Введение
В данной публикации рассматривается проблема создания инструментов, позволяющих оценивать суггестивный потенциал вербальной модели любой сложности: звукобуквы, слова, предложения, текста. Измерение и оценка качества суггестивных ресурсов сегодня востребованы в разных областях деятельности: бизнес-коммуникации и деловом общении, медиапланировании, психологической и медицинской практике, судебной экспертизе, суггестивной лингвистике, педагогической практике, политической и общественной деятельности. Результаты исследования опираются на долгосрочные экспериментальные и теоретические исследования автора, который на протяжении многих лет изучал данную проблему. В ходе работы автором и его учениками созданы пять компьютерных программ для автоматизированного анализа данных на русском, английском, немецком, татарском и башкирском языках (перечень программ приводится в конце статьи после списка источников). Рассчитаны матрицы ассоциативной цветности звукобукв пяти названных языков (Рогожникова, Кочетова, 2012; Рогожникова, Яковлева, 2016; Rogozhnikova, Efimenko, 2018). Представлена в виде полихромных картин ассоциативная цветность пяти языков (Рогожникова, Кудашов, Мустаев, 2019). Построена математическая модель для оценки информационной избыточности текста (Рогожникова, Воронов, 2016). Разработана и описана новая технология анализа суггестивного потенциала текста (Рогожникова, 2020). Предложены алгоритмы оценки суггестивного потенциала вербальных моделей разной сложности (Рогожникова, 2021). Создан алгоритм оценки ритмической организации прозаического текста разных авторов (Рогожникова, Кишалова, 2015). Описана технология кодирования информации при разных модальностях восприятия (Рогожникова, Навалихина, 2011). Продолжается работа по установлению авторской константы как идентификатора индивидуального языка автора (Рогожникова, Суетин, 2023; Рогожникова, Астафуров, 2023). В ходе исследований была выстроена логика перепроверки результатов, предполагающая определенную последовательность шагов, метаязык описания данных, а также специально разработанный инструментарий, обеспечивающий формализацию процессов декодирования ресурсов воздействия.
Данная публикация опирается на исследования, проведенные в этой области ранее. Современное языковедение изобилует трактовками явления речевого воздействия (И.А. Стернин, Е.Ф. Тарасов, П.Б. Паршин, В.Ф. Петренко, О.С. Иссерс, А.П. Журавлев, Й. Мистрик, И.Ю. Черепанова, С.В. Воронин, И.Н. Горелов, К.Ф. Седов, Р. Бендлер, Дж. Гриндер, И.М. Дзялошинский, Е.В. Шелестюк, С.Ю. Полуйкова, Л.Л. Фёдорова и другие). Авторы анализируют проблему вербальной суггестии с разных методологических позиций. Во многих работах авторская концепция речевого воздействия рассматривается как новая научная парадигма, предметом которой выступает эффективность общения. Исследователи детально анализируют правила и приемы эффективного речевого воздействия в различных коммуникативных ситуациях, предлагают варианты отработки практических риторических навыков, учитывая при этом как вербальные, так и невербальные сигналы, и стимулы в общении. Такими нормативными правилами считаются приветствия, благодарность за услугу, извинения за причиненные неудобства, выражение сочувствия и другие. Рассматриваются способы речевого воздействия (доказывание, убеждение, уговаривание, внушение, просьба, приказ, принуждение) и манипулятивные приемы. Особое место отводится коммуникативным неудачам как отрицательному результату общения. (Стернин, 2015). Немногочисленны исследования, ориентированные на изучения латентных механизмов, помогающих декодировать суггестивный потенциал вербальной модели (Черепанова, 1996; Шалак, 2004; Шелестюк, 2009).
Общим моментом, объединяющим усилия разных исследователей, является проблема вербального воздействия, изучаемая с разных позиций. Принципиальным отличием нашей работы от предыдущих исследований является изучение скрытого (неявного) потенциала вербальной модели любой сложности через разработку специального пула предиктивных инструментов. Коммуникативные неудачи потому и случаются, что крайне трудно получить положительный результат (даже при соблюдении нормативных правил), если вербальная модель – носитель отрицательного суггестивного потенциала, который не проявлен и не является очевидным. Исследователи, изучающие речевое воздействие, сталкиваются с объективным дефицитом аналитического инструментария, который позволил бы им изучать столь сложное полимодальное явление с исходных позиций базового филологического образования. Получение объективных и достоверных результатов, которые возможно перепроверить, осложняется рядом препятствий методологического порядка. Методы лингвистического анализа, применяемые для работы с лексико-синтаксическими средствами, малопригодны не только для точного анализа потенциала суггестивной компоненты, но даже для операциональных процедур перекодирования названной компоненты с внутреннего кода на ее внешнюю вербализацию. Сегодня в активном научном обиходе такие сочетания как «коммуникативное воздействие», «манипуляции» или «манипулятивные воздействия», «вербальное воздействие». Исследователи разграничивают виды речевого воздействия, проводя границы между персуазивным (воздействие через апелляцию к сознанию, механизмам осознанного восприятия) и суггестивным воздействием (латентное воздействие через апелляцию к подсознательным неосознаваемым структурам).
Речевое воздействие анализируется через изучение различных речевых средств, через эстетические коды словесного творчества, через анализ средств графического оформления текста. Обращаются также к изучению сообщений, выстроенных с помощью паралингвистических средств (мимика, позы, жесты), к изучению особенностей функционирования названных знаковых систем для создания вербальных моделей с повышенной способностью воздействия на сознание и поведение другого человека. Сегодня социальная востребованность в «оптимизации речевого воздействия» является одним из основных стимулов, побуждающих к интенсивным исследованиям в этой области.
Рабочей гипотезой настоящего исследования стало допущение о причинной зависимости между качественными и количественными показателями глубинных латентных характеристик вербальной модели (паттернами ритмов мозга, ассоциативной цветностью, свойствами информационной избыточностью модели, категориально-статистическими оценками, статусом эмоционального состояния, ритмическими кодами сложных моделей и многими другими). Важными результатами работы, которые впервые описываются в данной публикации, являются установленные в ходе экспериментов законы действия и законы воздействия вербальных моделей и пути формализации их суггестивных ресурсов.
Процедура декодирования суггестивного потенциала вербальных моделей разного уровня сложности предполагает использование понятий, требующих точного определения. Под вербальной моделью в данном исследовании понимается материализованная структура любой сложности – звукобуква, слово, текст, являющаяся носителем внутренней формы, через проявления которой во внешнем контексте реализуются латентные ресурсы воздействия конкретных моделей. Суггестивный потенциал – латентная «сила вербальной модели», которая может быть декодирована, измерена и представлена в количественных показателях. Потенциал соотносится с внутренней формой, существующей благодаря механизму ассоциирования. Суггестивные ресурсы трактуются как совокупность воздействующих элементов, которыми обладает конкретная модель и обсуждать которые возможно с помощью аналитических единиц, выявленных для уровней, позволяющих производить количественные замеры, сопоставлять получаемые показатели и сравнивать характеризующие признаки. Минимальной единицей анализа выбрана звукобуква, под которой понимается полимодальная сущность, воспринимаемая посредством нескольких сенсорных каналов (аудиального и визуального). Для говорящего человека звук становится осознаваемой реальностью только после соотнесения его с буквой. Именно поэтому неизвестный набор звуков, воспринимаемый аудиально, без визуального образа, не даёт полной информации из-за минимальных различий в признаковых оболочках.
Материалы и методы
Результаты исследования были получены с помощью ряда методов и технологий, среди которых важное место занимают различные виды ассоциативных экспериментов. Подробное их описание и полученные экспериментальные данные опубликованы (Галерея ассоциативных портретов, 2009; Ассоциативный словарь башкирского и татарского языков, 2016).
В ходе работы были также задействованы методы, которые могут рассматриваться как новые только для гуманитарных парадигм, поскольку в технических областях они имеют давнюю традицию. Отметим наиболее значимые.
Метод распределения частотности вербальных единиц. Опорой для исследований в этой области стали законы Ципфа, описывающие закономерности частотного распределения слов в тексте на любом языке. Одна из статистических закономерностей вербальных моделей состоит в том, что буквы естественного языка встречаются с разной частотой, что позволяет прописать последовательность появления буквы в порядке убывания частот.
Метод распределения избыточности. Основой для создания алгоритма анализа послужила математическая теория информации Шеннона (Шеннон, 1963), которая, являясь разделом прикладной математики и информатики, позволяет измерять количество информации, содержащееся в символе. Часто употребляемые буквы обладают меньшей информацией, чем редкие. Технология использовалась автором статьи в судебной экспертизе для анализа вероятности различных трактовок данных.
Метод анализа электрических сигналов. Электрический сигнал выделяется с помощью специальной аппаратуры, обрабатывается и замеряется, при этом для активации сигналов используются внешние вербальные раздражители. Особый интерес представляют паттерны мозговой активности. Для исследований ритмов мозга используется 16-канальный электроэнцефалограф, многофункциональный компьютерный комплекс. Для анализа электроэнцефалографических (ЭЭГ), электромиографических (ЭМГ) сигналов и вызванных потенциалов (ВП) – "Нейрон-Спектр-2". Для изучения эмоциональных состояний и реакций на вербальные модели оказались полезными показатели электро-кожной активности – кожно-гальванической реакции (КГР) и кожного потенциала (КП), получаемые с помощью анализатора медленной электрической активности мозга «АМЕА».
Метод анализа ритмических кодов вербальных моделей. В ходе исследований установлено, что тексты с разной ритмической структурой обладают различным суггестивным потенциалом. Создана компьютерная программа ПУЛЬС, позволяющая произвести расчеты среднеквадратичного отклонения слого-акцентного оберритма текста и среднеарифметического показателя всех безударных слогов, вывести общее количество гласных и количество безударных гласных в тексте, количество межударных интервалов и количество ударений в тексте, представить результаты расчетов в графическом виде в прямоугольной системе координат (Декартовы координаты), где наглядно видны ритмические скачки анализируемого текста.
Методики изучения ассоциативной цветности вербальных моделей. Технологии изучения психологической цветности (как части устройства ментального лексикона) опираются на достижения в области фоносемантики, психосемантики цвета и потенциала звукоцвета. Ассоциативная цветность вербальных моделей анализируется при помощи созданных компьютерных программ БАРИН, БАТЫР, БЮРГЕР на русском, английском, немецком, башкирском и татарском языках. Для каждого из пяти языков созданы ассоциативные цветовые матрицы. Автором разработаны два подхода к анализу ассоциативной цветности. Важным результатом проделанной работы являются модели, представленные в виде цветовых картин, в которых в равных долях закодированы психологические цвета всех звукобукв названных выше языков.
Метод изучения модальности восприятия. Технологии изучения языковых явлений в контексте полимодальности восприятия опираются на модели восприятия и позволяют устанавливать изменения, происходящие в процессе кодирования информации об окружающем мире.
Метод лингвистической статистики и шкалирования. Данные технологии являются важным дополнением к экспериментам. Шкалирование позволяет выявлять латентные структуры с использованием количественных показателей и их графическим представлением. Статистический анализ помогает строить уравнения корреляционной зависимости, уравнения множественной регрессии, уравнение зависимости по значимым характеристикам.
Технологии ранжирования можно использовать как промежуточный этап сбора/анализа данных и как методику количественных измерений в соответствии с определенными критериями. Сегодня пока нет доказательных рекомендаций по оптимальному количеству объектов ранжирования, но имеются исследования с указанием границ целесообразности применения технологий.
В числе методов и технологий был использован новый метод, разработанный и введенный в научный обиход автором публикации – процедура синкризы.
Метод проведения синкризы. Новая технология представляет собой основанный на сравнении полимодальных данных «детектор», позволяющий оценивать когерентность эмоционального состояния человека тому дискурсу, который порождается им. Если установлена согласованность, синкриза характеризуется как положительная. Если выявлен диссонанс, синкриза считается отрицательной, что в частности свидетельствует о желании человека скрыть информацию, закамуфлировать смысл или свое отношение к сказанному.
Результаты
В результате экспериментальной и теоретической работы установлены 10 аналитических единиц и был сформирован и описан пул предиктивных инструментов, которые могут быть использованы для установления, измерения и описания суггестивных ресурсов вербальной модели любой сложности: звукобуквы, слова, текста. Вербальную модель можно анализировать сквозь призму возникающих при ее восприятии мозговых волн (ритмические паттерны мозга), через активизацию доминантных эмоций человека (мимический сервис и трактовки микроэкспрессий лица), через анализ ассоциативной цветности модели и потенциал звукоцвета (цветовые матрицы созданы для пяти языков), через модальности восприятия, в соответствии с которыми кодируется информация, с помощью показателей электрического сопротивления кожи человека, воспринимающего вербальную модель, и показателей информационной избыточности модели, с помощью эмоционально-оценочных признаков и процедуры синкризы, через ритмические коды сложных вербальных моделей, с помощью авторского инварианта как постоянного параметра индивидуального языка. Сегодня в арсенале десять компьютерных программ, пять из которых созданы автором, его учениками и коллегами, шестая находится в стадии разработки. С их помощью возможно работать на 5 языках (русском, английском, немецком, татарском и башкирском).
Рассмотрим на конкретном примере суггестивный потенциал самой сложной вербальной модели – текста. Для иллюстрации была выбрана наиболее рельефная и выразительная модель, обладающая большим суггестивным ресурсом – молитвенный текст. Разнообразие дискурса побуждает группировать тексты по общности основания. Молитвенные тексты представляют собой одну из таких уникальных групп. Анализировались около тысячи молитвенных текстов на русском, башкирском и татарском языках.
В рамках статьи проанализируем текст – одну из Молитв Оптинских Старцев: «Господи, дай мне с душевным спокойствием встретить все, что принесет мне наступающий день. Дай мне всецело предаться воле Твоей святой. На всякий час сего дня и наставь и поддержи меня. Какие бы я не получил известия в течение дня, научи меня принять их со спокойной душой и твердым убеждением, что на все святая воля Твоя. Во всех словах и делах моих руководи моими мыслями и чувствами. Во всех непредвиденных случаях не дай мне забыть, что все ниспослано тобой. Научи меня прямо и разумно действовать с каждым членом семьи моей, никого не смущая и не огорчая. Господи, дай мне силу перенести утомление наступающего дня и все события в течение дня. Руководи моею волею и научи меня каяться, молиться, верить, надеяться, терпеть, прощать, благодарить и любить всех. Аминь».
Анализ текста с помощью новой версии компьютерной программы DIATONE, разработанной в лаборатории профессора И.Ю. Черепановой (список используемых компьютерных программ приведен в конце публикации), обнаруживает следующий паттерн мозговой активности (Рис. 1). Текст относится к разряду вербальных моделей идеального комплексного воздействия.

Рис. 1. Ритмы мозга, активизируемые текстом – Молитва Оптинских Старцев
Fig. 1. Brain rhythms activated by the text – A pray of Optina Elders
Анализ ассоциативной цветности обнаруживает доминирование ярко-оранжевого, золотистого и малинового цветов (Рис. 2).

Рис. 2. Ассоциативная цветность текста – Молитва Оптинских Старцев
Fig. 2. Associative color of the text – A pray of Optina Elders
Проведенный с помощью психолингвистической экспертной системы ВААЛ (R) (Шалак, Дымшиц, 2005) контент-анализ текста, включающий среди прочих показателей эмоционально-лексические оценки, позволил оценить эмоциональный фон текста. Модуль компьютерной программы по оценке эмоционального профиля опирается на оценку каждого слова по пятнадцати шкалам, как правило биполярным, но не обязательно симметричным. Каждое слово оценивается по всем пятнадцати шкалам. Эмоционально-лексические оценки определяются через расчет средних величин по каждой из шкал. Если оценка положительная, то строка гистограммы окрашена в красный цвет, если отрицательная – синий. Внизу приведены число эмоционально-оценочных слов (в данном тексте – 19), процент таких слов от всех слов анализируемого текста (15,1%), норма процента эмоционально-оценочных слов в русском языке (6,8%). Анализируемый текст молитвы высоко эмоционален, характеризуется высокими показателями доброжелательности, самоконтроля, независимости, правдивости и отсутствием показателей агрессивности, эгоизма, демонстративности.
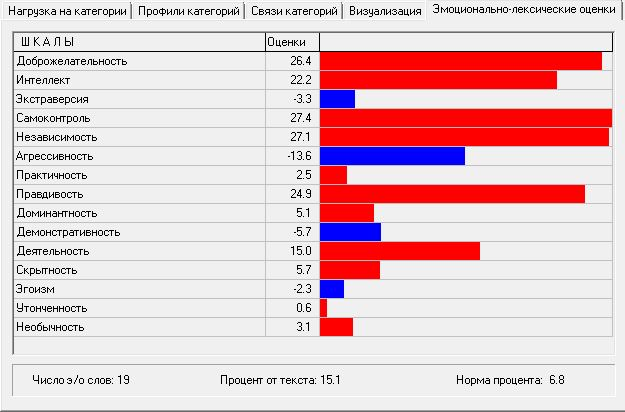
Рис. 3. Эмоциональный профиль текста – Молитва Оптинских Старцев
Fig. 3. Emotional profile of the text – A pray of Optina Elders
Важным показателем потенциала сложной вербальной модели является частотность использования в ней звукобукв. В каждом символе содержится определенное количество информации. Математическая теория информации американского инженера Клода Шеннона, являясь разделом прикладной математики и информатики, позволяет измерить количество информации, содержащееся в символе (Шеннон, 1963). Алфавит языка представляет собой уникальную структуру, единицы которой содержат разное количество информации. Количество информации в звукобукве зависит от частоты ее употребления в конкретном языке. Редко употребляемые буквы обладают большей информацией, чем частотные.
Специальный модуль компьютерной программы UNIVERSAL, которая в настоящее время разрабатывается, позволяет сравнить показатели частотности появления буквы в тексте с нормативными показателями её использования в языке (Рис. 4).
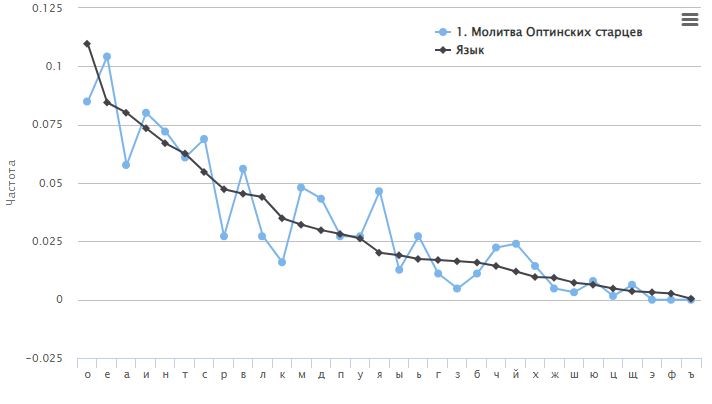
Рис. 4. Показатели частотности букв в тексте – Молитва Оптинских Старцев и в языке
Fig. 4. Frequency of letters in the text – A pray of Optina Elders and in the language
По показателю частотности текст молитвы значительно отличается от языковой нормы. Это свидетельствует том, что текст будет воздействовать на человека иначе, чем «нормативный» текст, показатели которого приближаются к норме.
Показатель частотности сопряжён с информационной избыточностью текста, которая в контексте данного исследования понимается как насыщенность единиц текста, его плотность, не связанная с содержанием и индивидуальным смыслом напрямую. Можно предположить, что скопление или, наоборот, дисперсия отдельных информационно насыщенных/ненасыщенных единиц приводят к воздействию на человека еще до того, как он понял его содержание. Уместно привести пример воздействия различных заговорных текстов, смысл которых часто бывает не понятен, при этом анализ показывает значительную разницу между текстом заговора и языковой нормой.
Избыточность трактуется как понятие, противоположное понятию информативности: чем выше избыточность вербальной модели, тем ниже ее информативность. При равной вероятности всех букв алфавита достигается нулевая избыточность и максимальная информативность любого текста. Эффективность текста может определяться через его информативность: чем более информативен текст, тем более он полезен. Таким образом, мы можем предположить, что низкий показатель избыточности – положительная характеристика текста. Математические расчеты позволили сделать вывод о том, что избыточность ниже 0.00597 – низкая, выше 0.009592 – высокая (Рогожникова, Воронов, 2016). Показатель избыточности текста – Молитва Оптинских Старцев равен 0.0038, что свидетельствует о низкой избыточности, что подтверждает полезность текста.
Заслуживает внимания оценка текста через шкалу признаков. Были использованы две разных компьютерных программы для оценки значимых признаков текста (программа ВААЛ, 2005; программа ДИАТОН (СЛОВОДЕЛ), 2008). Получены практически идентичные результаты. На Рис. 5 представлена накопленная гистограмма, которая основана на пошаговом анализе 25 фрагментов текста, структурированных таким образом, что каждый следующий за первым столбик гистограммы является совокупностью предшествующих оценок. Так создается накопленная оценка. Признак текста «Светлый» достигает показателя + 17, усреднённый показатель равен +15.1.
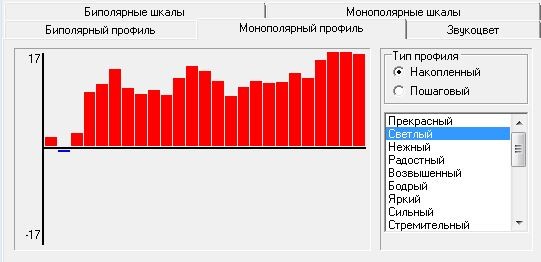
Рис. 5. Количественный показатель признака «Светлый» (Молитва Оптинских Старцев)
Fig. 5. Quantitative marker «Light» (A pray of Optina Elders)
Признаковый анализ с помощью программы ДИАТОН (Рис. 6) показал, что доминантным признаком текста является признак «Светлый» (+15,21), следующим по значимости выявлен признак «Нежный» (+10,12).
Таким образом, на основе проведенного анализа можно сделать вывод о том, что Молитва Оптинских Старцев – текст идеального комплексного воздействия, который характеризуется ассоциативной цветностью, свойственной молитвенным текстам (ярко-оранжевый, золотистый, малиновый), положительным эмоциональным профилем, низкой избыточностью, положительными доминантными признаками (Светлый, Нежный).
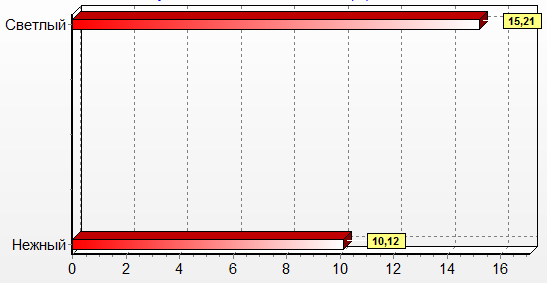
Рис. 6. Количественный показатель признака «Светлый» (Молитва Оптинских Старцев)
Fig. 6. Quantitative marker «Light» (A pray of Optina Elders)
Обсуждение результатов
Результаты анализа подтверждают рабочую гипотезу о том, что суггестивный потенциал вербальных моделей поддается декодированию с помощью специальных инструментов, которые позволяют расшифровывать латентное содержание воздействующих ресурсов. Была установлена причинная зависимость между качественными и количественными показателями скрытых характеристик вербальной модели. Например, если паттерны ритмической активности мозга свидетельствуют о положительном воздействии, то с высокой долей вероятности можно предполагать, что ассоциативная цветность модели, её эмоциональный профиль, показатели избыточности, характеризующие признаки будут иметь положительные маркеры. Такая вербальная модель может быть отнесена в разряд моделей с высоким потенциалом положительного и благотворного воздействия. Несомненно, что текст Молитва Оптинских Старцев – пример такого текста с положительным суггестивным ресурсом, восприятие которого оказывает на человека высококачественное и полезное воздействие. Как показывает анализ, все молитвенные тексты активизируют положительные паттерны мозговых волн, при этом проверка доброкачественности таких текстов подтверждается проведением процедуры синкризы, которая позволяет сравнивать разные параметры, не подлежащие сопоставлению при других обстоятельствах. Работая с текстами молитв на татарском и башкирском языках, мы не имели возможности получить данные о ритмике мозговых волн (пока нет таких программ для названных языков), но по анализу ассоциативной цветности, ритмической организации текстов и по результатам проведения процедуры синкризы с высокой вероятностью можно делать заключения о значительном положительном суггестивном ресурсе данных текстов.
Полученные результаты становятся еще более убедительными, когда проводится анализ текстов, противоположной направленности и также отклоняющихся от языковой нормы – заговорных текстов (это различные заговоры, остуды, отсушки, привороты). Рисунок ритмической активности меняется на жесткое отрицательное воздействие, в палитре ассоциативной цветности доминируют иные цвета, признаки вербальной модели резко меняют своё качество. Такие тексты рассматриваются нами как вербальные модели с негативным суггестивным ресурсом, оказывающим на человека отрицательное воздействие. Безусловно, латентная сила текста может быть разной по количественным и качественным показателям.
В данной публикации мы обратились к примерам «полярных» текстов. Молитвенные и заговорные тексты противоположны по своей направленности и по своему воздействию на человека. Не менее интересны вербальные модели, чей потенциал трудно выявить из-за малых отличий от языковой нормы. Анализ текстового массива «Речи политиков прошлых лет» обнаружил интересные закономерности. Впервые была описана «отрицательная синкриза» и дано объяснение этому явлению.
В результате проведенного исследования были сформулированы законы действия и законы воздействия вербальной модели, краткое описание которых впервые приводится в рамках настоящей публикации.
ЗАКОНЫ ДЕЙСТВИЯ СЛОВА
ЗАКОН 1. Семантическое пространство слова, существующее как состояние и форма ассоциативной материи, развивается по спирали, диаметры витков которой расширяются по мере взросления человека. Проверен на данных многочисленных экспериментов, проводившихся на протяжении 40 лет в широком возрастном диапазоне на русском, белорусском, словацком, английском, татарском, башкирском языках.
ЗАКОН 2. Семантическое пространство слова в не типичных и отличных от нормы условиях эволюционирует или инволюционирует в соответствующем этим условиям формате, который в базовой части всегда отражает спиралевидную форму семантических изменений. Экспериментально проверен в условиях нормы, патологии, одарённости, при разных модальностях восприятия и различных личностных установках.
ЗАКОН 3. Семантическое пространство слова в геронтогенезе инволюционирует, трансформируясь подобно перевернутому зеркальному отражениию раскрутки витков спирали, которые уменьшаются в диаметре по мере увеличения возраста. Экспериментально проверен в возрастном диапазоне испытуемых от 80 до 90 лет на материале русского языка. Имеются также согласующиеся с данным результатом подтверждения, полученные зарубежными коллегами.
ЗАКОНЫ ВОЗДЕЙСТВИЯ ВЕРБАЛЬНЫХ МОДЕЛЕЙ
ЗАКОН 1. Вербальная модель любого уровня сложности (звукобуква, слово, текст) обладает суггестивным потенциалом разного уровня. Уровень потенциала можно измерить и выразить в количественных и качественных показателях с помощью специально созданных для этих целей инструментов.
ЗАКОН 2. Суггестивный потенциал наиболее сложной вербальной модели (уровень текста) характеризуется системным (эмерджентным) эффектом и неустойчивой матрицей суггестивности. Текст как суггестивная система обладает особыми эмерджентными свойствами, которые не присущи составляющим ее частям и компонентам – предложениям, словам, звукобуквам. Свойства текста как воздействующей системы не могут быть сведены к сумме свойств ее компонентов.
ЗАКОН 3. Суггестивный потенциал сложной вербальной модели (уровень слова) характеризуется свойствами эмерждентности и устойчивой матрицей суггестивности. Слова с разным суггестивным потенциалом как модели со стабильными показателями воздействия могут быть востребованы как единицы анализа в отдельных случаях.
ЗАКОН 4. Суггестивный потенциал наименее сложной вербальной модели (уровень звукобуквы), эмерждентные свойства которой не проявляются при поэлементном анализе, обладает устойчивой матрицей суггестивности и может рассматриваться сегодня как универсальная минимальная (атомарная) аналитическая единица. Дальнейший поэлементный анализ сегодня невозможен, поскольку нет данных о сложной структуре звукобуквы, которая обладала бы эмерджентным эффектом. К значимым фактам относится конечность количества звукобукв в любом языке, что делает их пригодной единицей анализа.
ЗАКОН 5. Текст как воздействующая модель обладает устойчивым постоянным суггестивным потенциалом. При изменении фрагментов (отдельных компонентов) текста суггестивный заряд изменяется и становится динамичным.
ЗАКОН 6. Слово как воздействующая модель обладает статичными и устойчивыми фоносемантическими и ритмическими суггестивными ресурсами. С возрастом человека меняется его реакция на суггестивный ресурс, которым обладает данная единица.
ЗАКОН 7. Звукобуква как воздействующая модель обладает самыми статичными и устойчивыми фоносемантическими и ритмическими суггестивными ресурсами вне зависимости от возраста человека. Активация суггестивного потенциала звукобуквы происходит в раннем детстве и сохраняется подобно «встроенному» суггестору на протяжении всей жизни.
Формулировки законов предполагают внимание исследователей к вопросу о статусе разных уровней языка в суггестивной иерархии. Анализируя потенциал звукобуквы, мы подходим к атомарной или минимальной на сегодняшний день единице, которая обладает суггестивным ресурсом, поддающимся инструментальным измерениям и численным выражениям. Результаты нашей работы согласуются с исследованиями других авторов, чьи усилия направлены на структурирование языковых уровней с учетом их воздействующего потенциала (работы С.В. Воронина, И.Ю. Черепановой, И.Н. Горелова, Л.П. Прокофьевой, Е.В. Шелестюк).
Заключение
В ходе исследований была подтверждена рабочая гипотеза о том, что латентное содержание воздействующих ресурсов поддается декодированию с помощью предиктивных инструментов, что существует причинная зависимость между качественными и количественными показателями глубинных скрытых характеристик вербальной модели (паттернами ритмов мозга, ассоциативной цветностью, свойствами информационной избыточности модели, категориально-статистическими оценками, статусом эмоционального состояния, ритмическими кодами сложных моделей и другими). Скрытый воздействующий потенциал вербальных моделей поддается количественным измерениям и описанию по показателям качества суггестивных ресурсов (от максимально отрицательных до максимально положительных). Разработанная автором процедура синкризы позволяет описывать неявную обусловленность различных параметров скрытого потенциала и на основе установленных закономерностей рассчитывать ресурс воздействия. В ходе анализа установлены законы действия и воздействия вербальных моделей разного уровня сложности (звукобуква, слово, текст). Созданы 5 компьютерных программ для автоматизированного анализа данных на русском, английском, немецком, татарском и башкирском языках. Рассчитаны матрицы ассоциативной цветности звукобукв пяти языков. Представлена в виде полихромных картин ассоциативная цветность пяти языков. Разработана и описана новая технология анализа суггестивного потенциала текста. Построена математическая модель для оценки информационной избыточности текста. Предложены алгоритмы оценки суггестивного потенциала вербальных моделей разной сложности. Продолжается работа по установлению авторской константы как идентификатора индивидуального языка автора.
Прогностические технологии исследования языковых явлений сегодня востребованы в разных областях деятельности: деловой коммуникации, медиапланировании, судебной экспертизе, педагогической, психологической и медицинской практике, суггестивной лингвистике, политической и общественной деятельности. Для этих областей мы может предложить решение следующих задач: оценивать суггестивный (воздействующий) потенциал и суггестивные ресурсы текста, то есть латентную «силу вербальной модели»; декодировать и измерять в числовых показателях «опасность» или «безопасность» созданного продукта (спонтанной речи, подготовленного выступления, любого письменного документа, письма, поэтического или прозаического произведения, рекламного продукта, газетной публикации, религиозного текста); создавать тексты с заранее заданными характеристиками, которые будут определенным образом воздействовать на сознание и подсознание индивида или целой аудитории; экспертно анализировать текст, уже созданный другим автором; устанавливать скрытые мотивы и намерения автора речевого продукта; фиксировать доминирующие эмоции, изменения эмоционального состояния; прогнозировать психологический статус, потребности, желание власти, страх власти, доброжелательность или агрессивность.
К наиболее перспективным проектам, непосредственно связанным с проблемой суггестивного потенциала, мы относим два проекта.
Первый из них направлен на обработку визуальной информации и эмоциональные вычисления. В эпоху полимодальности текста проблема становится особенно актуальной, поскольку новый формат видеороликов (клипы, рилсы, шортсы) стал популярным контентом в интернете и привлекает внимание аудитории. Системы детекции и распознавания эмоциональных состояний сегодня быстро развиваются (Бобе, Конышев, Воротников, 2016; Экман, 2018). Предложенная автором процедура синкризы позволяет через установление доминантных эмоций говорящего человека в видеотексте обсуждать латентный потенциал его речевого продукта. Текст «накладывается» на доминантные эмоции. В судебной экспертизе такие прогностические практики позволяют устанавливать показатели «правдивости» и «искренности» автора текста.
Второй проект, который в настоящее время активно разрабатывается автором статьи в тесном сотрудничестве с математиками и специалистами в области информационных технологий, системными аналитиками, направлен на поиск подсознательно закодированной информации об особенностях индивидуального языка автора текста. Предпринимается попытка установить авторскую константу как постоянный параметр, характерный для идиостиля автора текста.