Введение
Классификация визуально близких категорий относится к числу наиболее трудных задач компьютерного зрения, когда различия между классами малы, а вариативность внутри класса заметна даже при стандартизированной съемке. В обзорах (Ramanjot et al., 2023) и (Pacal et al., 2024) подобные постановки рассматриваются как характерная зона напряжения для современных моделей глубокого обучения, поскольку итоговое качество здесь определяется не только архитектурой сети, но и способом ее адаптации к целевому набору данных.
Открытые коллекции изображений листьев растений удобны в качестве экспериментального полигона для анализа таких режимов адаптации. Наборы этого типа объединяют достаточно большое число классов, выраженную межклассовую близость и хорошо формализованную разметку, благодаря чему позволяют исследовать поведение модели в задаче тонкого различения визуальных состояний. В обзоре (Zhao et al., 2025) подчеркивается, что именно сходство текстурных, цветовых и морфологических признаков делает подобные данные полезными для проверки устойчивости алгоритмов распознавания.
Перенос обучения в рассматриваемой постановке важен прежде всего как механизм повторного использования ранее сформированного признакового пространства. Практический вопрос заключается не в самой возможности переноса, а в выборе режима адаптации заранее обученной сети: оставить сверточную основу неизменной либо открыть часть слоев для последующей настройки. Работа (Richter, Kim, 2025) показывает, что глубина такой адаптации заметно влияет на итоговое качество даже при использовании одних и тех же открытых наборов данных, а (Shafik et al., 2024) связывает эффективность подхода с тем, насколько точно модель подстраивается под специфику целевого визуального материала.
Стандартизированные наборы изображений дают удобную среду для сопоставления моделей, однако интерпретация результатов требует аккуратности. Контролируемый фон, крупный план объекта и ограниченное число внешних помех упрощают задачу классификации по сравнению с более сложными сценариями распознавания, где присутствуют доменный сдвиг, вариативность ракурсов и неоднородное освещение. По этой причине исследовательский интерес в данной работе сосредоточен на сравнении режимов адаптации в одинаковых условиях, а предметная область набора данных используется как воспроизводимый пример задачи высокой визуальной сложности.
Цель исследования заключается в оценке влияния режима адаптации заранее обученной нейросетевой модели на качество классификации визуально близких классов при фиксированной архитектуре и единых экспериментальных условиях. Рабочая гипотеза состоит в том, что частичное дообучение верхних слоев заранее обученной сверточной нейронной сети обеспечит более высокое качество распознавания по сравнению с режимом, при котором изменяется только завершающий классификационный блок. Для проверки гипотезы сопоставление проводится на одной архитектуре, одном стандартизированном наборе изображений, фиксированном разбиении выборки и общей системе показателей качества.
Задачи исследования:
-
Охарактеризовать применимость обучения с переносом к задаче классификации визуально близких классов на основе недавних научных публикаций (Ramanjot et al., 2023; Pacal et al., 2024; Zhao et al., 2025; Shafik et al., 2024; Richter, Kim, 2025);
-
Реализовать два режима адаптации заранее обученной сверточной модели, включающие замороженную сверточную основу и частичное дообучение верхней части сети;
-
Сравнить полученные модели по точности, функции потерь и поклассовым показателям качества, а также выявить группы классов, в которых межклассовое смешение проявляется наиболее отчетливо.
Материалы и методы
Каталог TensorFlow Datasets (TensorFlow, 2024a) фиксирует для набора PlantVillage 54 303 изображения, распределенные по 38 классам. В настоящем исследовании этот набор использовался не как источник данных для прикладной агрономической экспертизы, а как стандартизированный испытательный полигон для анализа режимов адаптации нейросетей в задаче классификации визуально близких категорий. Работа (Rahman, Islam, Islam, 2024) также показывает, что PlantVillage удобен для сопоставления заранее обученных сверточных сетей благодаря воспроизводимой разметке, однородной подаче объекта и достаточному числу классов. В исследование была включена версия набора без категории Background_without_leaves, используемая в реализации TensorFlow Datasets.
Таблица 1 / Table 1
Характеристики экспериментального набора данных и схема разбиения выборки
Characteristics of the experimental dataset and sample splitting scheme
|
Показатель |
Значение |
|
Набор данных |
PlantVillage |
|
Общее число изображений |
54 303 |
|
Число категорий |
38 |
|
Исходный размер изображения |
256 × 256 × 3 |
|
Рабочий размер изображения |
224 × 224 × 3 |
|
Обучающая часть |
38 012 |
|
Проверочная часть |
8 146 |
|
Итоговая часть |
8 145 |
|
Доля обучающей части, % |
70,0 |
|
Доля проверочной части, % |
15,0 |
|
Доля итоговой части, % |
15,0 |
|
Фиксированное начальное состояние генератора |
42 |
Примечание. Численность частей выборки получена при однократном воспроизводимом разбиении полного набора данных.
Визуальный материал набора демонстрирует удобную для сравнительного эксперимента структуру: объект занимает основную часть кадра, фон остается сравнительно однородным, а межклассовые различия задаются сочетанием текстурных, цветовых и морфологических признаков. Подобная конфигурация делает PlantVillage полезным стандартным набором для проверки того, как режим адаптации нейросети влияет на качество классификации в условиях высокой визуальной близости классов. Сопоставимые выводы о роли стандартизированных открытых наборов данных в задачах тонкого различения изображений приводятся в (Yang et al., 2024; Sambana et al., 2025). Фрагменты исходных изображений приведены на рис. 1.

Рис. 1. Примеры исходных изображений листьев из экспериментального набора данных PlantVillage
Fig. 1. Examples of original leaf images from the experimental PlantVillage dataset
Предобработка включала изменение размера изображений до 224 × 224 точек, приведение массива пикселей к типу float32 и сохранение естественного диапазона яркости от 0 до 255. Официальная документация TensorFlow для MobileNetV3Small (TensorFlow, 2024b) указывает, что при включенной встроенной предобработке модель принимает именно такой диапазон входных значений, поэтому отдельная внешняя нормализация до интервала от -1 до 1 не выполнялась. Результат предобработки показан на рис. 2; после уменьшения разрешения классово значимые визуальные признаки, включая границы локальных изменений, цветовые переходы и особенности текстуры, сохранялись в различимом виде.

Рис. 2. Примеры изображений после предобработки и приведения к единому размеру
Fig. 2. Examples of images after preprocessing and resizing to a unified format
Разбиение на обучающую, проверочную и итоговую части проводилось однократно, в воспроизводимом порядке, с фиксированным начальным состоянием генератора случайных чисел. Контроль репрезентативности выполнялся через максимальное отклонение доли класса в каждой части выборки от доли того же класса в полном наборе данных. Величина такого отклонения вычислялась по формуле (1); для обучающей части она составила 0,131 процентного пункта, для проверочной 0,448, для итоговой 0,608, что позволяет считать распределение классов достаточно близким к исходному.
Базовой архитектурой выбрана MobileNetV3Small (TensorFlow, 2024b), поскольку официальная реализация TensorFlow поддерживает предварительно обученные веса ImageNet и входной размер 224 × 224, а вычислительная сложность модели остается умеренной для бесплатной среды Google Colab. Работы (Rahman, Islam, Islam, 2024; Yang et al., 2024; Sambana et al., 2025) показывают, что заранее обученные сверточные сети способны сохранять высокий уровень качества и при сравнительно компактной архитектуре, если режим адаптации к целевому набору данных выбран корректно.
Таблица 2 / Table 2
Параметры двух режимов адаптации заранее обученной нейросетевой модели
Parameters of two adaptation regimes for a pretrained neural network model
|
Параметр |
Режим 1: замороженная сверточная основа |
Режим 2: частичное дообучение |
|
Базовая архитектура |
MobileNetV3Small |
MobileNetV3Small |
|
Предварительно обученные веса |
ImageNet |
ImageNet |
|
Размер входного изображения |
224 × 224 × 3 |
224 × 224 × 3 |
|
Изменяемая часть сети |
Только классификационный блок |
Классификационный блок и верхняя часть сверточной основы |
|
Число открываемых верхних слоев сверточной основы |
0 |
40* |
|
Слой глобального усреднения |
Да |
Да |
|
Слой пакетной нормализации |
Да |
Да |
|
Слой случайного отключения части нейронов |
0,30 |
0,30 |
|
Выходной слой |
38 классов, softmax |
38 классов, softmax |
|
Алгоритм оптимизации |
Adam |
Adam |
|
Скорость обучения |
0,001 |
0,00001 |
|
Максимальное число эпох |
5 |
5 |
|
Критерий сохранения лучшей модели |
Точность на проверочной части |
Точность на проверочной части |
|
Досрочная остановка |
patience = 2 |
patience = 2 |
Примечание. При частичном дообучении для адаптации рассматривались последние 40 слоев сверточной основы MobileNetV3Small. Слои пакетной нормализации внутри этой группы сохранялись в замороженном состоянии, поэтому фактически обновлялись параметры 32 слоев сверточной основы.
Использование одной и той же базовой сети в обоих экспериментальных режимах позволило исключить влияние архитектурного фактора и свести сравнение к глубине последующей настройки модели.
Поверх сверточной основы размещались слой глобального усреднения по пространственным координатам, слой пакетной нормализации, слой случайного отключения части нейронов с вероятностью 0,30 и выходной полносвязный слой на 38 классов с функцией softmax, задающей нормированное распределение вероятностей по категориям. Первый режим обучения изменял только параметры завершающего классификационного блока. Во втором режиме для адаптации открывались последние 40 слоев сверточной основы MobileNetV3Small, однако слои пакетной нормализации внутри этой группы оставались замороженными. Поэтому число фактически дообучаемых слоев сверточной основы составило 32, что позволяет сохранить стабильность статистик Batch Normalization и одновременно адаптировать верхние признаки модели к целевому набору изображений; аналогичная рекомендация приводится в руководстве TensorFlow по дообучению (Chollet, 2023).
Проверочная часть использовалась для выбора лучшей эпохи и контроля остановки обучения, а итоговая часть полностью исключалась из настройки модели и применялась только на завершающем этапе сравнения. Сохранение лучшей версии выполнялось по точности на проверочной части, досрочная остановка включалась при отсутствии улучшения в течение двух эпох. Практика поэтапного перехода от замороженной сверточной основы к аккуратному частичному дообучению регулярно применяется и в недавних работах по диагностике болезней растений (Chollet, 2023; Sambana et al., 2025).
Оценка качества строилась на общей точности классификации, точности, полноте и мере F1 с макроусреднением, а также на значении функции потерь перекрестной энтропии. Макроусреднение выбрано по причине заметной неравномерности классов: часть категорий содержала менее 50 изображений, тогда как классы Orange | Haunglongbing и Tomato | Tomato Yellow Leaf Curl Virus включали более 800 наблюдений. Дополнительно рассчитывались взвешенные варианты показателей и поклассовые метрики для лучшей модели.
Матрица ошибок использовалась для интерпретации структуры неверных решений после выбора лучшей модели. Подобный разбор особенно важен в задаче распознавания листовых заболеваний, где визуально близкие симптомы, например разные виды пятнистости или ожога листа, могут давать высокую общую точность и одновременно создавать локальные зоны межклассового смешения (Yang et al., 2024; Sambana et al., 2025). Переход от общей точности к поклассовому анализу позволял рассматривать качество модели не как единое число, а как распределение успешных и проблемных случаев внутри всей таксономии заболеваний.
Результаты
Сопоставление двух режимов адаптации показало, что частичное дообучение верхней части заранее обученной сети дало более высокий результат, чем обучение одного классификационного блока. По данным табл. 3 точность на проверочной части выросла с 0,9707 до 0,9816, а значение функции потерь снизилось с 0,0929 до 0,0576. Прирост составил 1,09 процентного пункта при той же базовой архитектуре, том же наборе данных и неизменной схеме разбиения выборки. Следует учитывать, что сравнение выполнено при одном фиксированном разбиении выборки и одном воспроизводимом запуске эксперимента, поэтому полученный прирост рассматривается как практически значимый результат в рамках заданного экспериментального контура, а не как окончательная статистическая оценка устойчивости эффекта. Для более строгой проверки в дальнейшем целесообразно выполнить несколько повторных запусков с разными начальными состояниями генератора случайных чисел и рассчитать доверительные интервалы для итоговых метрик. Значения подобного порядка для контролируемых наборов изображений листьев приводятся и в недавних работах (Natarajan, Chakrabarti, Margala, 2024; Aboelenin et al., 2025), однако в них использовались другие конфигурации классов и иные экспериментальные постановки, поэтому прямое численное сопоставление допустимо только с оговорками.
Таблица 3 / Table 3
Сопоставление двух режимов переноса обучения по результатам на проверочной части
Comparison of two modes of learning transfer based on the results of the testing part
|
Показатель |
Замороженная сверточная основа |
Частичное дообучение |
Изменение |
|
Общее число параметров |
963 350 |
963 350 |
0 |
|
Число настраиваемых параметров |
23 078 |
731 054 |
+707 976 |
|
Число ненастраиваемых параметров |
940 272 |
232 296 |
-707 976 |
|
Число фактически дообучаемых слоев в сверточной основе |
0 |
32 |
+32 |
|
Число верхних слоев сверточной основы, выбранных для адаптации |
0 |
40 |
+40 |
|
Лучшая эпоха |
4 |
5 |
+1 |
|
Точность на проверочной части |
0,9707 |
0,9816 |
+1,09 п.п. |
|
Функция потерь на проверочной части |
0,0929 |
0,0576 |
-0,0353 |
Примечание. Для обоих режимов использовалась архитектура MobileNetV3Small; различался только способ адаптации заранее обученной сверточной основы. Во втором режиме для адаптации была выбрана верхняя группа из 40 слоев, однако слои пакетной нормализации не обновлялись, поэтому фактически дообучались 32 слоя сверточной основы.
Рост качества по эпохам имел различный характер. Режим с замороженной сверточной основой быстро вышел на плато: основная часть прироста пришлась на первые две эпохи, после чего улучшение стало минимальным. Частичное дообучение сохраняло поступательное движение до пятой эпохи, а кривая функции потерь убывала более ровно. Графики обучения, приведенные на рис. 3 и рис. 4, показывают отсутствие заметного расхождения между обучающей и проверочной частями, что указывает на устойчивую настройку модели в пределах выбранного экспериментального контура.
Поклассовый расчет для лучшей модели позволил оценить качество уже на независимой итоговой части выборки через показатели, заданные формулами (2) - (6). Расчет по данным итоговой классификации дал общую точность около 0,9843, макроусредненную меру F1 около 0,9792 и взвешенную меру F1 около 0,9842. Разница между макроусредненными и взвешенными значениями оказалась небольшой, хотя более низкая макроусредненная полнота отразила наличие нескольких классов, в которых распознавание шло заметно труднее. Обзор (Salka et al., 2025) связывает подобные локальные просадки с высокой визуальной близостью классов, неравномерностью выборки и особенностями стандартизированных наборов изображений.
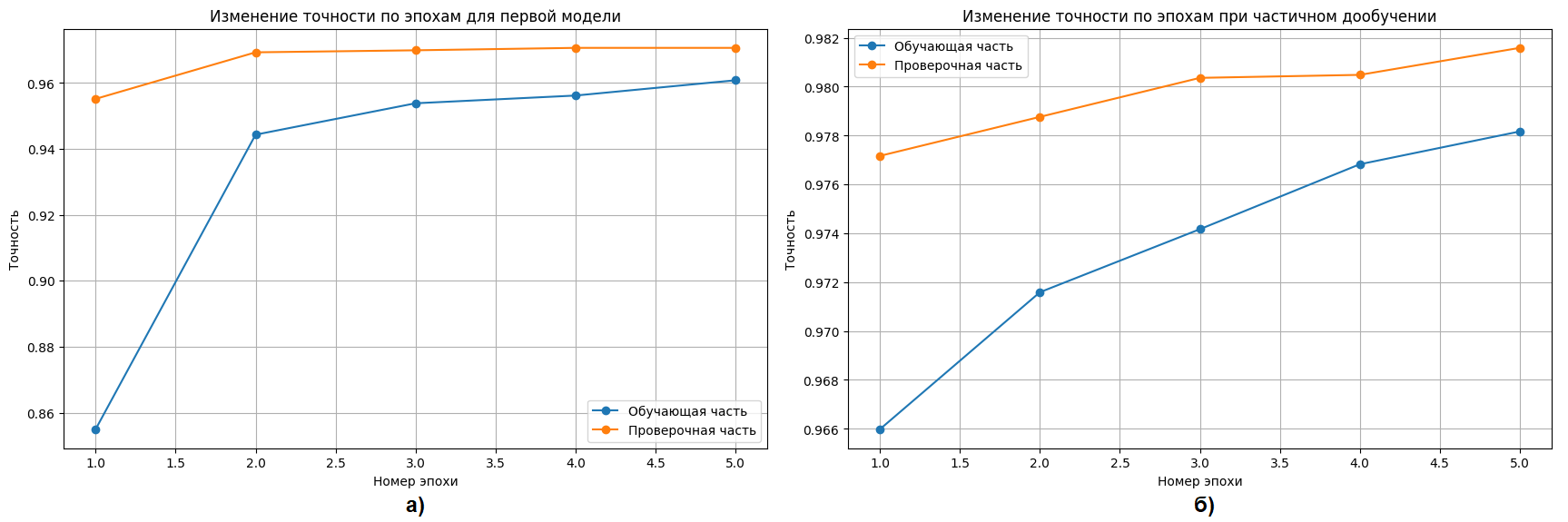
Рис. 3. Динамика точности на обучающей и проверочной частях данных при двух режимах переноса обучения: а – замороженная сверточная основа; б – частичное дообучение
Fig. 3. Accuracy dynamics on the training and validation datasets for two transfer learning modes: a – frozen convolutional base; b – partial retraining
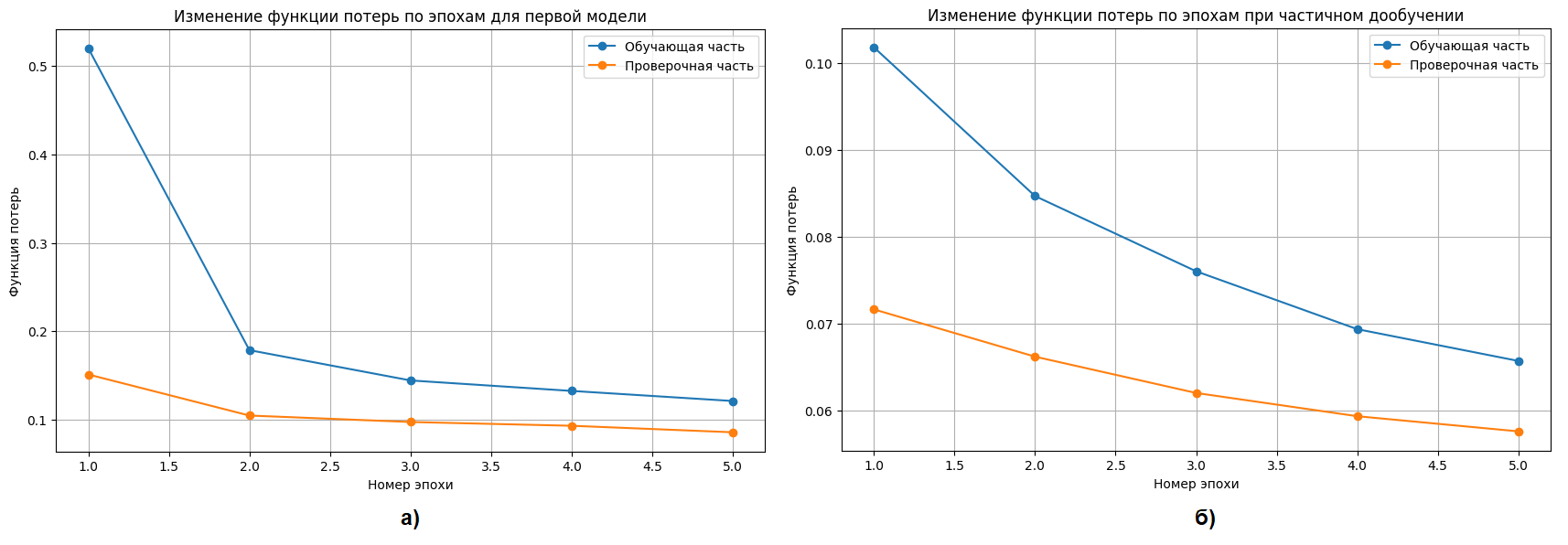
Рис. 4. Динамика функции потерь на обучающей и проверочной частях данных при двух режимах переноса обучения: а – замороженная сверточная основа; б – частичное дообучение.
Fig. 4. Loss dynamics on the training and validation datasets for two transfer learning modes: a – frozen convolutional backbone; b – partial fine-tuning
Распределение поклассовых показателей оказалось содержательно неоднородным. Наиболее высокие значения меры F1 зафиксированы у классов Squash | Powdery mildew, Blueberry | healthy, Apple | Black rot, Grape | healthy и Orange | Haunglongbing, где распознавание приближалось к безошибочному уровню. Проблемная зона сместилась к группам с высокой визуальной близостью: минимальные значения меры F1 наблюдались у классов Corn | Cercospora leaf spot Gray leaf spot, Tomato | Early blight, Potato | healthy, Corn | Northern Leaf Blight и Tomato | Target Spot. С методической точки зрения здесь важен сам факт локального снижения качества в трудных зонах пространства признаков.
Таблица 4 / Table 4
Показатели лучшей модели на итоговой части выборки
Performance of the best model on the final part of the sample
|
Показатель |
Значение |
|
Общая точность классификации |
0,9843 |
|
Точность с макроусреднением |
0,9812 |
|
Полнота с макроусреднением |
0,9776 |
|
Мера F1 с макроусреднением |
0,9792 |
|
Точность с взвешенным усреднением |
0,9843 |
|
Полнота с взвешенным усреднением |
0,9843 |
|
Мера F1 с взвешенным усреднением |
0,9842 |
Таблица 5 / Table 5
Наиболее и наименее устойчиво распознаваемые классы лучшей модели
Most and least reliably recognized classes of the best model
|
Наиболее устойчивые категории |
Число изображений |
Мера F1 |
Наименее устойчивые категории |
Число изображений |
Мера F1 |
|
Squash | Powdery mildew |
281 |
1,0000 |
Corn | Cercospora leaf spot Gray leaf spot |
86 |
0,8889 |
|
Blueberry | healthy |
213 |
1,0000 |
Tomato | Early blight |
145 |
0,9078 |
|
Apple | Black rot |
107 |
1,0000 |
Potato | healthy |
22 |
0,9302 |
|
Grape | healthy |
58 |
1,0000 |
Corn | Northern Leaf Blight |
153 |
0,9363 |
|
Orange | Haunglongbing (Citrus greening) |
832 |
0,9994 |
Tomato | Target Spot |
226 |
0,9417 |
Нормированная матрица ошибок лучшей модели представлена на рис. 5. Главная диагональ сохраняет высокую насыщенность почти по всей совокупности классов, однако локальные смещения отчетливо видны у групп с морфологически и текстурно близкими признаками. Наиболее заметный пример связан с классами Corn | Cercospora leaf spot Gray leaf spot и Corn | Northern Leaf Blight. В группе томатных классов основное число ошибок сосредоточилось между Early blight, Late blight, Septoria leaf spot, Target Spot и Spider mites Two-spotted spider mite. Работа (Salka et al., 2025) подчеркивает, что именно сходство локальных визуальных паттернов часто становится основной причиной межклассового смешения в задачах тонкой классификации изображений.
Картина ошибок в табл. 6 показывает, что модель путала прежде всего близкие классы внутри одной морфологически согласованной группы. На первом месте оказалось смешение Corn | Cercospora leaf spot Gray leaf spot с Corn | Northern Leaf Blight, давшее 14 ошибок, или 16,279 % внутри истинного класса. Следом шли пары Tomato | Target Spot и Tomato | Spider mites Two-spotted spider mite, Tomato | Late blight и Tomato | Early blight, Tomato | Early blight и Tomato | Septoria leaf spot. Подобная структура важна для общей интерпретации результатов, поскольку указывает на содержательные зоны трудности в пространстве визуальных признаков, а не на случайный характер ошибок.
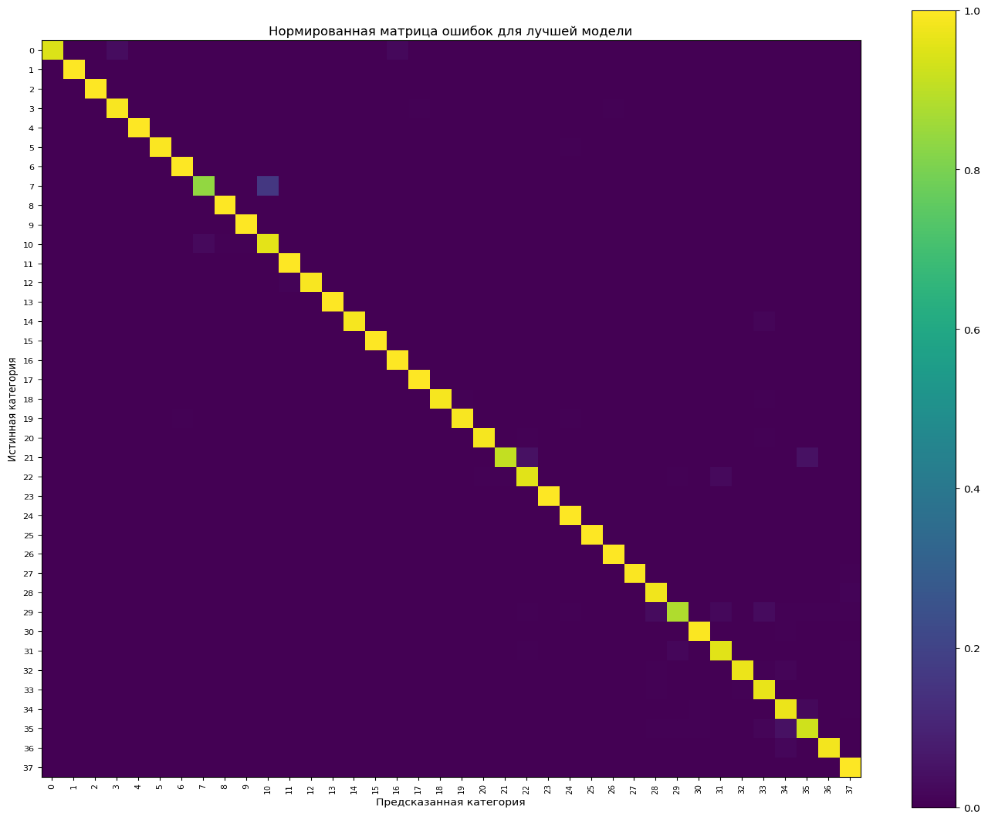
Рис. 5. Нормированная матрица ошибок лучшей модели на итоговой части выборки
Fig. 5. Normalized error matrix of the best model on the final part of the sample
Таблица 6 / Table 6
Наиболее частые межклассовые смешения у лучшей модели в зонах визуальной близости
Most frequent inter-class confusions of the best model in zones of visual proximity
|
Истинная категория |
Предсказанная категория |
Количество ошибок |
Доля ошибок внутри истинной категории, % |
|
Corn | Cercospora leaf spot Gray leaf spot |
Corn | Northern Leaf Blight |
14 |
16,279 |
|
Tomato | Target Spot |
Tomato | Spider mites Two-spotted spider mite |
10 |
4,425 |
|
Tomato | Spider mites Two-spotted spider mite |
Tomato | Target Spot |
5 |
2,000 |
|
Tomato | Late blight |
Tomato | Early blight |
5 |
1,779 |
|
Tomato | Early blight |
Tomato | Bacterial spot |
4 |
2,759 |
|
Tomato | Early blight |
Tomato | Septoria leaf spot |
4 |
2,759 |
|
Corn | Northern Leaf Blight |
Corn | Cercospora leaf spot Gray leaf spot |
4 |
2,614 |
|
Potato | Late blight |
Tomato | Late blight |
4 |
2,614 |
|
Apple | Apple scab |
Apple | healthy |
3 |
3,125 |
|
Tomato | Early blight |
Tomato | Late blight |
3 |
2,069 |
Обсуждение результатов
Прирост точности на 1,09 процентного пункта при переходе от замороженной сверточной основы к частичному дообучению имеет методическое значение, поскольку сравнение проводилось на одной архитектуре, одном наборе изображений и при одинаковой схеме разбиения данных. Полученный выигрыш указывает на преимущество более глубокой адаптации модели к целевой задаче в пределах проведенного эксперимента. При этом результат не следует трактовать как универсальное доказательство превосходства fine-tuning для всех наборов изображений и архитектур: устойчивость выявленного эффекта требует проверки на нескольких случайных инициализациях, альтернативных разбиениях и внешних данных. В статье (Dong et al., 2024) влияние режима дообучения также рассматривается как отдельный фактор надежности распознавания, а в работе (Iftikhar et al., 2024) донастройка признакового ядра связывается с улучшением качества на сложных изображениях.
Характер обучения в двух режимах оказался не менее важен, чем итоговые числа. Замороженная сверточная основа быстро вышла на плато, что обычно наблюдается в ситуациях, когда заранее обученные признаки дают сильный старт, однако перестают достаточно тонко различать близкие категории целевого набора. Частичное дообучение сохранило рост качества до конца обучения, и подобная динамика хорошо согласуется с выводами (Dong et al., 2024), где выбор парадигмы донастройки заметно менял качество классификации в тонких межклассовых различиях. Обзор (Shoaib et al., 2025) также связывает успешность переноса обучения с глубиной адаптации модели к специфике целевого визуального материала.
Распределение ошибок показывает, что слабые места модели сосредоточены в группах с близкой морфологией, текстурой и цветовым рисунком. Наиболее проблемными оказались пары классов, где совпадают локальная структура изменения поверхности, конфигурация очагов и характер цветовых переходов. Обзорные работы (Shoaib et al., 2025; Shafay et al., 2025) описывают ту же закономерность: наилучшие показатели обычно достигаются на контрастных и хорошо отделимых категориях, тогда как сходные по визуальному паттерну классы продолжают создавать зоны межклассового смешения даже у сильных моделей. С методической точки зрения полученная матрица ошибок подтверждает, что эксперимент действительно проверял режимы адаптации в трудной задаче тонкой классификации.
Интерпретация полученных значений требует аккуратности из-за свойств самого набора PlantVillage. Контролируемый фон, крупный план объекта и относительно чистая визуальная сцена упрощают задачу по сравнению с более сложными сценариями распознавания, где присутствуют тени, перекрытия, неоднородное освещение и естественные помехи. В работе (Salman, Muhammad, Han, 2025) классификация в реальной съемке разбирается именно как случай доменного сдвига, то есть изменения распределения изображений между учебной и практической средой, а обзор (Shafay et al., 2025) рассматривает подобный разрыв как одно из центральных ограничений современной литературы по автоматическому анализу изображений. По этой причине полученный результат корректнее трактовать как доказательство эффективности выбранного режима адаптации в стандартизированной постановке.
Закрытый характер классификации задает еще одну границу применимости проведенного эксперимента. Обученная модель выбирала один из заранее известных классов, тогда как в более общей практике анализа изображений встречаются редкие, смешанные и ранее не представленные в обучении состояния. Исследование (Dong et al., 2024) показывает, что распознавание неизвестных классов требует специальной постановки задачи и отдельной проверки устойчивости, а работа (Salman, Muhammad, Han, 2025) демонстрирует, насколько сильно меняется поведение модели при переходе к данным из естественной среды. Следующий шаг здесь связан с проверкой лучшего режима дообучения на более сложных внешних наборах данных и с оценкой способности системы корректно выделять случаи, для которых уверенное отнесение к известным классам недопустимо.
Заключение
Частичное дообучение верхней части заранее обученной сверточной сети обеспечило более высокое качество классификации, чем режим, в котором изменялся только завершающий классификационный блок. При одинаковой архитектуре, едином наборе данных и фиксированном разбиении выборки точность на проверочной части возросла с 0,9707 до 0,9816, а значение функции потерь снизилось с 0,0929 до 0,0576. Поклассовый анализ лучшей модели показал, что наибольшая устойчивость достигается у хорошо различимых классов, тогда как основные ошибки концентрируются в группах с высокой визуальной близостью.
Научная новизна исследования связана с контролируемым экспериментальным сопоставлением двух режимов адаптации MobileNetV3Small в задаче классификации визуально близких классов набора PlantVillage. В работе не утверждается принципиальная новизна частичного дообучения как метода, поскольку fine-tuning является распространенной практикой применения заранее обученных сверточных сетей. Новым для данной постановки является показанное на единой экспериментальной схеме преимущество частичного дообучения верхней части признакового ядра над режимом извлечения признаков без настройки сверточной основы. Полученный результат важен не только по величине общей точности, но и по структуре ошибок: улучшение проявилось на независимой итоговой части выборки и сопровождалось содержательно объяснимым распределением смешений в трудных зонах пространства признаков. Обзоры последних лет (Upadhyay et al., 2025) и работы по расширению сложных наборов изображений (Zhang et al., 2025) подтверждают, что вопрос обобщающей способности модели и переносимости результата на более сложные данные остается центральным, поэтому вывод о предпочтительности частичного дообучения имеет методическую ценность для построения аналогичных систем анализа изображений.
Практическая значимость работы определяется возможностью использовать предложенную схему адаптации при проектировании систем автоматической классификации изображений, где требуется различать близкие визуальные категории в условиях ограниченного объема целевых данных. Эксперимент на наборе PlantVillage показывает, что даже компактная заранее обученная архитектура способна обеспечить высокий уровень качества, если режим ее последующей настройки выбран корректно. Наиболее осторожного применения требуют группы классов со сходной морфологией и текстурой, поскольку именно там сохраняется основная доля межклассовых смешений.
Ограничения исследования связаны с тремя обстоятельствами. Во-первых, итоговая проверка выполнялась на стандартизированном наборе изображений PlantVillage, где фон, масштаб объекта и условия съемки заметно упрощают задачу по сравнению с более сложной визуальной средой. Во-вторых, эксперимент проводился при одном фиксированном разбиении выборки и одном воспроизводимом запуске модели, поэтому величина прироста качества требует дополнительной проверки на повторных запусках с разными начальными состояниями генератора случайных чисел. В-третьих, число изображений в отдельных тестовых классах оставалось небольшим, из-за чего поклассовые оценки для редких категорий получали более дискретный характер и сильнее зависели от единичных ошибок. Расширение пула изображений для редких классов, расчет доверительных интервалов для метрик и проверка модели на дополнительных независимых источниках данных рассматриваются как первое направление продолжения работы. Второе направление связано с переносимостью результата на более сложные условия съемки: при переходе к данным с тенями, перекрытиями, неоднородным освещением и естественными помехами потребуется повторная проверка устойчивости модели, а при изменении состава классов и структуры входного потока – регулярная переоценка качества на новых данных (Upadhyay et al., 2025; Zhang et al., 2025).