· упрощение поисковой системы – прокачка индексов/семантический поиск/расширение поисковых запросов;
· реферирование текстов;
· классификация/кластеризация документов;
· выделение признаков (интерпретируемых топиков) для рекомендательных систем и поведенческого анализа;
· рекламные системы – контекстная реклама и выделение коммерческих интересов [Augenstein, 2017].
В представленной работе объектом исследования является набор текстов (документов), описывающих товары, представленные в онлайн каталоге интернет-магазина OZON. Предмет исследования – методы извлечения ключевых слов.
Цель работы – извлечение ключевых слов из описаний товаров, что приведет к упрощению их поиска. Для этого были проработаны сопутствующие задачи:
1. Проанализированы полученные данные.
2. Разработан метод для извлечения ключевых слов из документов.
3. Проведен вычислительный эксперимент.
4. Оценена эффективность работы модели.
Математическая постановка задачи
Перед нами стоит задача извлечения ключевых слов, для ее решения рассмотрим исходные данные. Предоставляется коллекция документов, связанная общей тематикой (новости, рассказы, статьи и т.д.) – . Каждый документ состоит из набора слов , где – это количество слов в документе . Цель – выделить ключевые слова/фразы ( – это количество ключевых слов в документе d), состоящие из , которые будут описывать смысловую часть заданного документа . При этом искомые ключевые слова/фразы могут быть заданы изначально или вовсе неизвестны.
Схема эксперимента для решения задачи представлена на рисунке 1. В основу метода входит модель тематического моделирования – LDA. Для получения наиболее быстрых и качественных результатов данные обрабатываются стандартными методами, а также посредством статистической меры IDF. Непосредственное извлечение ключевых слов происходит на последнем этапе.
|
Данные |
|
Предварительная обработка |
IDF |
|
LDA |
|
Извлечение ключевых слов |
Оценка модели |
Рисунок 1. Схема эксперимента
Далее рассмотрим каждый пункт по отдельности, предварительно ознакомившись с теоретической основой и базовыми понятиями, применяемыми в работе с текстом, а также непосредственно в тематическом моделировании.
Предобработка
Для решения задач NLP данные первым делом подвергаются предварительной обработке. Ее цель заключается в очищении текста от незначимых и неинформативных данных, что упрощает и облегчает работу. Правильная предварительная обработка в первую очередь сказывается на качестве оценки результатов. Далее опишем базовые способы, применяемые к текстам в качестве предварительной обработки.
В первую очередь из текстов убирается вся пунктуация, так как анализу подлежат непосредственно слова. Далее слова приводятся к нижнему регистру поскольку одно и то же слово, написанное в разных регистрах, моделью будет восприниматься как два разных слова. Получившиеся тексты подвергаются токенизации. Токенизация – это задача разделения текста на части, называемые токенами, таким образом каждый документ можно представить в виде списка слов или словосочетаний, из которых он состоит.
Далее данные подвергаются лемматизации или стеммингу. Лемматизация – это приведение слов к нормальному виду. Например, слово «красивое» будет преобразовано в «красивый», слово «убежал» в «убежать». Данные преобразования считаются наиболее точными, но как правило занимают больше времени. Стемминг – это процесс отбрасывания окончаний или других изменяемых частей слов. Например, слово «красивое» будет преобразовано в «красив», а слово «убежал» в «беж». Подобные преобразования занимают меньше времени, но могут приводить к спорным результатам, так как урезав большую часть слова может быть утерян его смысл и урезанное слово будет в дальнейшем трактоваться некорректно. Следует отметить, что стемминг в большей степени применяется к английским словам, так как лексически выдает более точные результаты, чем при применении к словам русского языка. В конечном счете после лемматизации/стемминга алгоритму проще воспринимать связь между словами и анализировать их, так как одно и то же слово, представленное в разных падежах, регистрах или времени, должно восприниматься одинаково, так как имеет как правило идентичную смысловую нагрузку.
Следующим шагом осуществляется удаление стоп-слов. Под стоп-словами подразумеваются слова, которые часто встречаются во всех документах или в документах представленной тематики. Они считаются общими и теряют свою ценность за счет частоты, так как явно не являются ключевыми для документов и потому не несут смысловой нагрузки. Также в список стоп-слов могут быть включены слова, которые, наоборот, крайне редко встречаются. Если слово было встречено всего один раз во всей коллекции документов, то оно также имеет малую эффективность в анализе, поэтому подобные слова следует исключить.
Перечисленная обработка является фундаментальной для работы с текстами, но в отдельных случаях могут потребоваться дополнительные преобразования. К примеру, помимо отдельно стоящих слов можно выделять устойчивые фразы, словосочетания автоматическими методами или же рассматривать для анализа только определенные части речи, также с помощью регулярным выражений можно избавиться от лишних данных.
TF-IDF (сокращение от term frequency — inverse document frequency) – это статистическая мера для оценки важности слова в документе, который является частью коллекции.
Для ее расчета вычисляются меры TF (term frequency — частота слова), и IDF (inverse document frequency — обратная частота документа). При этом TF оценка слов меняется от документа к документу, а IDF оценка слова одинаковая для слов внутри каждого документа.
TF оценивает частоту некоторого слова внутри документа по следующей формуле:
(1)
где – число вхождений слова t в документ, а в знаменателе — общее число слов в данном документе.
IDF оценивает обратную частоту документов, включающих в себя некоторое слово и выражается в представленной ниже формуле.
(2)
где — число документов в коллекции, — число документов из коллекции , в которых встречается
Таким образом для оценки слов с помощью TF-IDF перемножаются две рассмотренные меры, и по итогу вес некоторого слова пропорционален частоте употребления этого слова в документе и обратно пропорционален частоте употребления слова во всех документах коллекции.
- (3)
Больший вес по TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах. Мера TF-IDF часто используется в задачах анализа текстов и информационного поиска, например, как один из критериев релевантности документа поисковому запросу, при расчёте меры близости документов при кластеризации.
Тематическое моделирование
Тематическое моделирование – одно из современных направлений обработки естественного языка. Тематическая модель коллекции текстовых документов определяет к каким темам относится каждый документ и какие слова образуют каждую тему. Алгоритм описывает темы дискретным распределением вероятностей слов, а документы – дискретным распределением вероятностей тем. Такой подход напоминает кластеризацию, однако, отличие в том, что при кластеризации документ целиком относится к одному кластеру, тогда как тематическая модель осуществляет мягкую кластеризацию, разделяя документ между несколькими кластерами.
Исходные данные – коллекция текстовых документов D, при этом каждый документ d из D представляется как последовательность термов , где – количество термов документа d. Термами считаются слова, словосочетания, цифры или иные сущности, которые входят в документ, в зависимости от того какой предварительной обработке подверглись документы. Предполагается, что каждый документ описан одной или несколькими темами, а темы различаются частотой употребления отдельных термов. Таким образом коллекцию документов можно представить в виде последовательности троек . . Так как термы и документы известны, на их основе предполагается выявить темы. В связи с этим требуется найти:
1) число тем;
2) слова, характерные для каждой темы, и их распределения;
3) принадлежность документов к темам.
Ниже представлены задачи, которые можно решить с помощью данной модели:
· ранжирование документов по заданной тематике;
· ранжирование документов по степени сходства с заданными документом;
· определение тематики различных сущностей (конференций, журналов и т.д.);
· определение тематики авторов.
Для решения задачи необходимо определить основные предположения вероятностных тематических моделей. Так, предполагается, что:
· порядок документов в коллекции не влияет на результат;
· порядок термов внутри документа также не влияет на результат – используется «мешок слов»;
· термы, которые часто встречаются во всех документах, не имеют смысловой нагрузки и поэтому удаляются из списка (стоп-слова);
· слова, написанные в разных формах, считаются одинаковыми и приводятся к одному виду;
· каждая тема описывается неизвестным распределением на множестве термов ;
· каждый документ описывается неизвестным распределением на множестве тем ;
· гипотеза условной независимости . Она предполагает, что появление термов в документе d по теме t зависит непосредственно от темы и описывается общим распределением [Коршунов Антон, Гомзин, 2012].
Распределение термов в документе описывается вероятностной смесью распределений термов в темах с весами .
(4)
Для поиска приближенных значений матриц и максимизируется логарифм правдоподобия:
(5)
Для максимизации (5) вычисляется EM-алгоритм, в котором итерационно чередуются E и M шаги. Рациональный алгоритм представлен на рисунке 2, где - вероятности термов w в каждой теме t; вероятности тем t в каждом документе d; число троек, в которых терм w связан с темой t; число троек, в которых терм документа d связан с темой t; - число троек, связанных с темой t; - число троек, в которых терм w документа d связан с темой t; длина документа d в термах; - число вхождений терма w в документ d [Апишев, 2020].
|
|
Вход: коллекция D, число тем |T|, начальные приближения матриц и Выход: параметры и |
|
1 |
Повторять |
|
2 |
Обнулить , для всех , ; |
|
3 |
Для всех |
|
4 |
; |
|
5 |
Увеличить , на для всех |
|
6 |
для всех , ; |
|
7 |
для всех , ; |
|
8 |
Пока и не сойдутся; |
|
|
|
Рисунок 2. Рациональный EM-алгоритма для тематической модели
Данный алгоритм называют EM-алгоритмом, где на E-шаге (expectation) происходит оценка условного распределения латентных тем по формуле Байеса для всех терминов в документах, а на M-шаге (maximization) по этим вероятностям вычисляются частотные оценки матриц .
Аддитивная регуляризация и LDA
Для решения проблем неустойчивости и неединственности используются регуляризаторы. На искомое решение накладываются дополнительные ограничения. Аддитивная регуляризации или подход ARTM основан на идее многокритериальной регуляризации, при котором вводятся еще n критериев , . Взвешенная сумма всех таких критериев:
(6)
где – неотрицательный коэффициент регуляризации, максимизируется совместно с основным критерием правдоподобия:
(7)
Задача решается также EM-алгоритмом, модифицируя M шаг следующим образом:
, (8)
. (9)
LDA (latent Dirichlet allocation – латентное размещение Дирихле) является наиболее цитируемой моделью тематического моделирования. Основная идея заключается в предположении, что матрицы Θ и Φ являются случайными векторами и порождаются распределением Дирихле с гиперпараметрами и соответственно:
(10)
(11)
где – гамма-функция, и столбцы матриц и , а и – коэффициенты регуляризации. Параметры распределения Дирихле связаны с математическим ожиданием порождения случайных векторов: [Воронцов, 2014].
В терминах ARTM модель LDA выражается через сглаживающие регуляризаторы следующим образом:
(12)
Подставив данный критерий формулу M-шага, получим новое его представление:
, (13)
. (14)
Реализация эксперимента
Цель работы заключается в упрощении навигации по сайту путем извлечения ключевых слов из описаний товаров. В качестве данных имеется набор annotations из 400 тысяч описаний, характеризующих товары онлайн магазина OZON. Так как у анализируемых данных отсутствуют искомые, заранее известные ключевые слова, то точность эксперимента будет оцениваться как эмпирически, так и за счет заранее отобранных данных, для которых ключевые слова уже прописаны. Таким образом мы имеем три набора данных: annotations – обучающая выборка и 500N-KPCrowd-v1.1, SemEval2017 – тестовые выборки.
Набор данных annotations состоит в общей сумме из 29,5 млн слов, из них 260 тысяч уникальных. Описания представлены на русском языке. На рисунке 3 продемонстрирована частота встречаемых слов в документах. Как видно большая часть встречается только один раз.
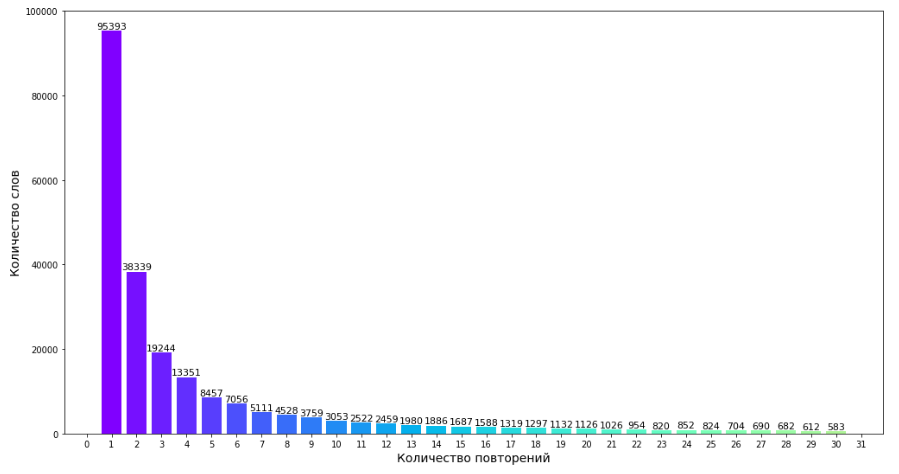
Рисунок 3. Частота встречаемых слов в документах
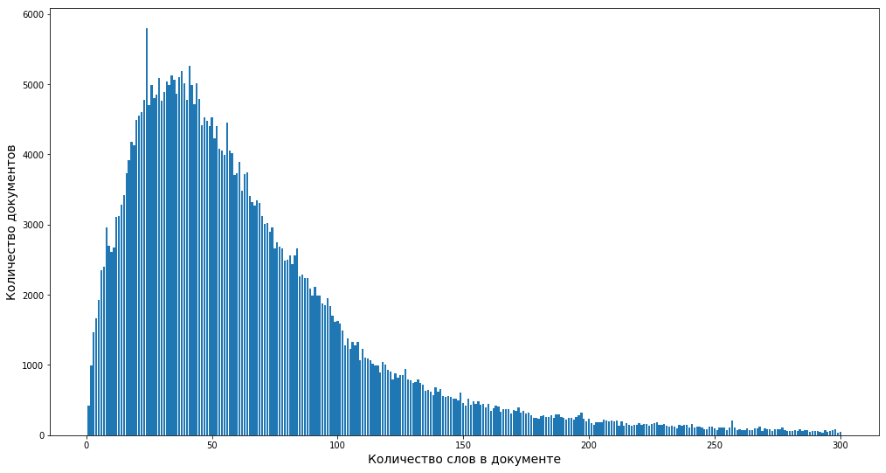
Рисунок 4. Частота слов в документе
Рисунок 4 показывает количества слов в документах. В среднем описание товара состоит из 20-25 слов.
Набор данных 500N-KPCrowd-v1.1 представляет собой сводку новостей вместе с заголовками. Датасет описан на английском языке. Для каждой новости есть определенный набор заданных ключевых слов. Всего представлено 500 новостных статей.
Набор SemEval2017 состоит из 500 документов, выбранных из журнальных статей ScienceDirect, равномерно распределенных по областям информатики, материаловедения и физики. Статьи представлены на английском языке
В таблице 1 приведены основные характеристики рассматриваемых датасетов.
Таблица 1. Характеристики датасетов
|
Данные |
Язык |
Количество документов |
Количество слов |
Количество уникальных слов |
|
annotations |
Русский |
400000 |
29.5 млн |
260 т |
|
500N-KPCrowd-v1.1 |
Английский |
500 |
116 т |
16 т |
|
SemEval2017 |
Английский |
500 |
49 т |
8 т |
Предобработка данных осуществлялась с помощью языка программирования python. На этапе предобработки с помощью регулярных выражений данные почистили от пунктуации html-тэгов, а также удалили слова, состоящие из одного буквы. Токенизация и удаление стоп-слов было осуществлено с помощью библиотека nltk. Для приведения слов к единой форме была использована лемматизация из nltk.stem.WordNetLemmatizer() и pymorphy2.MorphAnalyzer(). По итогу обработки получили релевантные данные для каждого документа. Во-первых, данных стало гораздо меньше, что способствует ускорению работы алгоритмов, во-вторых, сами слова представлены в удобном виде, подлежащем анализу.
Следующим этапом применялся статистический метод IDF для отбора кандидатов, наиболее информативных слов. Получив результаты, слова с наибольшими и наименьшими значениями IDF были удалены, так как первые можно отнести в группу стоп-слов, которые слишком часто встречаются, а вторая группа наоборот – редкие единичные слова, которые также не подлежат анализу.
Итоговые данные были переведены в формат BOW (Bag-of-words) и разбиты на темы с помощью тематического моделирования. Для реализации была использована модель LDA с аддитивной регуляризация из библиотеки BigARTM. Bag-of-Words или мешок слов — это модель, часто используемая при обработке текстов, представляющая собой неупорядоченный набор слов, входящих в обрабатываемый текст. В этой модели документ представляется в виде мешка его слов с сохранением информации об их количестве [Воронцов].
В ходе эксперимента данные были разбиты на 150 тем. На рисунке 6 представлена визуализация тем, для наглядности выведены по два слова из 13 тем. Для визуализации за основу была взята матрица , в которой хранятся вероятности попадания слова в определенную тему. Размерность матрицы была уменьшена до 2 с помощью t-SNE - алгоритм машинного обучения, базовый принцип которого заключается в сокращении попарных расстояний между точками при сохранении их относительного расположения. Иными словами, алгоритм отображает многомерные данные на пространство более низкой размерности, при этом сохраняя структуру соседства точек.
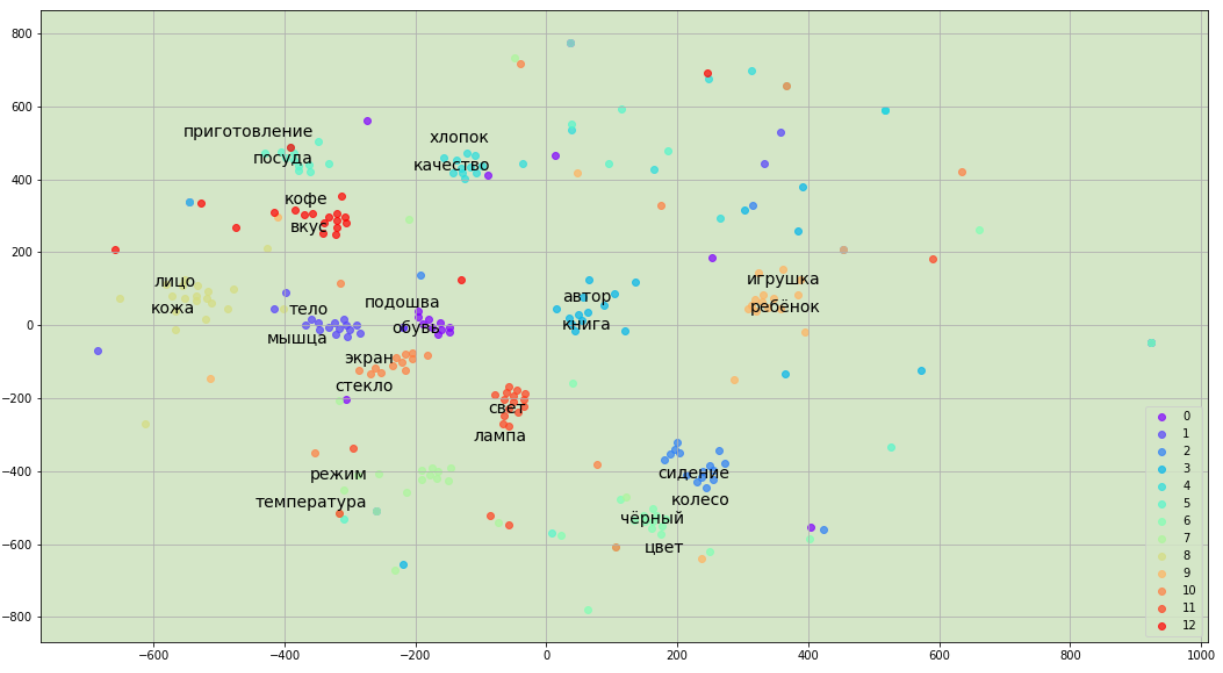
Рисунок 6. Распределение тем
Для удобства было выведено по 30 первых слов в каждой теме. График напоминает задачу кластеризации, как и было упомянуто выше. Есть слова, которые строго попадают под свою тематику, а также слова, которые находятся в промежуточном состоянии, так как могут с приблизительно одинаковой вероятностью относится к нескольким темам одновременно.
Результаты эксперимента
По итогам работы модели каждому документу были присвоены топ 3 темы наиболее подходящие и из каждой темы выделены топ 3 слова. Пример отобранных ключевых слов показан на рисунке 7.
|
Коврик-пазл "Сказочная принцесса" - увлекательная, развивающая игрушка, на которой малыш сможет лежать, сидеть, ползать и играть. Коврик состоит из двадцати четырех текстурированных сегментов, с красочным изображением принцесс, цифр от 0 до 9 и других волшебных предметов. Таким образом, в игровой форме малыш развивает не только визуальное и тактильное восприятие предметов, но и в игровой форме научится счету. Коврик помогает развитию мелкой моторики, воображения, мышления и пространственного восприятия ребенка. Коврик-пазл создан из экологически чистого полимерного материала – ЭВА (этиленвинилацетат). Основные достоинства: - хорошо амортизирует - гипоаллергенный - не электризуется - легкий - стойкий к воздействию химических веществ - препятствует образованию и размножению грибка, а также болезнетворных бактерий Для детей с 10 месяцев Размер коврика в собранном состоянии: 62 х 93 х 1 см Размер упаковки: 32 х 32 х 6 см
|
Рисунок 7. Пример отобранных ключевых слов для описания

На рисунке 7 представлено описание товара «коврик-пазл «Сказочная принцесса». Каждая тема показана отдельным цветом. Ключевые слова «коврик», «материал» и «размер» характеризуют сам товар – коврик, слова следующей тема – «игрушка», «малыш» и «ребенок» объединены детской тематикой, что указывает на то, для кого предназначен товар, а следующая тройка слов – «развивает», «восприятие» и «мышление» указывают на пользу товара. Следовательно, по данному примеру можно сказать, что алгоритм отработал корректно.
Оценка качества модели была произведена с помощью расчетов для тестовой выборки. Результаты приведенного эксперимента сравнивались с базовым алгоритмом, в основу которого вошло выделение ключевых слов с помощью метода TF-IDF, то есть отбиралось также по 9 ключевых слов из каждого документа, которые имеют наибольший вес.
Так как у данных 500N-KPCrowd-v1.1 и SemEval2017 есть заранее известные ключевые слова, на их основе была посчитана метрика precision, которая вычисляет соотношение количества правильно отобранных ключевых к общему количеству искомых ключевых слов:
где TP - количество истинных срабатываний, а FP - количество ложных срабатываний соответственно.
Для сравнения к тестовым данным был применен базовый алгоритм, который оценивал слова по TF-IDF. По результатам базового алгоритма precision для датасета 500N-KPCrowd-v1.1 precision составил 0.38 и 0.43 соответственно. После проведения описанного эксперимента метрика возросла и составила 0.56 для 500N-KPCrowd-v1.1 и 0.62 для SemEval2017. Подробнее результаты описаны в таблице 2.
Таблица 2. Результаты эксперимента
|
Данные |
Базовый алгоритм (TF-IDF) |
Представленный метод |
|
500N-KPCrowd-v1.1 |
0.38 |
0.56 |
|
SemEval2017 |
0.43 |
0.62 |
Заключение
В результате проделанной работы извлечены ключевые слова из описаний товаров для упрощения поиска. Была разработана модель тематического моделирования LDA, основанная на подходе ARTM. Данные, используемые для проведения эксперимента, – список описаний товаров в размере 400 тысяч документов. Для проведения эксперимента данные были подвержены предварительной обработке, выделении кандидатов в ключевые слова с помощью статистических методов и обработаны с помощью модели LDA для получения результатов. Оптимальное решение было достигнуто выделением 150 тем из всего списка документов. Конечный вывод ключевых слов состоял из выделения наиболее значимых трех слов по каждой из трех приоритетных тем, выделенных для конкретного документа. Качество работы оценивалось на тестовых данных – готовые данные 500N-KPCrowd-v1.1 и SemEval2017 с выделенными ключевыми словами. Метрика precision показала результаты в 0.56 и 0.62 соответственно, что выше результата базового алгоритма.