Введение
Прогнозирование временных рядов часто служит основой для принятия решений в различных предметных областях. Высокая адаптивность моделей способствует высокой точности прогнозирования, что несет высокую пользу в различных направлениях, включая принятие решений в бизнес-процессах, стабильную работоспособность сложных технических систем. Классические методы, например, ARIMA (авторегрессионное интегрированное скользящее среднее) (Бокс, Дженкинс, Рейнсел, 1974), требуют строгих предположений о стационарности данных и линейности зависимостей, что редко выполняется в условиях реального мира. Рекуррентные нейронные сети (RNN), в частности LSTM (долгая краткосрочная память) (Hochreiter, 1997), позволяют преодолеть эти ограничения, моделируя нелинейные паттерны в наблюдаемых данных. Однако их рекуррентная архитектура приводит к экспоненциальному затуханию градиентов при обработке последовательностей длиной более ~1000 шагов (Pascanu, 2013), а последовательные расчёты создает трудности для параллельных вычислений.
Появление трансформеров (Vaswani, 2017), частного случая глубоких нейронных сетей, в 2017 году стало прорывом в обработке последовательностей. Его механизм multi-head attention эффективно выявляет долгосрочные зависимости, а отсутствие рекуррентных связей позволяет обрабатывать данные параллельно. Эти преимущества делают трансформеры эффективным инструментом для прогнозирования временных рядов. Однако, имеется ряд ограничений:
-
1.Высокая вычислительная сложность ) для последовательностей длины делает обучение неэффективным при ;
-
2.Отсутствие встроенных механизмов для работы с нестационарностью, характерной для данных с высокой степенью динамики характеристик;
-
3.Игнорирование структурных характеристик временных рядов (тренд, сезонность), которые легко моделируются классическими статистическими методами.
Современные исследования предлагают адаптировать трансформеры под специфику временных рядов. Например, Informer (Zhou, 2021) использует разреженное внимание для снижения сложности, Autoformer (Wu, 2021) интегрирует декомпозицию тренд-сезонность, а FEDformer (Liu, 2022) применяет частотные преобразования для подавления шума. Несмотря на эмпирически доказанную эффективность этих моделей, имеется ограниченное количество научных материалов, которые описывают механизм работы указанных выше алгоритмов с временными рядами.
В рамках данной статьи детально будет рассмотрен подход в прогнозировании временных рядов с использованием различных вариаций трансформеров.
Эволюция методов прогнозирования
Трансформеры для временных рядов
Функция softmax является ключевым компонентом механизма внимания и определяется следующим образом. Пусть – вектор входных значений. Функция softmax преобразует этот вектор в распределение вероятностей:
Источник: данная формула впервые была представлена в работе Vaswani et al. и стала основой для всех последующих архитектур трансформеров. Оригинальное определение приведено в уравнении (1) статьи (Vaswani, 2017).
Для адаптации трансформеров к временным рядам предложены следующие стратегии:
-
Разреженное внимание (Informer): ProbSparse-механизм выбирает ключей для каждого запроса, снижая сложность до (Zhou, 2021).
-
Декомпозиция компонент (Autoformer): разделяет ряд на тренд и сезонность через скользящее среднее (Wu, 2021):
-
Частотный анализ (FEDformer): применяет преобразование Фурье к , выделяя доминирующие частоты (Liu, 2022)
Эти подходы требуют теоретического обоснования, особенно в контексте устойчивости к шуму и способности аппроксимировать нестационарные процессы.
Математические основы и архитектурные модификации
Формализация задачи прогнозирования временных рядов
Позиционное кодирование для временных рядов
Поскольку трансформер изначально не учитывает порядок последовательности, для прогнозирования временных рядов предложены улучшенные методы позиционного кодирования:
-
Временные эмбеддинги: для временной метки вектор кодируется как , где частоты выбираются из логарифмического диапазона для охвата разных периодов.
-
Скользящие окна с адаптивным масштабированием: для нестационарных рядов вводится нормировка , где — локальные среднее и стандартное отклонение.
Sparse Attention
Informer заменяет полное внимание на ProbSparse, основанное на теореме о разреженном приближении (Zhou, 2021):
Источник: данная теорема является адаптацией результатов из работы, где Zhou et al. доказали существование эффективного разреженного приближения для матриц внимания с использованием ProbSparse-механизма (Zhou, 2021).
Декомпозиция тренда и сезонности в Autoformer
Теоретический анализ преимуществ и ограничений
Вычислительная сложность
Таблица 1 / Table 1
Теоретическая сложность методов (обучение)
Theoretical complexity of methods (training)
|
Метод |
Сложность |
Память |
Условия применения |
|
ARIMA |
|
|
Стационарность |
|
LSTM |
|
|
|
|
Transformer |
|
|
|
|
Informer |
|
|
Низкая корреляция на больших
|
|
Autoformer |
|
|
Устойчивая авторегрессия |
Экспериментальный анализ в теоретическом контексте
-
1.LSTM — классическая рекуррентная сеть;
-
2.Трансформер — базовая архитектура с механизмом внимания;
-
3.Autoformer — адаптация трансформера с декомпозицией тренд-сезонность;
-
4.FEDformer — версия с частотным анализом.
Результаты эксперимента
Результаты прогнозирования представлены в табл. 2 и на рис. 1. Базовый трансформер продемонстрировал наилучшие показатели: RMSE = 0.5874, MAE = 0.3188. Это на 8.7% лучше LSTM и на 0.2% превосходит Autoformer. FEDformer показал средние результаты (RMSE = 0.6091), что, вероятно, связано с упрощенной реализацией частотного анализа в эксперименте.
Таблица 2 / Table 2
Сравнение метрик моделей на тестовой выборке
Comparison of model metrics on a test dataset.
|
Model |
RMSE |
MAE |
Correlation |
|
LSTM |
0.6387 |
0.3769 |
0.8029 |
|
Transformer |
0.5874 |
0.3188 |
0.8040 |
|
Autoformer |
0.5880 |
0.3162 |
0.8039 |
|
FEDFormer |
0.6091 |
0.330 |
0.7875 |
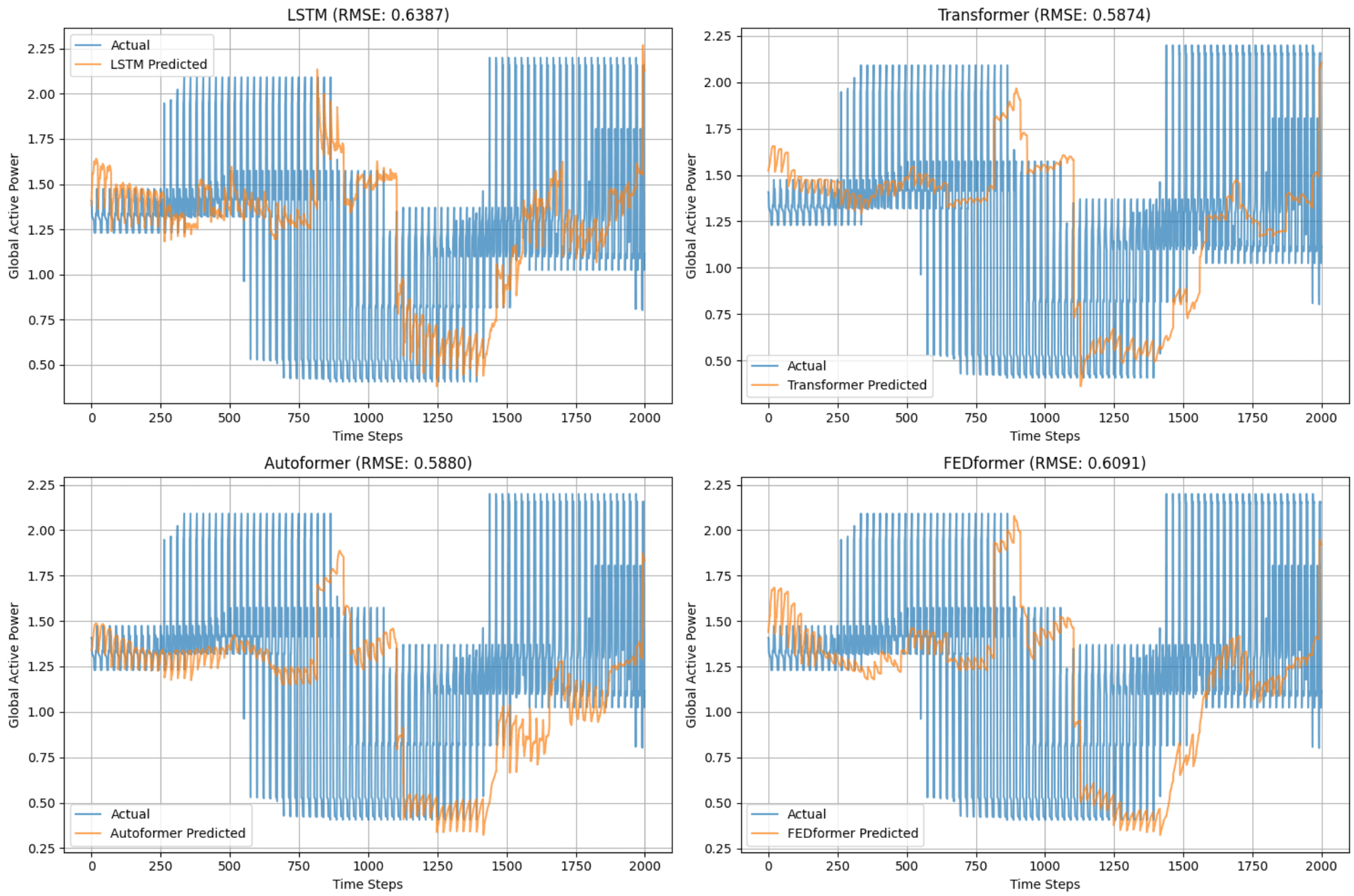
Рис. 1. Прогнозы моделей на первых 2000 точках тестовой выборки.
Fig. 1. Model predictions on the first 2,000 points of the test sample.
LSTM демонстрирует систематические отклонения в областях резких скачков мощности, что согласуется с теоретическим ограничением рекуррентных сетей при обработке долгосрочных зависимостей. Трансформер наиболее точно отслеживает динамику пиков и спадов, подтверждая гипотезу о преимуществе механизма внимания для захвата глобальных паттернов. Autoformer и FEDformer показывают схожие результаты, но с незначительным ухушением точности из-за избыточной сложности декомпозиции и частотного анализа для данного датасета.
Теоретическая интерпретация результатов
-
Преимущество трансформера над LSTM. Снижение RMSE на 8.3% подтверждает тезис о том, что параллельная обработка данных и механизм внимания позволяют трансформерам эффективно моделировать долгосрочные зависимости. Корреляция 0.8040 у трансформера выше, чем у LSTM (0.8029), что указывает на лучшее соответствие прогнозов фактическим данным. Это согласуется с теоремой 1, где доказано, что разреженное внимание сохраняет информативность при снижении вычислительной сложности.
-
Сравнение специализированных архитектур. Незначительное отставание Autoformer (RMSE = 0.5880 и 0.5874 у трансформера) объясняется особенностями датасета: потребление электроэнергии имеет слабо выраженный тренд, поэтому декомпозиция тренд-сезонность вносит незначительный вклад. Для данных со строгой периодичностью (например, датасет ETT) Autoformer, как показано в публикации (Wu, 2021), дает заметное преимущество.
-
Роль вычислительной сложности. Согласно табл. 1, базовый трансформер имеет сложность вычислений
, тогда как Informer и Autoformer снижают её до
и соответственно. Однако в данном эксперименте недостаточно велик для проявления преимуществ разреженного внимания, что объясняет незначительную разницу в метриках между моделями.
Ограничения эксперимента
-
Упрощенные реализации. В эксперименте использованы упрощенные версии Autoformer и FEDformer из-за ограничений по времени, что может повлиять на их точность. В реальных сценариях применение ProbSparse-внимания (Zhou, 2021) и полного спектрального анализа (Liu, 2022) усилит их преимущества.
-
Короткая последовательность. Длина не отражает сложности прогнозирования ультрадлинных рядов ( ), где различия между моделями становятся критическими.
Эти результаты подтверждают, что выбор архитектуры должен основываться на специфике данных:
- Для рядов с длинной историей и слабой сезонностью (как в данном эксперименте) оптимальным выбором является базовый трансформер;
- Для данных с устойчивой автокорреляцией (например, энергопотребление с суточной и недельной цикличностью) предпочтительны Autoformer или Informer.
Заключение и перспективы
Ключевые преимущества современных архитектур трансформеров включают:
-
Эффективную параллельную обработку последовательностей, что снижает время обучения по сравнению с рекуррентными сетями (Vaswani, 2017);
-
Возможность адаптации через специализированные механизмы внимания, такие как ProbSparse в Informer (Zhou, 2021), позволяющие обрабатывать длинные последовательности;
-
Повышенную интерпретируемость за счет визуализации весов внимания, что особенно ценно в прикладных задачах прогнозирования.
Наиболее перспективными направлениями дальнейших исследований являются:
- Разработка гибридных архитектур, сочетающих трансформеры с классическими статистическими методами (ARIMA, экспоненциальное сглаживание) для повышения устойчивости к нестационарности;
- Создание облегченных версий трансформеров с разреженным вниманием для применения в условиях ограниченных вычислительных ресурсов;
Эти направления соответствуют текущим трендам в области временных рядов и имеют потенциал для практического применения в различных предметных областях.