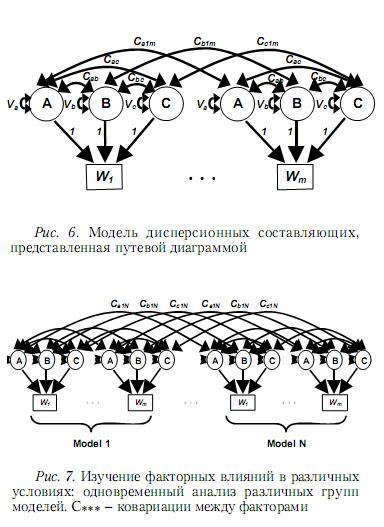
Для создания новых лонгитюдных факторных моделей, опирающихся на конфирматорный факторный анализ результатов вейвлет-преобразований, применяются модели путевых коэффициентов и дисперсионных составляющих, включая их модификации. Примеры типовых вариантов этих моделей показаны на рис. 5 и 6. Состав вейвлет-коэффициентов, используемых при анализе в качестве наблюдаемых переменных, зависит от рассматриваемой прикладной задачи и может меняться. Обычно предполагается, что число моментов времени, в которые производятся наблюдения, является степенью числа 2.
В случае модели путевых коэффициентов аналитические выражения для ковариаций и дисперсий вейвлет-коэффициентов Wi нелинейны:
Cov(Wi,Wi)= ÓÓ rklukiuij
Var(Wi)=ÓÓ rklukiuij,
где k и l – индексы факторов, u** – факторные нагрузки, r** – корреляции между факторами, что не позволяет получать простые и однозначные оценки свободных параметров модели. Подобные выражения в случае модели дисперсионных составляющих являются линейными: Cov(Wi,Wj)= Σ Ckij, Var(Wi)=Σ Vk + ΣΣ Ckl, где k и l – индексы факторов, V* – дисперсии, C** и C*** – ковариации между факторами, что дает возможность получать прямые оценки свободных параметров, используя рассмотренный выше альтернативный вариант конфирматорного факторного анализа, и применять данную модель на практике.
Отражая важные для исследования особенности прикладных задач, модель дисперсионных составляющих принимает различные частные формы. Например, при изучении факторных влияний в различных условиях может быть полезен одновременный анализ различных групп моделей (рис. 7).
Интерпретация результатов рассмотренного варианта факторного анализа обычно опирается на:
–оценки свободных9 факторных дисперсий и ковариаций;
–оценки свободных корреляций между различными факторами в одни и те же моменты времени;
–оценки свободных корреляций между одинаковыми факторами в разные моменты
времени;
–оценки статистической значимости различных компонентов модели.
Сопоставление преимуществ представленного подхода и недостатков симплекс-метода
представлено в табл. 1.
2.5. Степень переопределенности модели
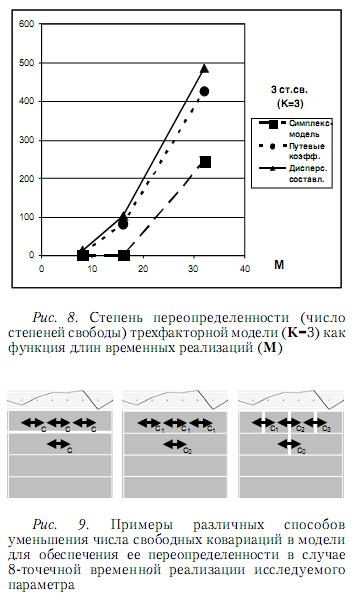
Чтобы оценить степень соответствия факторной модели накопленным результатам наблюдений, вычисляется статистика X2 , значения которой описываются распределением х2. Число наблюдаемых статистик10 должно превышать число свободных параметров модели, причем разность между этими показателями равна числу степеней свободы11 указанного распределения. Показывая число дополнительных свободных параметров, которые могут быть включены в рассматриваемую модель, число степеней свободы выражает степень переопределенности модели и является важной характеристикой возможностей ее практического применения. Выражения этой величины через длины временных реализаций исследуемых параметров и числа факторов для различных типов моделей показаны в табл. 2.
Для обеспечения переопределенности модели в случае недостаточного числа независимых наблюдаемых статистик следует сократить число свободных параметров, приравнивая их друг к другу, если это допускается имеющимися результатами наблюдений (см. пример на рис. 9).
2.6. Сингулярность модели
Если модель, построенная для решения прикладной задачи, приводит к матрице системы линейных уравнений A, ранг которой меньше, чем число свободных параметров, то псевдорешение x*=(ATV-1A)-1 ATV-1b не может быть вычислено однозначно из-за вырожденности матрицы ATV-1A. В этом случае следует уменьшить число свободных параметров модели, исключив зависимые, и обеспечить таким образом невырожденность указанной матрицы. Число подлежащих сокращению параметров равно дефекту матрицы ATV-1A. Для их определения предлагается следующий прием:
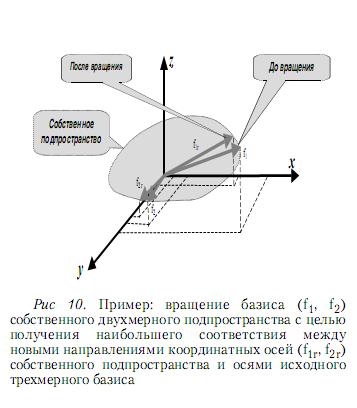
– решить алгебраическую проблему собственных значений для матрицы ATV-1A, которая по построению симметрична и неотрицательно определена, установив подпространство, заданное собственными векторами, соответствующими ненулевым собственным значениям данной матрицы;
– провести вращение базиса полученного собственного подпространства, не выходя за его пределы, с целью достижения наибольшего соответствия между направлениями координатных осей собственного подпространства и осей исходного полного базиса, что формально приведет к преобразованию координат базисных векторов в исходном пространстве либо в относительно большие, либо в относительно малые значения12 (рис. 10).
Оси исходного базиса, которые во всех выражениях для повернутых базисных векторов собственного подпространства представлены относительно малыми координатными значениями, задают направления, почти ортогональные вычисленному собственному подпространству с ненулевыми собственными значениями. Таким образом, эти направления приближенно определяют подпространство, соответствующее нулевым собственным значениям, и, следовательно, указывают на зависимые13 параметры, которые следует исключить из модели для обеспечения невырожденности матрицы. Исключение таких параметров путем выражения их через независимые характеристики или присваивания постоянных значений обычно приводит к устранению дефекта матрицы ATV-1A.
Если эти преобразования приводят к явно неприемлемой модели, то можно, сохранив ее первоначальное представление, вычислить псевдорешение приближенно, используя итерационный метод ГауссаЗейделя14 или другие подходящие методы решения систем уравнений с вырожденными матрицами.
3. Практическое применение
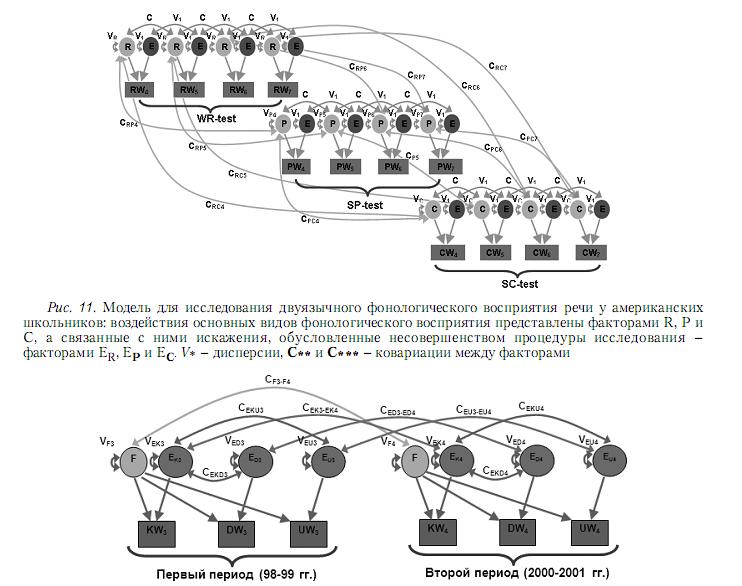
 Рассмотренный подход был реализован в среде графического программирования (National Instruments Corp., 1994–2007) и успешно применен для анализа двуязычного15 фонологического восприятия речи у американских школьников (Branum-Martin, Carlson, Carlo, Fletcher, Francis, Mehta, Ortiz, 2006) и выявления общих факторов, влияющих на социально-экономические показатели в европейских странах.
Рассмотренный подход был реализован в среде графического программирования (National Instruments Corp., 1994–2007) и успешно применен для анализа двуязычного15 фонологического восприятия речи у американских школьников (Branum-Martin, Carlson, Carlo, Fletcher, Francis, Mehta, Ortiz, 2006) и выявления общих факторов, влияющих на социально-экономические показатели в европейских странах.
Соответствующие факторные модели показаны на рис. 11 и 12. Первая модель предназначена для 8-точечных временных реализаций, а третья – для 4-точечных временных реализаций значений исследуемых параметров. В указанных приложениях наблюдаемые параметры представляют собой, соответственно, результаты психологического тестирования и объективные оценки социально-экономических показателей. Для анализа результатов психологического тестирования использовались только четыре последних по порядку из восьми вейвлет-коэффициентов, при анализе социально-экономических данных – последние два вейвлет-коэффициента из четырех, что было обусловлено особенностями прикладных задач. В модели, показанной на рис. 11, представлено воздействие основных видов фонологического восприятия (факторы R, P и C) и связанные с ними искажения, обусловленные несовершенством процедуры исследования (факторы ER, EP и EC). В модели на рис. 12 представлено влияние на исследуемые переменные общего фактора F и специфических факторов EU, ED и EK. Проведенный анализ выявил причинные и временные взаимосвязи между латентными факторами, а также уровень статистической значимости различных компонентов модели.
Таблица 1. Сопоставление преимуществ альтернативного варианта конфирматорного факторного анализа и недостатков симплекс-метода
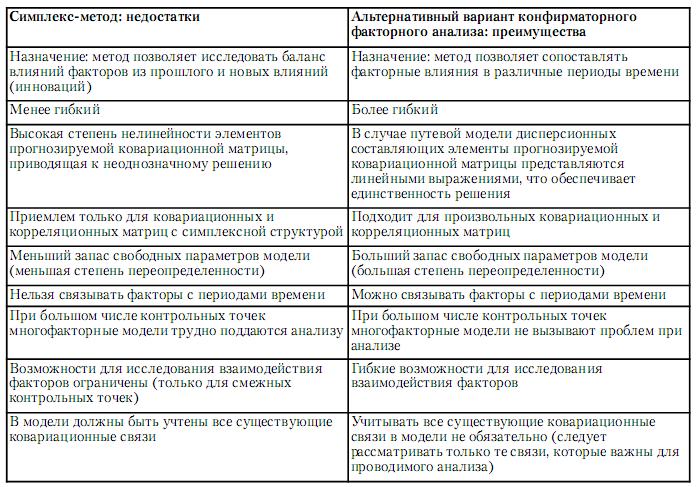
Таблица 2. Числа степеней свободы для различных типов моделей
(M=2n – длина временной реализации исследуемого параметра, K – число факторов)

Наилучшими на практике обычно оказываются модели дисперсионных составляющих. Для иллюстрации этого факта на рис. 8 представлены числа степеней свободы трехфакторных моделей как функции длин временных реализаций.
Если это целесообразно для рационального решения задачи, то в модели могут быть использованы только некоторые из вейвлет-коэффициентов.
4. Основные результаты и выводы
Предложен новый метод выявления и исследования факторов, определяющих развитие психологических характеристик, который опирается на возможности вейвлет-преобразований и обучаемых факторных структур. Согласно предложенному подходу, значения коэффициентов, полученные в результате дискретного вейвлет-преобразования временного ряда наблюдаемого процесса и соответствующие различным периодам наблюдений, рассматриваются как значения наблюдаемых переменных в последующем конфирматорном факторном анализе, который, в свою очередь, используется для выявления динамики факJ торных влияний и оценки показателей взаимодействий между факторами.
Идентификация свободных параметров факторной модели (как правило, факторных дисперсий и ковариаций) выполняется с помощью новой прямой (неитерационной) процедуры, опирающейся на метод максимального правдоподобия, что является альтернативой традиционному итерационному поиску локального решения задачи многомерной численной оптимизации, результат которого зависит от начального приближения. Основными особенности этой процедуры являются:
– составление переопределенной системы алгебраических уравнений относительно свободных параметров факторной модели с ее последующим решением методом максимального правдоподобия;
– использование путевой модели дисперсионных составляющих;
– использование вместо традиционного уровня значимости нового показателя для проверки гипотезы о представимости наблюдаемых результатов исследуемой факторной моделью, представляющего собой критический процент среднеквадратических отклонений компонентов вектора невязок от соответствующих компонентов наблюдаемых дисперсий и ковариаций;
– возможность построения заключений о статистической значимости различных компонентов модели, используя статистические критерии согласия.
Сравнение различных видов факторных структур выявило преимущества путевой модели дисперсионных составляющих. Этот факт обусловлен линейностью аналитического представления дисперсий и ковариаций наблюдаемых переменных, что удобно для прямых оценок свободных параметров, а также большей степенью переопределенности модели.
Для устранения возможной сингулярности исследуемой модели, приводящей к неоднозначности решения, разработан специальный метод выявления зависимых свободных параметров, сводящийся к решению алгебраической проблемы собственных значений и вращению базиса в невырожденном собственном подпространстве.
Предложенный подход имеет существенные преимущества перед симплекс-методом, который обычно используется для исследования факторов, определяющих динамику психологических характеристик.