В статье приводится сравнение методов снижения размерности применительно к профилям скорости звука в морских волноводах. Приводятся методы, основанные на машинном обучении. Производится сравнение методов и выбор наиболее подходящего метода для решения данной задачи.
1. ВВЕДЕНИЕ
Для расчета скорости звука в океанической среде используется формула Вильсона [http://oalib.hlsresearch], предложенная им в 1960 году. График (см.рис.1.1), показывающий зависимость скорости звука от глубины, будем называть вертикальным распределением скорости звука (ВРСЗ). Так как для формулы Вильсона нужно очень много информации об океанической среде, в основном используются приближенные модели, например, профиль Munka - идеализированный профиль скорости звука. Такой профиль считается как среднее значение скорости в океанической среде - 1500 м/с умноженное на гладкую функцию [http://oalib.hlsresearch]. Этот подход имеет малое отношение к реальности, так как результат получается очень усредненным.
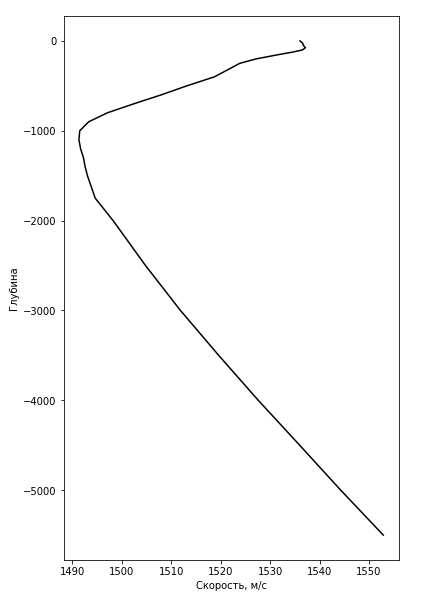
Рис.1.1 Профиль скорости звука ВРСЗ
В данной статье был предложен подход, основанный на алгоритмах машинного обучения. Похожая работа была проделана в [Dictionary learning of]. Данная работа была дополнена методом, основанном на применении нейронных сетей.
В работе используются методы unsupervised learning (обучение без учителя). При таком подходе известно только описание объектов (обучающей выборки), и требуется обнаружить внутренние закономерности, зависимости между объектами. Такой подход позволяет снизить размерность за счет выделения только наиболее важной информации из данных.
Для решения данной задачи были рассмотрены следующие методы:
1. Метод главных компонент.
2. Метод k-means (к средних).
3. K-SVD (Singular value decomposition).
4. Нейронные сети.
2. ПОСТРОЕНИЕ МОДЕЛИ И ЧИСЛЕННЫЙ ЭКСПЕРИМЕНТ


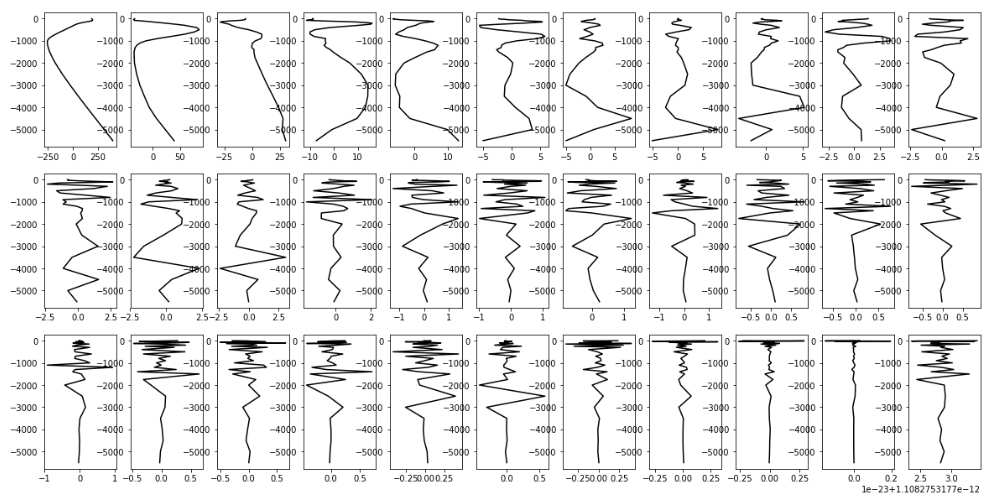
На рисунке 2.1 представлен набор главных компонент для профилей скорости звука.
На рисунке 2.2 приводится сравнение исходного вектора из тестовых данных и его аппроксимации по 1, 3 и 5 главным компонентам. В таблице 2.1 представлено среднеквадратическое отклонение исходного тестового вектора от аппроксимированного.
Таблица 2.1
|
Количество компонент |
Среднеквадратическое отклонение |
|
1 |
2,03 |
|
3 |
1,486 |
|
5 |
0,15 |
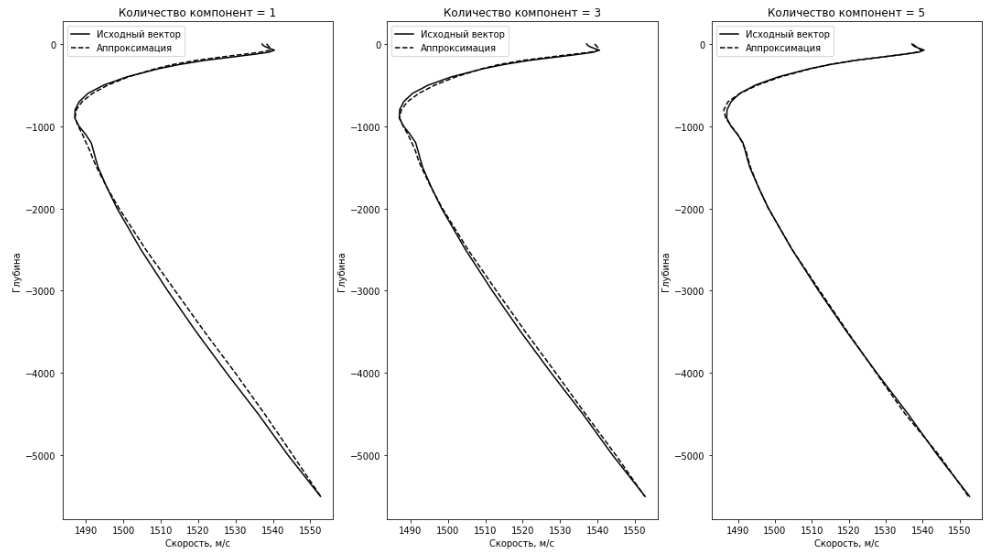
Рис.2.2. Исходный вектор ВРСЗ и его аппроксимация методом PCA
K-means
В машинном обучении метод k-means является методом кластеризации данных (присвоение каждому элементу выборки метку из конечного числа кластеров заранее неизвестных). Несмотря на это, можно провести параллели между алгоритмом k-means и PCA. Если метод PCA пытается представить данные в виде суммы главных компонент, то метод k-means напротив, пытается представить каждую точку данных в пространстве, используя центр кластера. Разбивая n-мерное пространство выборки ВРСЗ на k кластеров, каждый вектор ВРСЗ кодируется в k-мерном пространстве по принципу one-hot-encoding, то есть кодируется вектором из k элементов, в котором на i-ом месте стоит единица, а все остальные нули, где i - номер кластера к которому принадлежит данный профиль ВРСЗ.
В таблице 2.2 представлено среднеквадратическое отклонение исходного вектора из тестовых данных от вектора, являющегося центром ближайшего кластера.
Таблица 2.2
|
Количество кластеров |
Среднеквадратическое отклонение |
|
1 |
35,22 |
|
3 |
5,64 |
|
5 |
7,38 |
|
8 |
0,83 |
|
10 |
3,38 |
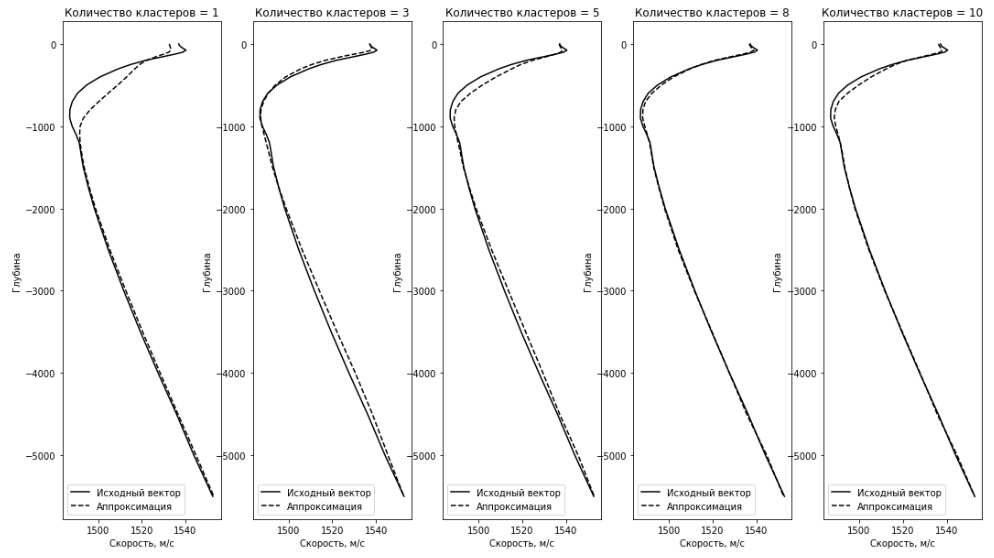
Рис.2.3. Исходный вектор ВРСЗ и его аппроксимация методом k-means
Данный метод кодирования хоть и не самый точный, но зато позволяет получить очень разреженное представления данных, что во многих задачах бывает очень практично.
K-SVD
K-SVD - еще один способ получить разреженное представления данных. Это частный случай метода под названием dictionary learning. Он позволяет эффективно находить словарь (набор базисных векторов ВРСЗ из обучающей выборки) с помощью SVD разложения и является своего рода обобщением метода k-means. В отличии от k-means, K-SVD позволяет получать кодированный вектор с заранее заданным количеством ненулевых элементов. В методе K-SVD решается следующая задача оптимизации:

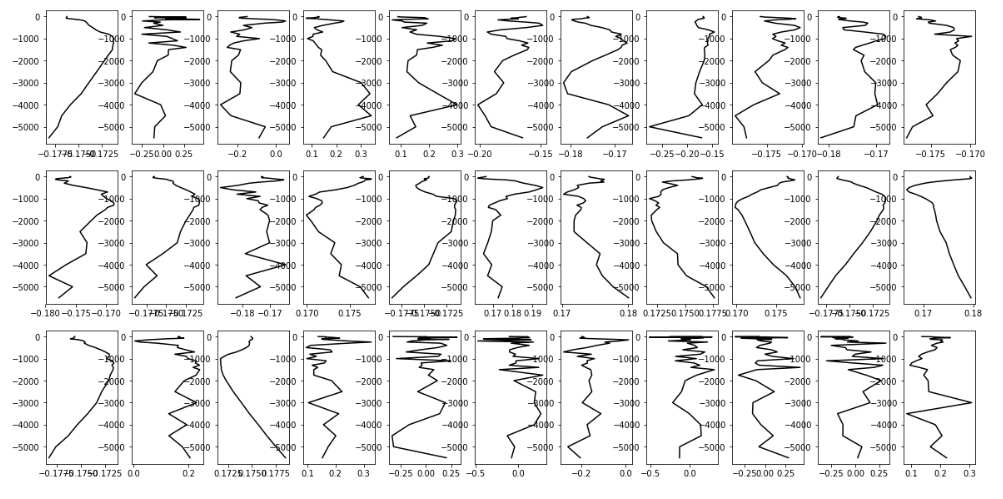
Рис.2.4. Словарь, полученный методом K-SVD
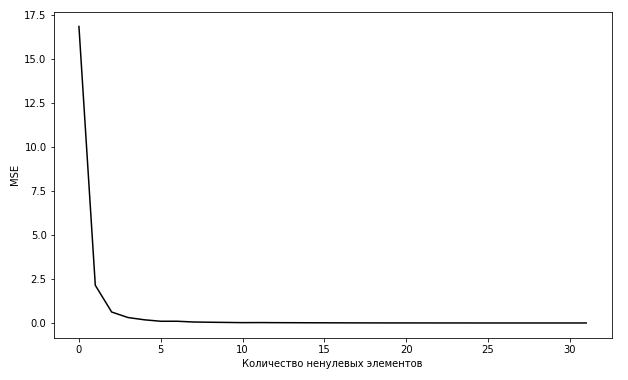
Рис.2.5. Зависимость ошибки аппроксимации от количества ненулевых элементов.
Как видно из графика кривой ошибки обучения, показанного на рисунке 2.5, точность перестает заметно увеличиваться уже при T0 = 5 .
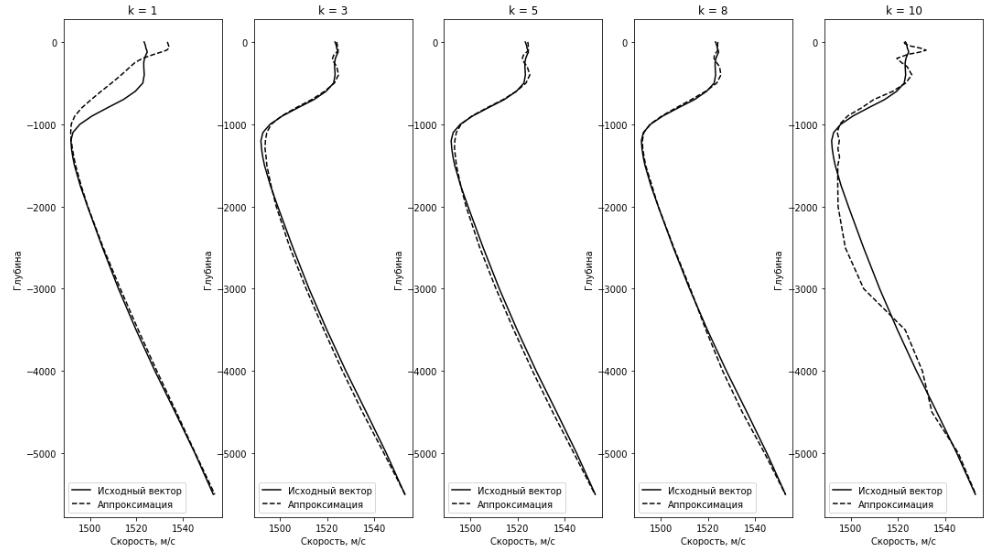
Рис.2.6. Исходный вектор ВРСЗ и его аппроксимация методом K-SVD
Таблица 2.3
|
K |
Среднеквадратическое отклонение |
|
1 |
49.7 |
|
3 |
1 |
|
5 |
1.07 |
|
8 |
0,82 |
|
10 |
10.72 |
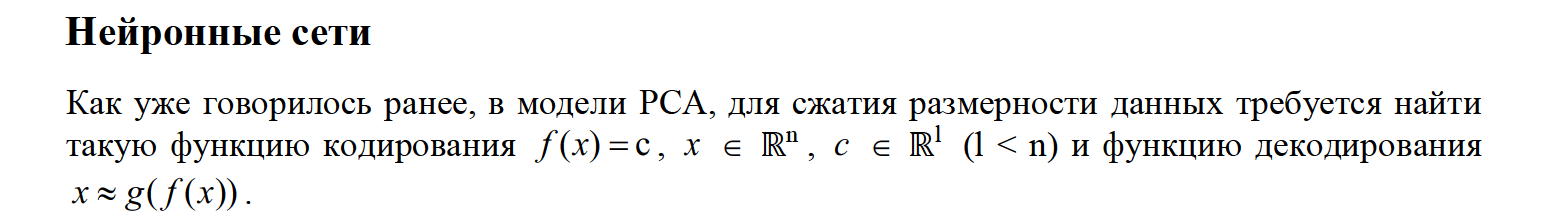
Теорема Цыбенко
Искусственная нейронная сеть прямой связи с одним скрытым слоем может аппроксимировать любую непрерывную функцию многих переменных с любой точностью. Условиями являются: достаточное количество нейронов скрытого слоя [Approximation by Superpositions].
Данная теорема утверждает, что мы можем аппроксимировать функцию f(x) и g(c) с любой точностью.
Для данного типа задач существует специальная архитектура нейронной сети под названием autoencoder (автокодировщик). Она состоит из двух частей: кодирование и декодирование.
На рисунке 2.7 приведена архитектура автокодировщика с одним скрытым слоем кодирования и одним скрытым слоям декодирования.
Методом обратного распространения ошибки, нейронную сеть можно обучить кодировать данные в пространство меньшей размерности (нужно всего лишь минимизировать среднеквадратическое отклонение между исходными векторами и векторами на выходе нейронной сети). Выбирая количество нейронов на скрытом слое C, будем задавать размерность пространства, в которое перейду профили ВРСЗ.
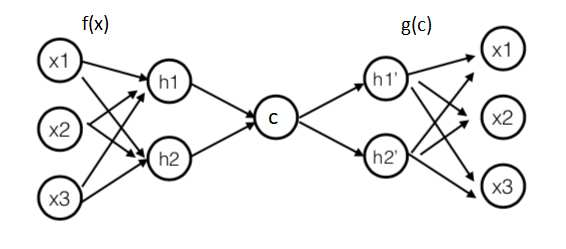
Рис.2.7 Архитектура autoencoder (автокодировщик)
После обучения нейронной сети, обрезав вторую часть, которая отвечает за декодирование данных, и оставив только часть, отвечающую за функцию кодирования f(x), будем подавать на вход сети профили ВРСЗ и на выходе будем получать закодированные вектора размерности скрытого слоя С. Так как у нас остался обученный декодер g(c), мы в любой момент можем восстановить (с потерей точности конечно) профили ВРСЗ прогнав их через сеть декодера.
Таблица 2.4
|
Размер скрытого слоя C |
Среднеквадратическое отклонение |
|
1 |
1.18 |
|
3 |
2.12 |
|
5 |
1.6 |
|
10 |
1.3 |
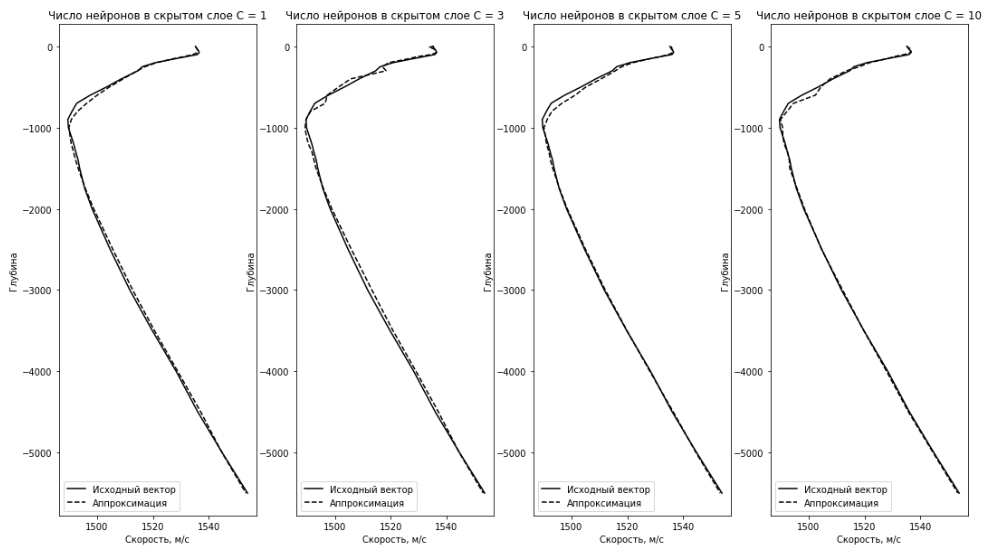
Рис 2.8. Исходный вектор ВРСЗ и его аппроксимация с использованием autoencoder.
Сеть обучалась методом обратного распространения ошибки на 150 эпохах и алгоритмом оптимизации adam.
3. ЗАКЛЮЧЕНИЕ
Сравним на одном графике результаты всех четырех моделей:
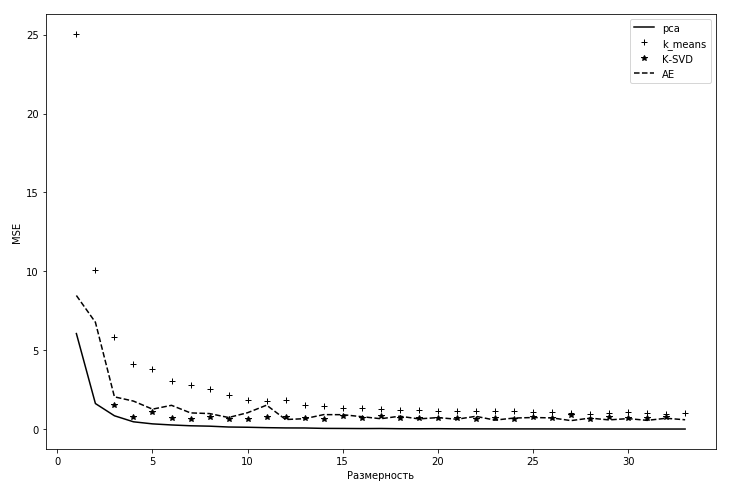
Рис 3.1. Сравнение четырех моделей
Как видно из графика, метод PCA лучше всех проявил себя при решении данной задачи. Как и ожидалось, K-SVD более точнее, чем k-means, так как является его обобщением. Хоть PCA и показал более точные результаты на тестовых данных, все равно есть смысл применять метод K-SVD, за счет разреженных кодируемых данных.
БЛАГОДАРНОСТИ
Автор благодарит за помощь в исследовании научного руководителя проекта М.В. Лебедева.