Введение
Чат-боты представляют собой системы, использующие технологии обработки естественного языка (NLP) для взаимодействия с людьми (Tsai, Liu, Chuan, 2021). За последние два десятилетия достижения в области искусственного интеллекта (ИИ), машинного обучения и обработки естественного языка способствовали распространению чат-ботов в различных сферах, что расширило их использование в управлении взаимоотношениями с клиентами (Janson, 2023; Nguyen et al., 2023), здравоохранении и психологической помощи (Роговец и др., 2023; Lopes et al., 2023; Schillaci et al., 2024), образовании (Al-Abdullatif, Al-Dokhny, Drwish, 2023; Cheng et al., 2024) и других областях. Резкий рост популярности чат-ботов объясняется их способностью предоставлять круглосуточную поддержку и эффективно вовлекать пользователей, что, в свою очередь, трансформирует традиционные модели пользовательского опыта (Paliwal, Bharti, Mishra, 2020).
Генеративный ИИ кардинально изменяет различные аспекты человеческой жизни. Интеграция генеративного ИИ в повседневную деятельность является не просто технологическим достижением: она представляет собой парадигмальный сдвиг в том, как человек взаимодействует с информацией и принимает решения. Ярким примером успешной интеграции генеративного ИИ в технологии чат-ботов является модель ChatGPT, разработанная компанией OpenAI. Созданный на базе архитектуры трансформеров, ChatGPT был обучен на больших массивах данных, что позволяет ему генерировать высококачественные и контекстуально уместные ответы на естественном языке (Tsai, Liu, Chuan, 2021). Кроме того, были разработаны и другие чат-боты на основе генеративного ИИ, такие как Claude, Bard и LLaMA, а также их российские аналоги GigaChat, YandexGPT и JustGPT.
Традиционные чат-боты обычно полагаются на предопределенные сценарии и могут обрабатывать только ограниченный набор запросов, что приводит к тому, что чат-бот способен поддерживать разговор, имеющий конкретную цель, однако не обеспечивает удовлетворительных результатов в открытых беседах, где темы могут варьироваться (Mohamad Suhaili, Salim, Jambli, 2021). Применение в разработке чат-ботов с генеративным ИИ таких методов машинного обучения, как оптимизация гиперпараметров и тонкая настройка, позволяет повышать качество и точность ответов, адаптируя их для конкретных задач и предпочтений пользователей, что способствует более естественному взаимодействию и повышению уровня удовлетворенности пользователей (Rane et al., 2024).
Несмотря на явные преимущества чат-ботов на основе генеративного ИИ, сохраняется ряд проблем, особенно касающихся их восприятия пользователем и общего удобства использования. Понимание взаимодействия пользователя с этими системами имеет решающее значение, поскольку оно напрямую влияет на удовлетворенность пользователя и доверие к предоставленной информации (Xue et al., 2023). Исследования показывают, что характеристики пользователя, такие как возраст, пол и национальность, могут влиять на то, как люди воспринимают и взаимодействуют с чат-ботами, что подчеркивает важность оценки этих факторов при разработке и внедрении технологий чат-ботов (Gunnam et al., 2022). Выявление нюансов пользовательского опыта имеет важное значение для совершенствования функциональности чат-ботов и повышения общего качества взаимодействия.
Центральным аспектом пользовательского опыта выступает удовлетворенность пользователей, для формирования которой ключевым фактором является удобство пользования. Высокий уровень удобства пользования играет важную роль во взаимодействии с технологиями и способствует созданию и укреплению онлайн-доверия (Косова, Горбунова, 2023). Наиболее распространенными инструментами для измерения уровня удобства пользования являются шкала удобства использования системы (System Usability Scale) (Brooke, 1996) и метрика удобства взаимодействия для пользовательского опыта (The Usability Metric for User Experience) (Finstad, 2010). В отличие от классических интерактивных систем, которые основываются на графических элементах, чат-боты используют текстовые и разговорные аспекты для взаимодействия со своими пользователями (Valério et al., 2018). Таким образом, оценка удовлетворенности пользователей чат-ботами должна включать элементы, которые обычно не учитываются в традиционных оценках удовлетворенности, такие как качество разговорных взаимодействий. Разработка стандартизированных метрик для оценки взаимодействий с чат-ботами может помочь в более полном понимании удовлетворенности пользователей и выявлении возможных направлений для улучшения взаимодействия людей и чат-ботов (Abd-Alrazaq et al., 2021). Единственным специализированным инструментом для оценки удобства пользования чат-ботами является шкала chatBot Usability Scale, разработанная Борши с соавт. (2022). Данный опросник был валидизирован на английском, немецком, нидерландском, испанском и итальянском языках (Borsci et al., 2023a; Borsci et al., 2023b). С учетом стремительного роста популярности чат-ботов на основе генеративного ИИ среди русскоязычных пользователей, становится очевидным, что необходимость в создании эффективных инструментов оценки их удовлетворенности становится все более актуальной. В связи с этим цель нашего исследования заключается в адаптации опросника BUS-11 для оценки удобства использования чат-ботов на русскоязычной выборке пользователей чат-ботов с генеративным ИИ.
Материалы и методы
Процедура адаптации русскоязычной версии опросника включала в себя следующие этапы: лингвистическая и культурная адаптация опросника, сбор данных и оценка психометрических показателей.
При проведении лингвистической адаптации был проведен перевод на русский язык опросника BUS-11 (Borsci et al., 2023b) в соответствии со стандартными нормами языковой адаптации и валидизации (Van De Vijver, Hambleton, 1996). В качестве привлеченных к данной процедуре специалистов выступали два профессиональных психолога, свободно владеющих русским и английским языками, и два филолога, специализирующихся на переводе текстов психологической направленности. Вначале был осуществлен прямой и обратный перевод текста методики, а затем оригинал и текст обратного перевода прошли экспертную оценку по выявлению несоответствий и коррекции текста. В целях проверки соответствия/несоответствия утверждений содержанию опросника и их понятности для респондентов была проведена фокус-группа из девяти студентов-психологов, активно использующих чат-боты. Обсуждение проходило в формате видеоконференции посредством Zoom. В ходе обсуждения было внесено семь изменений. Приводим наиболее значимые. В варианте перевода Функцию чат-бота было легко обнаружить акцентировалось внимание на легкости его обнаружения, что было слишком узким пониманием взаимодействия. В итоговом варианте добавлены слова доступны и понятны, что расширяет смысл и подчеркивает важность удобного доступа для пользователя. В варианте перевода Чат-бот было легко найти акцент на процессе поиска не учитывает комфорт доступа. Итоговый вариант Доступ к чат-боту был прост и удобен вводит элемент комфорта, подчеркивая значение не только доступности, но и удобства взаимодействия, что добавляет ценность в пользовательский опыт. Вариант перевода Ответы чат-бота было легко понять был слишком абстрактным и трудным для восприятия. Итоговый вариант Ответы чат-бота были просты для понимания улучшает читаемость и звучит более естественно.
Сбор данных для оценки психометрических показателей осуществлялся на платформах Google Forms и Yandex Forms с июля по октябрь 2024 года. Прохождение опроса занимало в среднем 15 минут и не предполагало материального вознаграждения. От всех испытуемых было получено информированное согласие на участие в исследовании.
Выборка
В рамках первого этапа исследования, включавшего оценку внутренней согласованности и дискриминативности, проверку факторной структуры опросника, а также анализ конвергентной и дивергентной валидности, были собраны данные от 207 человек (144 женщины и 63 мужчины) в возрасте от 18 до 60 лет. Выборка формировалась по принципу доступности (convenience sampling) и методом «снежного кома» (snowball sampling). Среди участников 135 имели высшее образование, 63 — неоконченное высшее образование, и 9 обладали ученой степенью. У 144 респондентов был социальный или гуманитарный профиль образования, у 26 — технический, у 23 — естественно-научный, у 7 — медицинский и еще у 7 — математический. У подавляющего большинства, 183 респондентов, был опыт взаимодействия с ChatGPT, у 39 респондентов — с YandexGPT, у 15 респондентов — с GigaChat. Также респонденты упоминали такие инструменты на основе генеративного ИИ, как Copilot, Gemini, Claude, Mistral и др. 52 респондента имели опыт взаимодействия с более чем одним чат-ботом на основе генеративного ИИ. Во втором этапе исследования, проводившегося с интервалом 1—2 месяца для оценки ретестовой надежности, приняли участие 98 человек (68 женщин и 30 мужчин) в возрасте от 18 до 56 лет. У 63 респондентов было высшее образование, у 31 — неоконченное высшее, у 4 — ученая степень. У 60 респондентов был социальный или гуманитарный профиль образования, у 17 — технический, у 15 – естественно-научный, у 3 – медицинский и у 3 – математический.
Методики исследования
Шкала измерения удобства пользования чат-ботом (Bot Usability Scale-BUS-11) (Borsci et al., 2023b) — методика оценки удобства использования чат-ботов и различных аспектов взаимодействия пользователей с ними. Она измеряет такие факторы, как доступность, функциональность, качество общения, вопросы конфиденциальности и скорость ответов. Шкала состоит из 11 пунктов, для оценивания степени согласия или несогласия с утверждениями используется 5-балльная шкала Лайкерта.
AttrakDiff Mini (Hassenzahl, Monk, 2010) — краткая версия методики для оценки пользовательского опыта (в контексте нашего исследования взаимодействия с чат-ботами на основе генеративного ИИ). Методика представляет собой семантический дифференциал, который состоит из 10 пар прилагательных, отражающих прагматическое и гедоническое качества, а также общую привлекательность. Каждая пара оценивается по 7-балльной шкале, где 1 означает согласие с первым прилагательным, 7 — согласие со вторым.
UMUX-LITE (Usability Metric for User Experience) (Lewis, Utesch, Maher, 2013) — краткая версия методики для измерения воспринимаемого удобства пользования. Шкала состоит из двух утверждений, согласие или несогласие с которыми испытуемые оценивают по 7-балльной шкале Лайкерта.
Шкала удовлетворенности жизнью Э. Динера в адаптации Е.Н. Осина и Д.А. Леонтьева (2008) для измерения удовлетворенности и благополучия безотносительно какой-то конкретной сферы жизни состоит из 5 утверждений, согласие или несогласие с которыми испытуемые оценивают по 7-балльной шкале Лайкерта.
Результаты
- Анализ пригодности пунктов теста
Первоначально был подсчитан индекс сложности и коэффициент дискриминативности для каждого из пунктов. Индекс сложности находится в пределах от 0,46 до 0,79. При этом наблюдается явное смещение в сторону «легкости», а для пунктов 2, 11, 5, 3 значения индекса приближаются к 80%. Коэффициент дискриминативности (r — item-total) для всех пунктов находится в интервале от 0,44 до 0,71. Значения представлены в табл. 1.
Таблица 1 / Table 1
Корреляционная взаимосвязь отдельных пунктов с итоговым показателем BUS-11
Correlation of individual items with the total BUS-11 score
|
№ |
Содержание пункта |
rs |
|
1 |
Доступ к чат-боту был прост и удобен / The chatbot function was easily detectable |
0,44 |
|
2 |
Функции чат-бота были доступны и понятны / It was easy to find the chatbot |
0,60 |
|
3 |
Коммуникация с чат-ботом была понятной / Communicating with the chatbot was clear |
0,59 |
|
4 |
Чат-бот мог отслеживать контекст взаимодействия / The chatbot was able to keep track of context |
0,55 |
|
5 |
Ответы чат-бота были просты для понимания / The chatbot’s responses were easy to understand |
0,49 |
|
6 |
Чат-бот «понимал», чего я хочу, и помогал мне достичь цели / I find that the chatbot understands what I want and helps me achieve my goal |
0,66 |
|
7 |
Чат-бот предоставил мне необходимый объем информации / The chatbot gives me the appropriate amount of information |
0,69 |
|
8 |
Чат-бот предоставлял мне только ту информацию, которая была мне нужна / The chatbot only gives me the information I need |
0,71 |
|
9 |
Ответы чат-бота всегда были точными / I feel like the chatbot’s responses were accurate |
0,69 |
|
10 |
Мне кажется, что чат-бот проинформирует меня о любых возможных проблемах с конфиденциальностью / I believe the chatbot informs me of any possible privacy issues |
0,52 |
|
11 |
Ожидание ответа от чат-бота занимало мало времени / My waiting time for a response from the chatbot was short |
0,55 |
Примечание: rs — коэффициент корреляции Спирмена; «**» — корреляция значима на уровне 0,01.
Note: rs — Spearman's correlation coefficient; «**» — correlation is significant at the 0.01 level.
Согласованность пунктов методики с общей шкалой «удобство использования чат-бота» —– α Кронбаха — составляет 0,808. В табл. 2 приведены итоговые статистические данные для всей выборки (n = 207).
Таблица 2 / Table 2
Итоговые статистические данные для методики BUS-11
Final statistics for the BUS-11 questionnaire
|
Наименование статистики |
Значение |
|
Среднее / mean |
3,72 |
|
Стандартное отклонение / Standard Deviation |
,58 |
|
Дисперсия / Variance |
,34 |
|
Асимметрия / Skewness |
-,51 |
|
Эксцесс / Kurtosis |
,56 |
|
Минимум / Minimum |
1,73 |
|
Максимум / Maximum |
5,0 |
|
α Кронбаха / Cronbach's Alpha |
0,81 |
|
Стандартизованная альфа / Standardized Alpha |
0,94 |
|
Средняя межпозиционная корреляция / Average Inter-item Correlation |
0,59 |
Оценка ретестовой надежности методики проводилась с интервалом в 1 месяц в течение 4 недель с использованием ранговой корреляции r Спирмена. R Спирмена для русскоязычной версии BUS-11 составляет 0,83, что говорит о высокой ретестовой надежности.
- Факторная структура опросника
Для анализа структуры данных методики использовался эксплораторный факторный анализ (метод главных компонент с последующим варимакс-вращением). При использовании критерия Кайзера выделилось 3 фактора с собственными значениями >1, они объясняют 60,37% дисперсии, однако по критерию «каменистой осыпи» очевидно выделяются 5 факторов (рис. 1). Собственные значения 4-го и 5-го факторов <1, и они вносят дополнительно по 7% в объяснение дисперсии. Пятифакторная структура отражает априорную структуру опросника: Accessibility, Functionality, Conversation, Privacy и Responsiveness. Первый фактор (36,1% дисперсии) определяет воспринимаемое качество диалога и предоставленной информации, второй фактор (13,8%) — воспринимаемое качество функций чат-бота, третий фактор (10,5%) — воспринимаемая доступность функций чат-бота, четвертый фактор (7,6%) — время отклика, и пятый (7,5%) — воспринимаемые конфиденциальность и безопасность (см. табл. 3).
Таблица 3 / Table 3
|
Матрица повернутых компонент Rotated Component Matrix |
|||||
|
|
Компоненты / Components |
||||
|
1 |
2 |
3 |
4 |
5 |
|
|
9. Ответы чат-бота всегда были точными / I feel like the chatbot’s responses were accurate |
,841 |
|
|
,104 |
,252 |
|
8. Чат-бот предоставлял мне только ту информацию, которая была мне нужна / The chatbot only gives me the information I need |
,840 |
|
|
,169 |
|
|
7. Чат-бот предоставил мне необходимый объем информации / The chatbot gives me the appropriate amount of information |
,705 |
,184 |
,291 |
|
,124 |
|
6. Чат-бот «понимал», чего я хочу, и помогал мне достичь цели / I find that the chatbot understands what I want and helps me achieve my goal |
,648 |
,351 |
|
,175 |
|
|
4. Чат-бот мог отслеживать контекст взаимодействия / The chatbot was able to keep track of context |
,167 |
,857 |
|
|
,262 |
|
3. Коммуникация с чат-ботом была понятной / Communicating with the chatbot was clear |
,159 |
,659 |
,368 |
,285 |
-,131 |
|
5. Ответы чат-бота были просты для понимания / The chatbot’s responses were easy to understand |
,283 |
,562 |
|
,447 |
-,254 |
|
1. Доступ к чат-боту был прост и удобен / The chatbot function was easily detectable |
,114 |
|
,876 |
|
|
|
2. Функции чат-бота были доступны и понятны / It was easy to find the chatbot |
|
,368 |
,777 |
,154 |
|
|
11. Ожидание ответа от чат-бота занимало мало времени / My waiting time for a response from the chatbot was short |
,159 |
|
,181 |
,887 |
,177 |
|
10. Мне кажется, что чат-бот проинформирует меня о любых возможных проблемах с конфиденциальностью / I believe the chatbot informs me of any possible privacy issues |
,269 |
|
|
,126 |
,901 |
Метод выделения: анализ главных компонент; метод вращения: варимакс с нормализацией Кайзера; вращение сошлось за 8 итераций
Extraction Method: Principal Component Analysis; Rotation Method: Varimax with Kaiser Normalization; Rotation converged in 8 iterations.
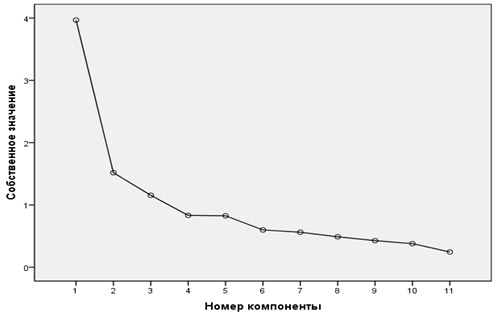
Рис. 1. График собственных значений
Fig. 1. Scree plot
В соответствии с априорной структурой опросника, с помощью конфирматорного факторного анализа была проверена модель удобства пользования чат-ботом, состоящая из пяти факторов. 5-факторная модель показала неудовлетворительное соответствие данным (χ2 = 40492, df = 66, χ2/df = 613) и необходимость дальнейшей корректировки. Эксплораторный факторный анализ показал условность выделения 4-го и 5-го факторов в структуре данных, и их исключение предопределило возможность проверки двух других моделей, первая из которых – 3-факторная, BUS9_3, — представлена на рис. 2, и вторая — трехфакторная, с вторичным фактором BUS9_1_3, описывающим удобство использования чат-бота в целом, — представлена на рис. 3. В табл. 4 приведены показатели соответствия этих конфирматорных моделей и критерии согласия исходным данным.
Таблица 4 / Table 4
Показатели согласия моделей BUS9_3 и BUS9_1_3
Goodness-of-fit indices for the BUS9_3 and BUS9_1_3 models
|
Metric |
BUS9_3 |
BUS9_1_3 |
|
NPAR |
21.0 |
22.0 |
|
CMIN/DF |
2.3 |
2.342 |
|
RMR |
0.058 |
0.055 |
|
GFI |
0.944 |
0.945 |
|
CFI |
0.944 |
0.945 |
|
TLI |
0.916 |
0.914 |
|
RMSEA |
0.079 |
0.081 |
|
LO 90 (RMSEA) |
0.052 |
0.053 |
|
HI 90 (RMSEA) |
0.107 |
0.109 |
|
AIC |
97.199 |
97.877 |
|
BIC |
167.186 |
171.197 |
|
HOELTER (0.05) |
136.0 |
135.0 |
Оценка качества моделей BUS9_3 и BUS9_1_3 проводилась на основе ключевых показателей. Результаты анализа продемонстрировали, что оба варианта моделей показали хорошее качество согласия с данными. Модель BUS9_3 имела допустимые значения ключевых метрик согласия, таких как CMIN/DF, RMSEA, RMR и CFI, что указывает на ее надежность и соответствие данным. BUS9_1_3 также продемонстрировала хорошие показатели согласия по метрикам CMIN/DF, RMSEA, RMR и CFI с минимальными отличиями от модели BUS9_3. Оба варианта находятся в пределах рекомендуемых диапазонов показателей, что подтверждает их качество. С точки зрения экономичности модель BUS9_3 показала лучшие результаты по критериям AIC и BIC, что делает ее предпочтительным выбором в условиях, требующих оптимизации модели. Однако модель BUS9_1_3 продемонстрировала небольшое преимущество по отдельным критериям согласия, включая CFI и RMR, что позволяет рассматривать ее как сопоставимый вариант. Прогнозируемая устойчивость, оцененная по критерию HOELTER, показала достаточную надежность обеих моделей, подтверждая их пригодность для использования в последующем анализе и интерпретации данных. Таким образом, модель BUS9_3 демонстрирует более высокую экономичность, в то время как модель BUS9_1_3 обладает незначительными преимуществами в отдельных показателях качества согласия. Оба варианта можно считать надежными для интерпретации, с минимальными различиями между ними.
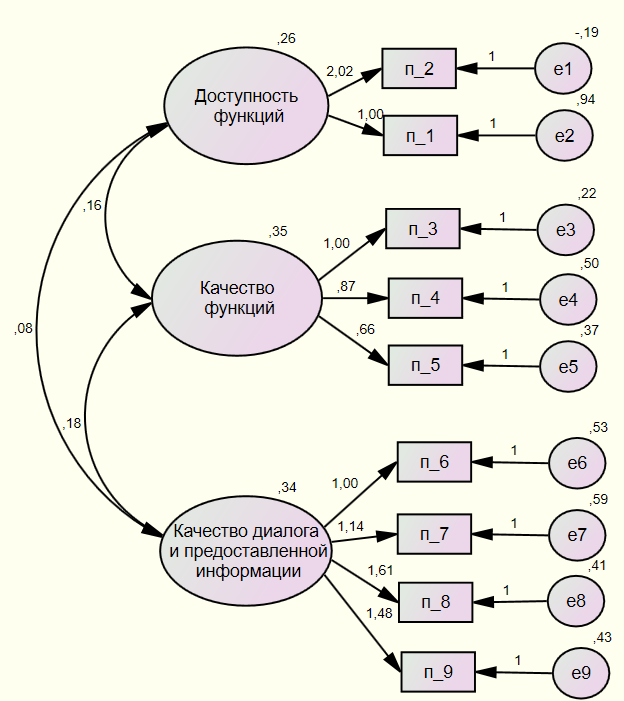
Рис. 2. Модель BUS — 3 фактора
Fig. 2. The BUS model — 3 factors
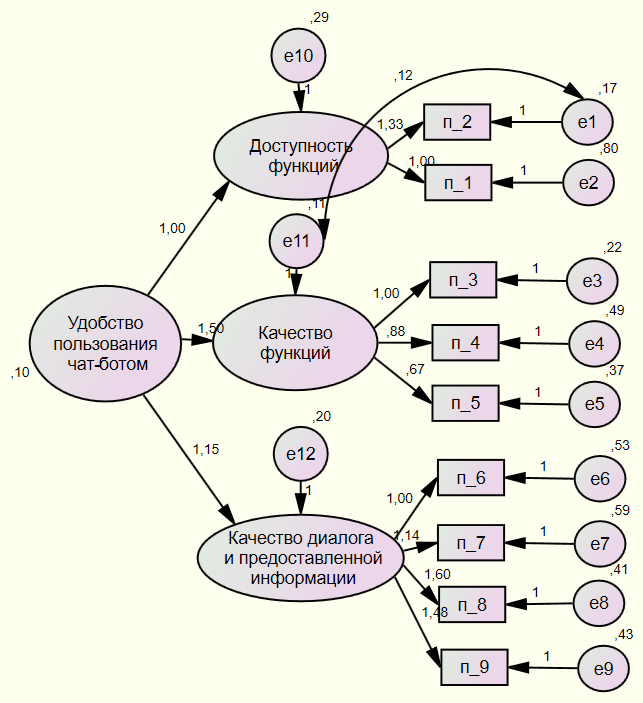
Рис. 3. Модель BUS с вторичным фактором
Fig. 3. The BUS model with a secondary factor
Оценка ретестовой надежности методик проводилась с интервалом в 1 месяц в течение 3 недель. Из числа всех участников повторно согласились участвовать в исследовании 98 человек. Коэффициент корреляции Спирмена (r) для русскоязычной версии BUS11 составил 0,83, что свидетельствует о высокой степени ретестовой надежности методики.
- Конвергентная и дивергентная валидность
Для оценки конвергентной валидности был проведен корреляционный анализ между общим показателем «Удобство пользования чат-ботом» и показателями опросника UMUX-LITE (Lewis, Utesch, Maher, 2013) и краткой формы шкалы AttrakDiff (Hassenzahl, Monk, 2010). Результаты представлены в табл. 5.
Таблица 5 / Table 5
Корреляции между общим показателем «Удобство пользования чат-ботом» и показателями опросника UMUX-LITE и краткой формы шкалы AttrakDiff
Correlations between the overall score of “Chatbot Usability” and the scores of the UMUX-LITE questionnaire and the short version of the AttrakDiff scale
|
|
N |
Удобство использования бота по UMUX-LITE / Bot Usability by UMUX-LITE |
Прагматическое качество чат-бота по AttrakDiff / Pragmatic Quality of the Chatbot by AttrakDiff |
Гедоническое качество чат-бота по AttrakDiff / Hedonic Quality of the Chatbot by AttrakDiff |
Общая привлекательность чат-бота по AttrakDiff / Overall Attractiveness of the Chatbot by AttrakDiff |
Удовлетворенность жизнью /Life Satisfaction |
|
Удобство пользования чат-ботом — BUS / Chatbot Usability — BUS |
207 |
0,845** |
0,726** |
0,732** |
0,767** |
0,12 |
Примечание: «**» — корреляция значима на уровне 0,01 (двусторонняя).
Note: «**» — correlation is significant at the 0.01 level (two-sided).
Результаты проверки конвергентной и дивергентной валидности методики BUS-11 подтвердили ее надежность и валидность. Высокая положительная корреляция с показателями удобства использования по UMUX-LITE (r = 0,845), прагматическим качеством (r = 0,726), гедоническим качеством (r = 0,732) и общей привлекательностью (r = 0,767) по AttrakDiff указывает на высокую конвергентную валидность BUS, демонстрируя ее способность измерять аспекты удобства и качества взаимодействия с чат-ботом. В то же время слабая корреляция с удовлетворенностью жизнью (r = 0,12) подтверждает дивергентную валидность методики, показывая, что BUS фокусируется исключительно на аспектах, связанных с удобством использования, и не затрагивает сторонние конструкты. Таким образом, BUS подтверждает свою применимость для оценки удобства использования чат-ботов.
Обсуждение результатов
Сравнение адаптированной методики с оригинальной версией показывает, что, несмотря на культурные и языковые различия, адаптированный инструмент сохранил ключевые аспекты, необходимые для анализа пользовательского опыта. Выявленное смещение индекса сложности в сторону «легкости» может быть объяснено тем, что люди выбирают чат-боты, обеспечивающие приятное и комфортное взаимодействие. Высокий индекс сложности для некоторых пунктов свидетельствует о том, что пользователи не хотят продолжать взаимодействие с технологиями, вызывающими у них дискомфорт или раздражение. На уровень воспринимаемого комфорта при взаимодействии с чат-ботом влияют такие факторы, как персонализация опыта, интуитивный дизайн, предоставление четких и релевантных ответов (Chagas et al., 2023; Weeks et al., 2023). Если взаимодействие с чат-ботом воспринимается как некомфортное или неэффективное, пользователи начинают искать другие варианты, которые соответствуют их требованиям (Balderas et al., 2023; Dhiman, Jamwal, 2023).
В результате эксплораторного факторного анализа было выделено пять факторов, но 2 из них имеют собственные значения <1. Конфирматорный факторный анализ подтвердил трехфакторную структуру. Анализ трехфакторной структуры данных показывает различия в факторных нагрузках по сравнению с результатами, представленными в исследовании Борши с соавт. (Borsci et al., 2023b). Если в оригинальной версии фактор, связанный с воспринимаемым качеством диалога и предоставленной информацией, является третьим по величине факторной нагрузки, в нашем исследовании он получил наибольшую факторную нагрузку. Возможно, в культурном контексте, где акцент делается на личных отношениях (что характерно для России) (Власян, Кожухова, 2019; Лихачева, 2017), пользователи ожидают эмоциональную и содержательную насыщенность в диалогах с чат-ботами, стремясь к «человеческому» общению. Как следствие, они могут быть более терпеливы к недостаткам в функциональности, если их удовлетворяет качество самого общения. В исследовании Борши и соавт. (Borsci et al., 2023b) доступность функций чат-бота оказалась на первом месте по величине факторной нагрузки, в нашем же исследовании этот фактор получил третью по величине факторную нагрузку. Вероятно, для респондентов из европейских стран характерен более высокий уровень ожиданий относительно функций и доступности. То обстоятельство, что фактор, связанный со скоростью ответа чат-бота, оказался незначимым по результатам факторного анализа, также может служить подтверждением тому, что русскоязычные пользователи имеют более низкий уровень ожиданий от функциональности чат-ботов и делают акцент на содержании диалога. Результаты также показали, что для респондентов из России вопросы, связанные с конфиденциальностью и безопасностью, не являются значимыми, в отличие от респондентов из исследования Борши с соавт. (Borsci et al., 2023b), что может быть объяснено разницей в правовых и социальных нормах. Общий регламент по защите данных способствует формированию культуры осведомленности о конфиденциальности у европейских пользователей, побуждая их более ответственно относиться к защите персональных данных (Prince, Omrani, Schiavone, 2024). Описанные выше различия также могут быть объяснены спецификой взаимодействия с чат-ботами на основе генеративного искусственного интеллекта и CRM-чат-ботами. Исследования показывают, что такие чат-боты, как ChatGPT, способны на проявление эмпатии и помогают справляться с различными межличностными проблемами (Brin et al., 2023; Elyoseph et al., 2023). Как следствие, пользователи могут ожидать более эмоционального вовлечения и «человеческого» общения от взаимодействия с чат-ботами на основе генеративного ИИ. В свою очередь, взаимодействие с CRM-чат-ботами предполагает акцент на эффективности и доступности функций, поскольку эти чат-боты часто используются для обработки стандартных вопросов и решения рутинных задач (Lin, Huang, Yang, 2023; Mathur, Tiwari, 2023; Sahata Sitanggang et al., 2023).
Сравнение моделей BUS9_3 (трехфакторная модель) и BUS9_1_3 (трехфакторная модель с вторичным фактором) демонстрирует их близость при оценке согласия и качества, однако модель BUS9_3 показывает более высокую экономичность, что делает ее предпочтительной для применения в условиях ограничения ресурсов. Модель BUS9_1_3 с вторичным фактором подходит для более детализированного анализа удобства использования. Таким образом, выбор между моделями зависит от целей исследования: для общей интерпретации предпочтительна BUS9_3, в то время как BUS9_1_3 может быть полезна для более тщательного изучения аспектов взаимодействия человека и чат-бота.
Результаты анализа конвергентной валидности продемонстрировали высокую положительную корреляцию между общим показателем удобства пользования чат-ботами по шкале BUS-11 и показателями, полученными с помощью других известных методик. В частности, корреляция (r = 0,845) с UMUX-LITE (Lewis, Utesch, Maher, 2013) указывает на то, что оба инструмента измеряют схожие аспекты удобства использования. Это подтверждает выводы валидности BUS-11 как инструмента для оценки пользовательского опыта. Похожие результаты были получены в других исследованиях (Borsci et al., 2023a; Borsci et al., 2023b), которые показывают высокие уровни корреляции между BUS-15 и UMUX-LITE. Сильная корреляционная связь с прагматическим качеством (r = 0,726) и гедоническим качеством (r = 0,732) по шкале AttrakDiff (Hassenzahl, Monk, 2010) подтверждает, что BUS-11 эффективно охватывает аспекты, относящиеся как к функциональности, так и к субъективной привлекательности чат-ботов. Исследование также подтвердило дивергентную валидность опросника, поскольку отсутствовала значимая связь с показателем общей удовлетворенности жизнью. Это говорит о том, что шкала BUS-11 концентрируется на специфических аспектах взаимодействия с чат-ботами, не смешивая эти оценки с общими жизненными установками.
Результаты нашего исследования открывают несколько направлений для будущих исследований с использованием адаптированной методики для оценки удобства пользования чат-ботом. Во-первых, стоит обратить внимание на влияние демографических характеристик пользователей, таких как возраст и образование, на их восприятие чат-ботов. Во-вторых, особое внимание стоит уделить изучению динамики восприятия чат-ботов: как изменяется удобство их использования со временем и при накоплении опыта взаимодействия. В-третьих, также возможно рассмотреть применение адаптированного опросника в различных областях, таких как здравоохранение, образование и обслуживание клиентов, чтобы оценить, как специфические контексты влияют на удобство использования.
Заключение
Адаптация опросника для оценки удобства использования чат-ботов на основе генеративного ИИ продемонстрировала высокую надежность и валидность инструмента. Было верифицировано три фактора: воспринимаемое качество диалога и предоставленной информации, воспринимаемое качество функций чат-бота и воспринимаемая доступность функций. Оценка качества конфирматорных моделей показала, что оба варианта подходят для использования в исследованиях. Полученные результаты демонстрируют, как лингвокультурные различия влияют на восприятие удобства использования чат-ботов: респонденты из России ожидают более активного участия чат-бота в коммуникации, придавая важность качеству диалога, а пользователи из европейских стран акцентируют внимание на технических аспектах и удобстве доступа к чат-боту, что отражает различия в восприятии технологий.
Ограничения. В исследовании приняли участие в основном высокообразованные респонденты с опытом использования чат-ботов, что может приводить к смещению результатов в сторону более позитивной оценки удобства использования. Адаптация и валидизация опросника проводились на опыте взаимодействия с различными чат-ботами на основе генеративного ИИ, в то время как восприятие пользователя может варьироваться в зависимости от конкретной платформы и контекста использования. Кросс-секционный дизайн исследования не позволяет установить причинно-следственные связи и проследить динамику изменения восприятия удобства использования в долгосрочной перспективе.
Limitations. The study potentially suffers from selection bias, as the sample primarily consisted of highly educated respondents with prior experience using chatbots, which may skew the results towards a more positive assessment of usability. The adaptation and validation of the questionnaire were based on experiences with various generative AI-based chatbots, while user perception may vary depending on the specific platform and context of use. The cross-sectional design of the study limits the ability to establish causal relationships and track the dynamics of usability perception changes over the long term.