Контекст и актуальность. Задача агрегирования индивидуальных предпочтений в групповое ранжирование является фундаментальной в теории принятия решений. Медиана Кемени — один из наиболее аксиоматически обоснованных критериев консенсуса, однако ее нахождение относится к классу NP-трудных задач и требует перебора n! вариантов. Метод декомпозиции на основе мажоритарного графа позволяет разбить исходную задачу на независимые подзадачи внутри компонент сильной связности (КСС), что теоретически снижает сложность до O(n_max!), где n_max — размер максимальной КСС. Практическая эффективность данного подхода остается недостаточно изученной. Цель. Оценить вероятность и глубину декомпозиции мажоритарного графа в зависимости от степени согласованности экспертных мнений. Гипотеза. Эффективность декомпозиции (размер максимальной КСС) напрямую связана с уровнем внутренней когерентности группы: метод должен быть наиболее эффективен при минимальных внутренних противоречиях. Методы и материалы. Проведено статистическое моделирование на трех последовательно усложняющихся моделях данных: (M1) независимые случайные линейные порядки; (M2) линейные порядки с перестановкой p пар от эталонного порядка; (M3) турниры с контролируемым отклонением (r — степень отклонения индивидуальных мнений от эталонного турнира). Для каждого набора параметров (n = 35, m = {3,5,7,9}, N = 100 000 для М1 и М2, n = 35, m = {5,6,7,8}, N = 10 000 для М3) строился мажоритарный граф, выделялись КСС и фиксировался размер максимальной компоненты n_max. Результаты. В модели M1 декомпозиция статистически незначима (M[n_max] = n ̃ ≈ n-1). В модели M2 эффективность метода резко возрастает с уменьшением (для m = 9 при p = 10: n ̃= 25,580, а при p = 5: n ̃= 10,285). В модели M3 обнаружена устойчивая U-образная зависимость от степени отклонения r: минимальные значения (высокая эффективность) достигаются при r → 0 (консенсус) и r → 1 (поляризация), максимальные (низкая эффективность) — в области r ≈ 0,5 (минимальная когерентность). Выводы. Показано, что метод декомпозиции наиболее полезен для сильно согласованных (как при консенсусе с эталоном, так и при поляризации от эталона) и малоэффективен для групп с максимально разнородными мнениями. Быстрый анализ КСС мажоритарного графа служит диагностическим инструментом для априорной оценки сложности задачи: значение n_max позволяет обоснованно выбирать между точными алгоритмами (при малых n_max) и эвристическими (при больших n_max).
Для цитаты:Нефедов, В.Н., Силаева, В.С. (2026). Оценка эффективности декомпозиции задачи нахождения линейной медианы Кемени на основе анализа мажоритарного графа. Моделирование и анализ данных,16(1), 105–124. https://doi.org/10.17759/mda.2026160107
Рассматривается задача группового выбора, состоящая в нахождении результирующей ранжировки, в наибольшей степени учитывающей индивидуальные предпочтения членов группы.
Существуют различные подходы к решению данной задачи: включая классические теории Ш. Борда и Н. Кондорсе (Миркин, 1974), концепция рационального выбора группы К. Эрроу (Мулен, 1991), а также методы, базирующиеся на анализе близости бинарных отношений (Young, 1988; Петровский, 2009, Нефедов и др., 2018). В данной работе в качестве оптимального агрегированного ранжирования рассматривается линейная медиана Кемени — линейный порядок, минимизирующий сумму расстояний Хемминга до индивидуальных предпочтений. Данный критерий обладает рядом аксиоматических преимуществ и интерпретируется как отражение максимального консенсуса внутри группы (Kemeny, 1959).
Однако нахождение медианы Кемени представляет собой NP-трудную вычислительную задачу (Bartholdi, Tovey, Trick, 1989; Hudry, 2012). Существующие алгоритмы решения данной задачи можно разделить на эвристические, не гарантирующие оптимальности (Петровский, 2009; Литвак, 1982; Корнеенко, 2018; Cook, 2006), и точные, основанные на методах дискретной оптимизации (например, целочисленное программирование, метод ветвей и границ (Нефедов, Осипова, 2022; Azzini, Munda, 2020)). Точные методы в худшем случае требуют перебора перестановок (где — число альтернатив), что ограничивает их применимость на практике даже для умеренных . Это обуславливает необходимость разработки методов ускорения, использующих специфическую структуру задачи.
Одним из таких перспективных подходов является декомпозиция на основе мажоритарного графа. Мажоритарный граф отражает попарные отношения большинства между альтернативами. Известно, что задача поиска медианы Кемени может быть сведена к задаче устранения контуров в этом графе (Нефедов и др., 2018). Ключевая идея ускорения заключается в том, что, если мажоритарный граф не является сильно связным, его можно разложить на компоненты сильной связности (КСС). Задача поиска глобальной медианы при этом распадается на независимые подзадачи внутри каждой КСС, а их результаты объединяются в соответствии с ациклическим графом конденсации. Теоретически это позволяет снизить вычислительную сложность с до , где — размеры КСС, что эквивалентно , где .
Несмотря на очевидный теоретический потенциал, практическая эффективность данного подхода остается недостаточно изученной. Отсутствуют количественные оценки того, насколько часто и при каких условиях мажоритарный граф допускает нетривиальную декомпозицию, и как эффективность этой декомпозиции (размер максимальной КСС) зависит от степени согласованности экспертов.
Целью данного исследования является оценка эффективности метода декомпозиции мажоритарного графа для ускорения нахождения медианы Кемени на основе статистического анализа.
Для этого мы исследуем три последовательно усложняющиеся модели генерации профилей предпочтений: от независимых случайных порядков (M1), затем модель с умеренной согласованностью (М2) до модели с контролируемым уровнем согласованности (M3). Полученные количественные зависимости позволяют априорно оценить ожидаемую сложность задачи и определить условия, при которых декомпозиция дает максимальный вычислительный выигрыш.
Материалы и методы
Постановка задачи нахождения линейной медианы Кемени
Группа из лиц рассматривает несколько возможных вариантов (альтернатив) решения некоторой проблемы. Индивидуальные предпочтения членов группы в общем случае выражаются бинарными отношениями, и задают профиль бинарных отношений на .
Обозначим через совокупность всех линейных порядков на , т. е. бинарных отношений на , являющихся одновременно рефлексивными, антисимметричными, транзитивными и линейными. Под строгим ранжированием понимается любое отношение из , для нестрогого ранжирования необязательно условие антисимметричности. Расстояние между бинарными отношениями с матрицами , , где , будем задавать метрикой Хемминга:
В качестве реляционного правила агрегирования предлагается выбрать линейную медиану Кемени, т. е. результирующую строгую ранжировку, наиболее близкую в смысле метрики Хемминга к мнениям экспертов. Таким образом, рассматриваемая задача сводится к нахождению линейной ранжировки (в общем случае множества ранжировок), минимизирующей функцию
т. е.
В общем случае такая ранжировка может оказаться неединственной и потребуется нахождение всего множества
Построение мажоритарного графа
Процедура построения мажоритарного графа предлагается еще в работе (Миркин, 1974). Пусть имеется набор бинарных отношений с матрицами смежности , где , . Поставим ему в соответствие матрицы , .
Тогда для данного набора бинарных отношений рассмотрим мажоритарное отношение . Оно однозначно определяется по «правилу большинства» , где . Будем, кроме того, использовать нестрогий мажоритарный граф с множеством вершин и множеством дуг . Мажоритарный граф можно считать нагруженным, если поставить в соответствие каждой дуге вес . Определим матрицу весов этого графа:
Мажоритарный граф наиболее полно учитывает мнения группы экспертов, при этом удовлетворяет требованиям к групповым решениям: сохранение отношения Парето, монотонность, независимость. Однако основным недостатком является то, что мажоритарный граф с большой вероятностью не транзитивен и может содержать контуры.
Задача нахождения линейной медианы Кемени тождественна задаче разрушения контуров в мажоритарном графе (с минимизацией суммарного веса удаляемых дуг) и последующему расширению полученного ацикличного графа (или множества графов) до всех возможных линейных порядков.
Принцип декомпозиции задачи
Компонента сильной связности (КСС) — это максимальное по включению множество вершин, в котором для любой пары вершин существует ориентированный путь как из в , так и из в . Все ориентированные циклы (контуры) содержатся целиком внутри КСС. Для выделения КСС могут использоваться алгоритмы Косарайю или Тарьяна (Sharir, 1981; Tarjan, 1972), имеющие линейную сложность относительно числа вершин и дуг . Число дуг в графе не превосходит , поэтому трудоемкость поиска КСС .
После нахождения КСС мажоритарного графа строится граф конденсации . Вершинами этого графа являются найденные КСС (обозначим их ), а дуга от компоненты к компоненте проводится, если в исходном графе существует хотя бы одна дуга из некоторой вершины графа в некоторую вершину графа .
Граф конденсации всегда является ацикличным: так как наличие цикла между компонентами означало бы, что их вершины принадлежат одной КСС. Таким образом граф (точнее, его транзитивное замыкание) задает частичный порядок на множестве компонент.
Для каждой КСС независимо от других найдем «локальную» линейную медиану Кемени (или множество локальных линейных медиан) на множестве вершин графа . Затем рассмотрим прямое произведение всех возможных локальных медиан по всем КСС. Для каждого из случаев рассмотрим граф, полученный из мажоритарного графа заменой каждой из КСС на граф из найденного для этой КСС множества локальных медиан. Полученный в результате такой замены граф не содержит контуров, и его транзитивное замыкание является частичным порядком на всем множестве . Для получения совокупности всех линейных медиан Кемени необходимо всеми возможными способами расширить этот частичный порядок до линейного, к примеру алгоритмом Варола-Ротема (Varol, Rotem, 1981). Нетрудно показать, что любой полученный таким образом линейный порядок имеет одинаковое значение
.
Приведем также обоснование в обратную сторону. Если имеется некоторое общее решение (т.е. — оптимальный линейный порядок для общей задачи), то он порождает соответствующие «локальные» оптимальные линейные порядки на каждой из КСС, которые войдут в общий перебор для каждой из этих подзадач, а тем самым и в их набор, т.е. линейный порядок войдет в прямое произведение всех локальных медиан по всем КСС и будет учтен в общем решении задачи.
Описанный подход позволяет, например, применять описанный в (Нефедов, Осипова 2022) метод ветвей и границ решения общей задачи, использующий матрицу (будем его называть «матричным методом») не ко всей задаче, а к частным задачам, соответствующим КСС, т.е. осуществлять декомпозицию общей задачи на частные. Но, если применение этого метода ко всей задаче имеет естественные ограничения (не более 26–30 альтернатив), то это ограничение теперь будет относиться к частным задачам, что позволяет решать некоторые задачи указанным матричным методом при весьма большом числе альтернатив.
Рассмотрим следующий частный случай, когда мажоритарный граф обладает следующим свойствами: 1) является линейным порядком; 2) если , то для всех , верно Такой случай, например, возникает, если бинарные отношения являются линейными и асимметричными (турнирами) и — нечетно (Нефедов, 2022). В этом случае решение исходной задачи также основывается на ее декомпозиции на множество частных и сводится к следующим двум этапам:
Для каждой КСС найти все возможные локальные медианы (линейные порядки на множестве .
Объединить полученные ранжировки в глобальную линейную ранжировку на всем множестве в соответствии с линейным порядком, задаваемым графом конденсации (конкатенация линейных порядков).
Если для решения задачи необходимо найти не все множество медиан, а только одну из возможных, то можно свести задачу к частному случаю расширив каким-то одним способом до линейного и добавив дуги, чтобы для любых выполнялось: для всех , . Расширение частичного порядка до одного из возможных линейных порядков, может быть найдено топологической сортировкой (упорядочивание вершин ориентированного ациклического графа по уровням таким образом, чтобы все дуги были направлены от вершин с меньшим уровнем к вершинам с большим) и может быть выполнено всего за , к примеру алгоритмом Кана или алгоритмом Демукрона (Кормен и др., 2005).
Сложность решения исходной задачи в частном случае после декомпозиции определяется размером наибольшей из КСС ( ). Даже если внутри каждой компоненты применяется полный перебор, сложность составит порядка (с точностью до полиномиальных множителей). В лучшем случае мажоритарный граф ацикличен, все , и задача решается за полиномиальное время. В худшем случае граф сильно связен ( , ), и декомпозиция не дает выигрыша.
Модели генерации данных
Экспериментальное исследование было построено как последовательность трех моделей, каждая из которых устраняет ограничения или отвечает на вопросы, возникшие при анализе предыдущей. Все модели были реализованы для фиксированного числа альтернатив . Для каждого набора параметров проводилось (для M1, M2) или (для M3) независимых испытаний. В каждом испытании генерировался профиль предпочтений, строился мажоритарный граф, находились его КСС и определялся размер максимальной компоненты .
Модель M1: Базовый случай (нулевая априорная согласованность).
Цель модели — определение базового уровня эффективности декомпозиции в условиях максимальной неопределенности, когда мнения экспертов абсолютно независимы и случайны.
Профиль состоит из независимых случайных линейных порядков на множестве . Все возможных комбинаций равновероятны. Параметры модели: (нечетные).
Мы ожидали, что при полной случайности мажоритарный граф будет близок к случайному турниру, где вероятность существования большого контура высока, а значит, декомпозиция будет слабой. Результаты M1 подтвердили это: среднеожидаемый размер максимальной компоненты был близок к количеству альтернатив . Это показало, что в условиях полного хаоса метод декомпозиции не дает значимого выигрыша. Однако такая модель плохо отражает реальные ситуации, где мнения экспертов обычно в той или иной степени согласованы.
Модель M2: Управляемая согласованность на линейных порядках.
Цель модели М2: исследовать, как введение согласованности в предпочтения экспертов влияет на эффективность декомпозиции.
Профиль отношений генерируется следующим образом. Задается эталонный линейный порядок (мнение гипотетического идеального эксперта). Мнение каждого из экспертов (включая первого) получается из путем применения фиксированного числа случайных перестановок пар альтернатив. Параметры: (нечетные), .
В отличие от M1, здесь эксперты не независимы — их мнения отталкиваются от эталонного. Мы исследовали, как мера согласованности, контролируемая параметром p, влияет на . Результаты M2 показали существенный рост эффективности декомпозиции с уменьшением . Однако модель M2 имела методологическое ограничение: параметр — косвенная и нелинейная мера согласованности для всего профиля. Возникла потребность в модели с прямым и четким контролем над степенью согласованности.
Модель M3: Контролируемая согласованность на турнирах (обобщенный случай).
Цели модели М3: ввести прямую количественную меру согласованности профиля; обобщить исследование на более широкий класс предпочтений (турниры, не обязательно транзитивные).
Профиль отношений генерируется следующим образом. Задается эталонный турнир (в нашем случае соответствующий линейному порядку). Для каждого из остальных экспертов генерируется турнир , находящийся на заданном расстоянии Хемминга от . А именно: в матрице смежности инвертируется ровно случайных элементов вне диагонали. Это гарантирует, что при .
Параметр (смещение относительно эталона) может принимать значения от 0 до . Поэтому введем нормированный параметр — степень отклонения индивидуальных мнений от единого эталона . При все эксперты идентичны , при мнения диаметрально противоположны эталону (полная поляризация).
Параметры: , (т.к. k при данном может принимать значения от 0 до ). Т.к. принимает целых 59 значений, то было решено уменьшить количество тестов с до .
Модель M3 решает ключевые проблемы M2. Данная модель генерации позволяет получать профили с разным уровнем внутренней согласованности (когерентности) группы, которую мы измеряем как величину обратную среднему попарному расстоянию Хемминга между мнениями экспертов. При и внутренняя ожидаемая согласованность высока (консенсус и поляризация соответственно), а при — минимальна (максимальные разногласия). Это позволяет исследовать, как когерентность группы, а не просто случайность, влияет на структуру мажоритарного графа. Переход от линейных порядков к турнирам делает модель более общей. Также М3 позволяет изучать влияние четности числа экспертов .
Эта модель позволила выявить обратную U-образную зависимость среднеожидаемого размера максимальной КСС от степени отклонения индивидуальных мнений от единого эталона ( сначала увеличивается с увеличением , достигает максимума , затем уменьшается), что является основным результатом данной работы.
Метрика исследования
Основная метрика: — размер максимальной КСС мажоритарного графа для данного тестового профиля. Для анализа используются: распределение по тестам и среднеожидаемый размер максимальной компоненты для фиксированных .
Результаты
В данном разделе представлены статистические результаты вычислительных экспериментов для трех моделей генерации данных. Основной измеряемой величиной является размер максимальной компоненты сильной связности ( ) мажоритарного графа.
Для каждой серии экспериментов приводятся: распределение частоты встречаемости различных значений и среднеожидаемый размер максимальной компоненты при фиксированном .
Результаты модели М1
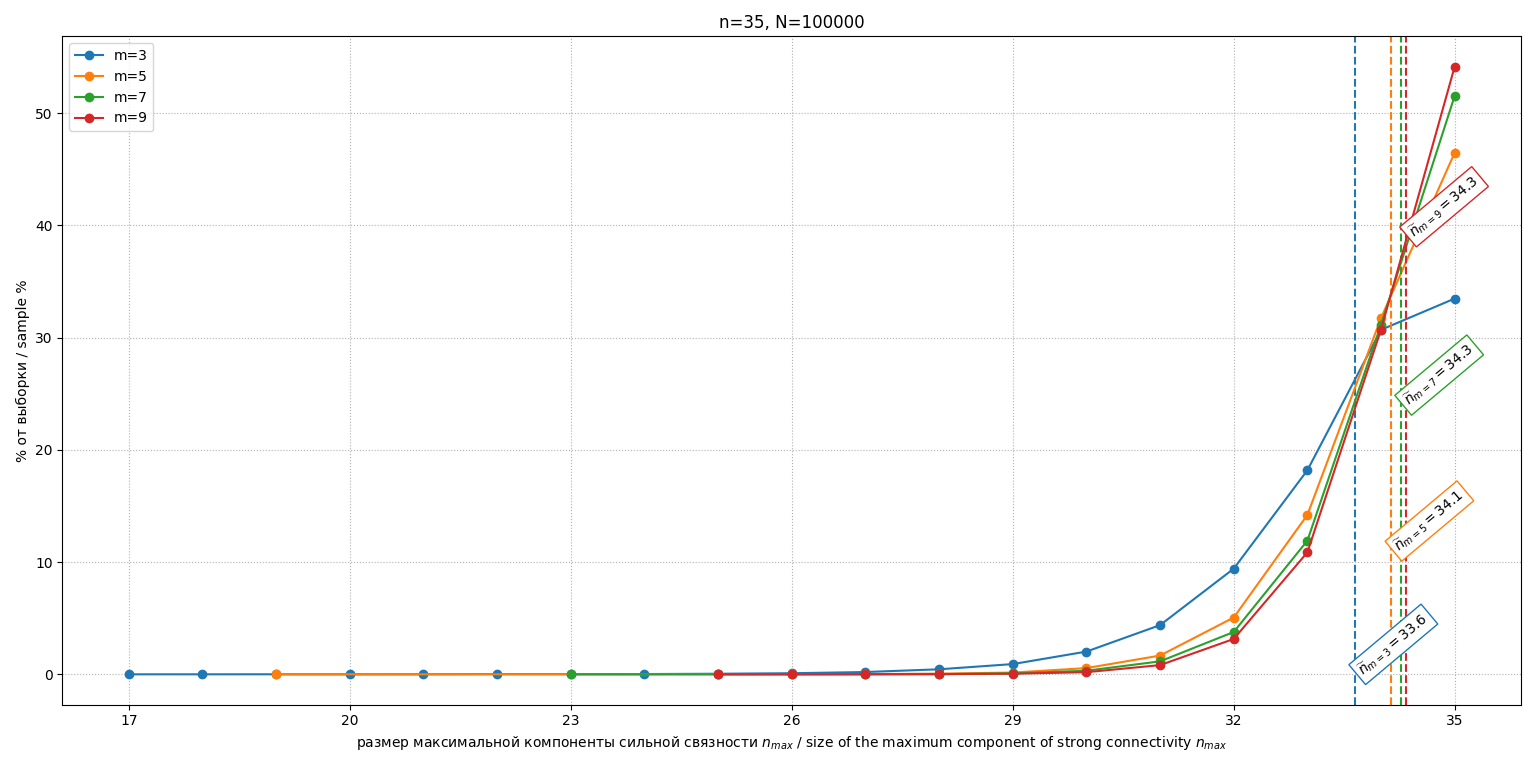
Было проведено по испытаний для каждого нечетного числа экспертов при фиксированном числе альтернатив . Гистограммы распределений для фиксированных изображены на рис. 1.
Рис. 1. Гистограммы распределений М1 Fig. 1. Histograms of nmax distributions of the M1 Среднеожидаемые размеры максимальной компоненты для фиксированного m представлены в табл. 1.
Таблица 1 / Table 1
Среднеожидаемый размер максимальной компоненты для М1 для разных
The expected average size of the maximum component for M1 for different
3
5
7
9
33,6
34,1
34,3
34,3
Результаты модели М2
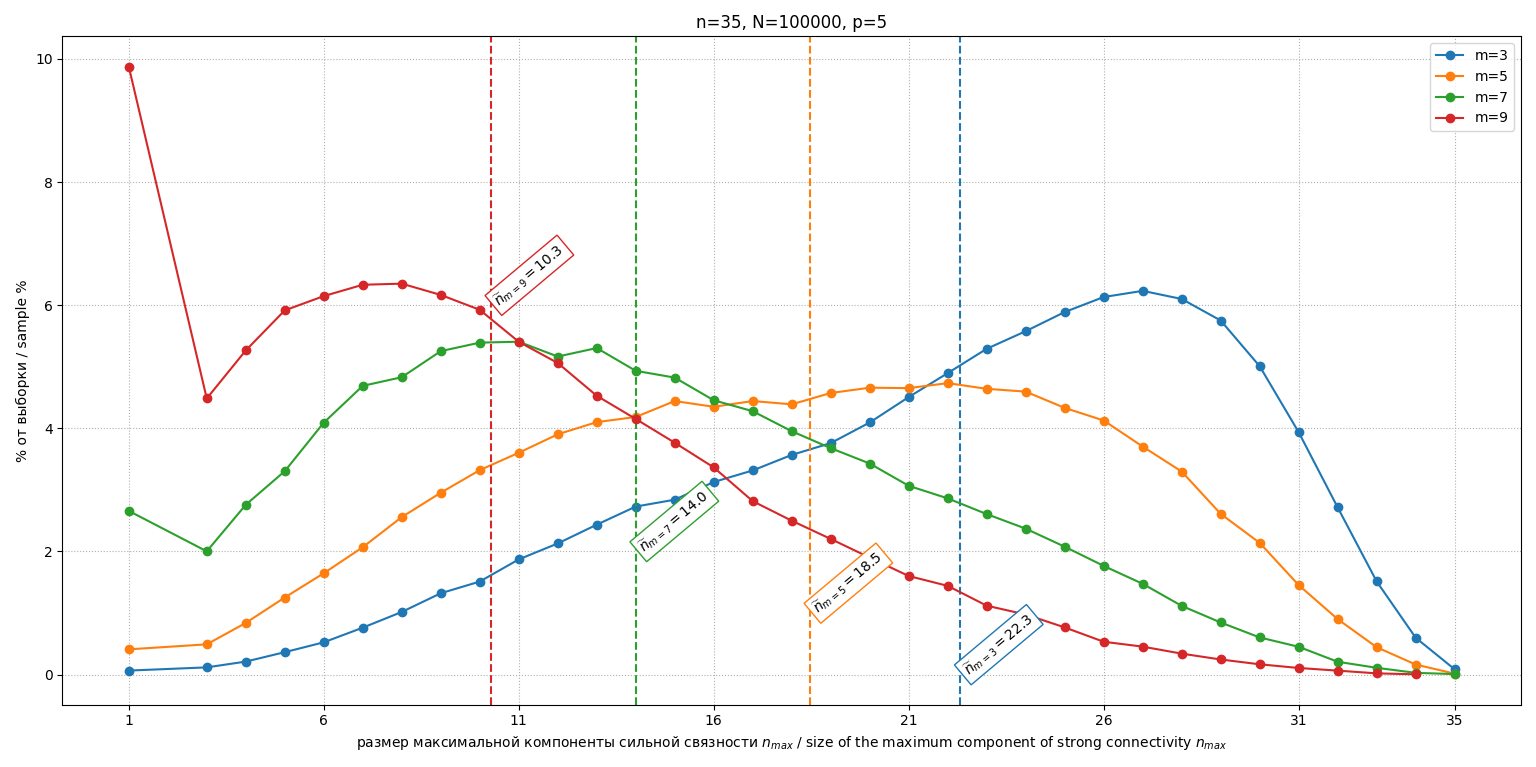
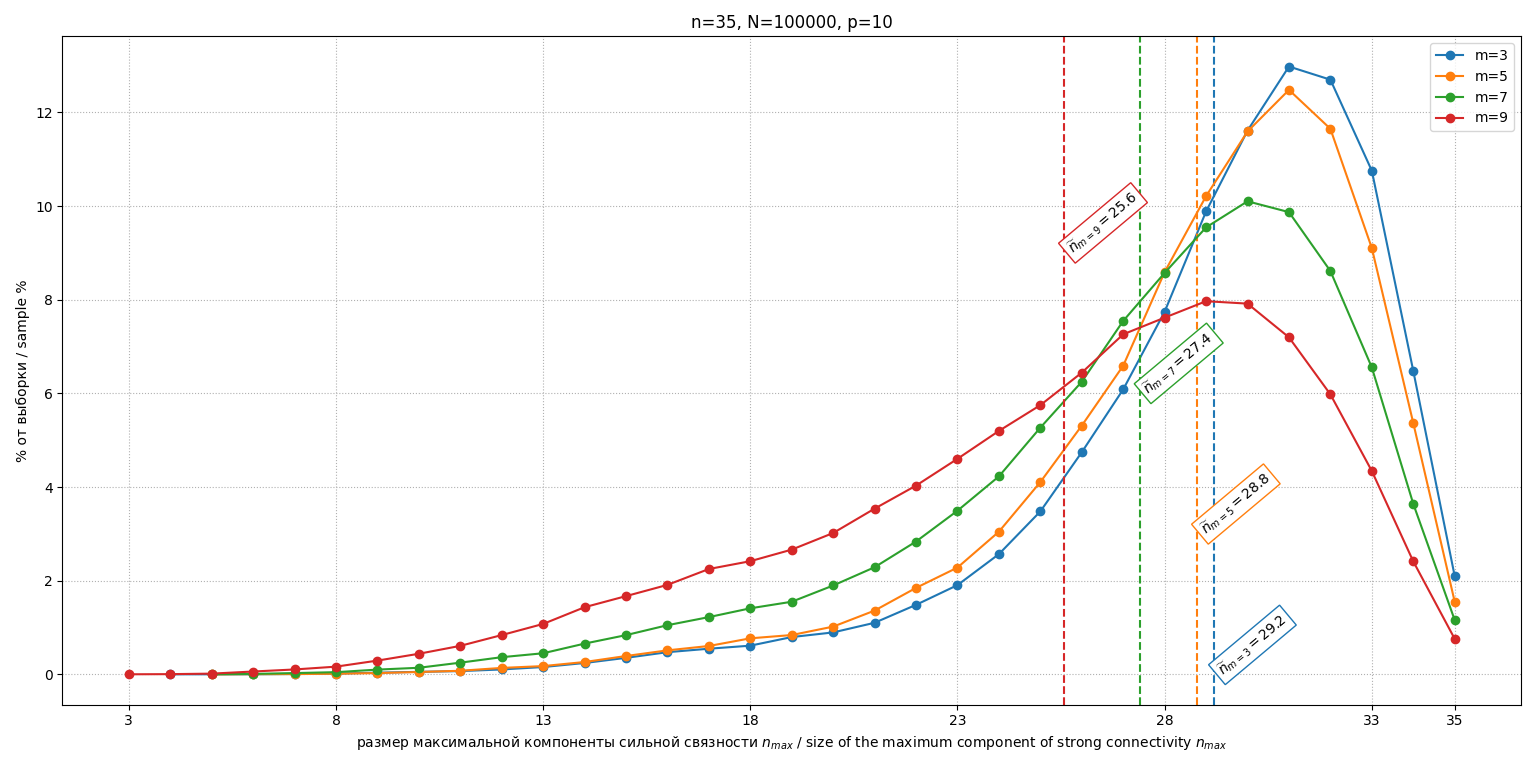
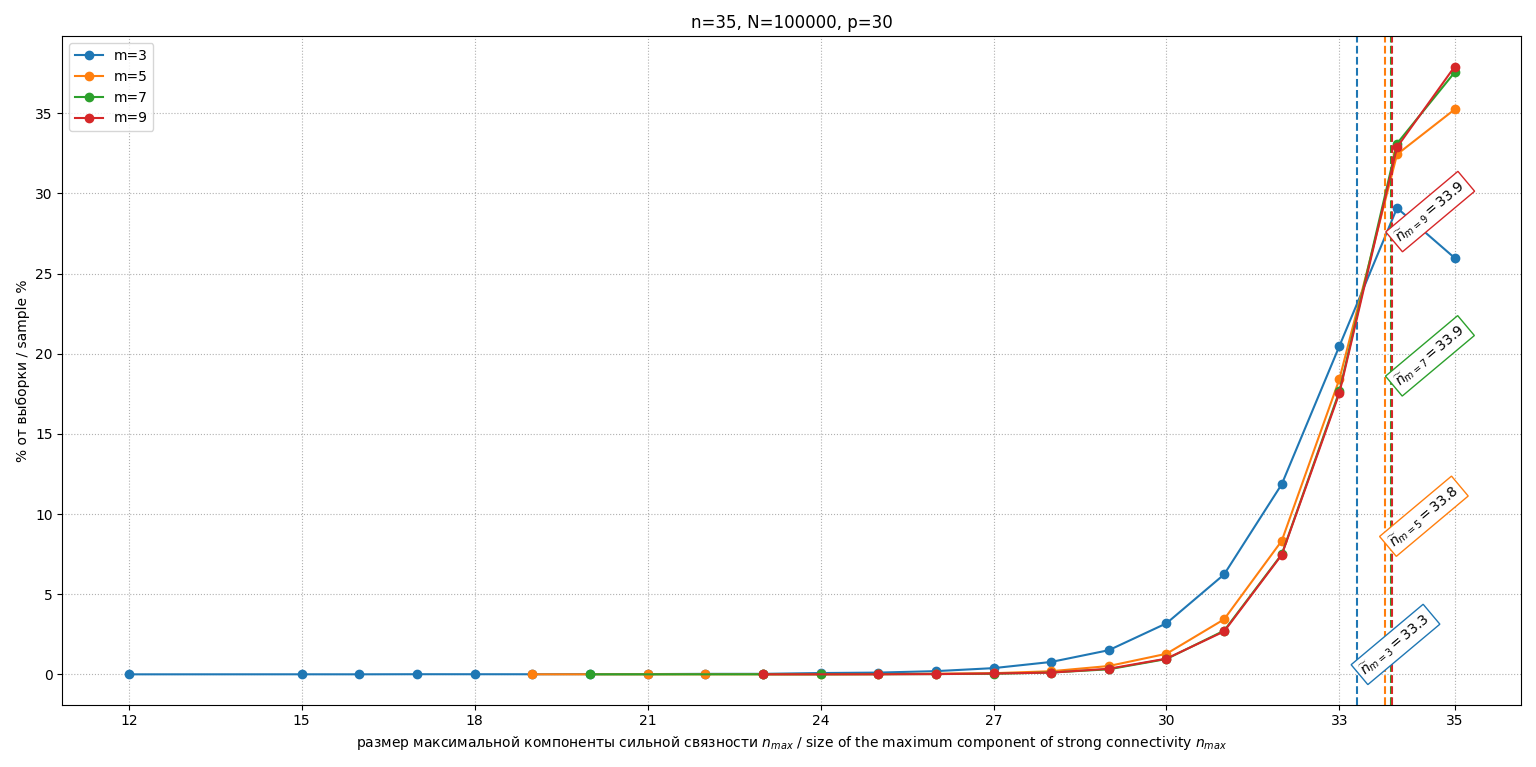
Исследовалось влияние параметра согласованности (число переставленных пар). Для и проведено по испытаний. Гистограммы распределений для фиксированных при изображены на рис. 2, при на рис. 3 и при на рис. 4.
Рис. 2. Гистограммы распределений М2 при
Fig. 2. Histograms of distributions of the M2 at
Рис. 3. Гистограммы распределений М2 при
Fig. 3. Histograms of distributions of the M2 at
Рис. 4. Гистограммы распределений М2 при
Fig. 4. Histograms of distributions of the M2 at
Были посчитаны среднеожидаемые размеры максимальных компонент по p для разных фиксированных . К примеру, в табл. 2 представлены среднеожидаемые размеры максимальных КСС при .
Таблица 2 / Table 2
Среднеожидаемый размер максимальной компоненты для М2 по при
The expected average size of the maximum component for M2 depending on at
1
2
3
4
5
6
7
8
9
10
11
12
1,92
5,64
10,35
14,74
18,47
21,62
24,12
26,16
27,60
28,79
29,72
30,39
Результаты модели М3
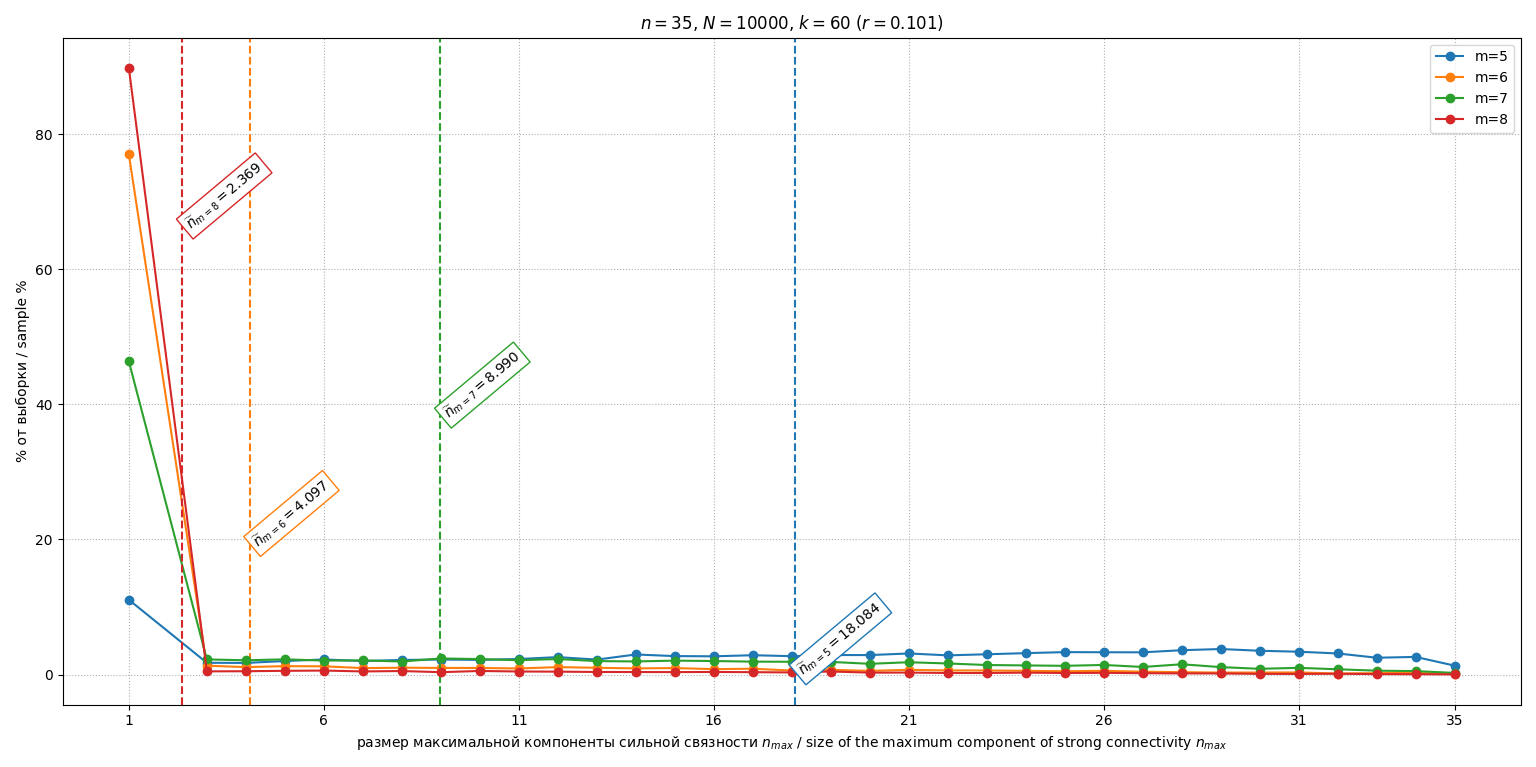
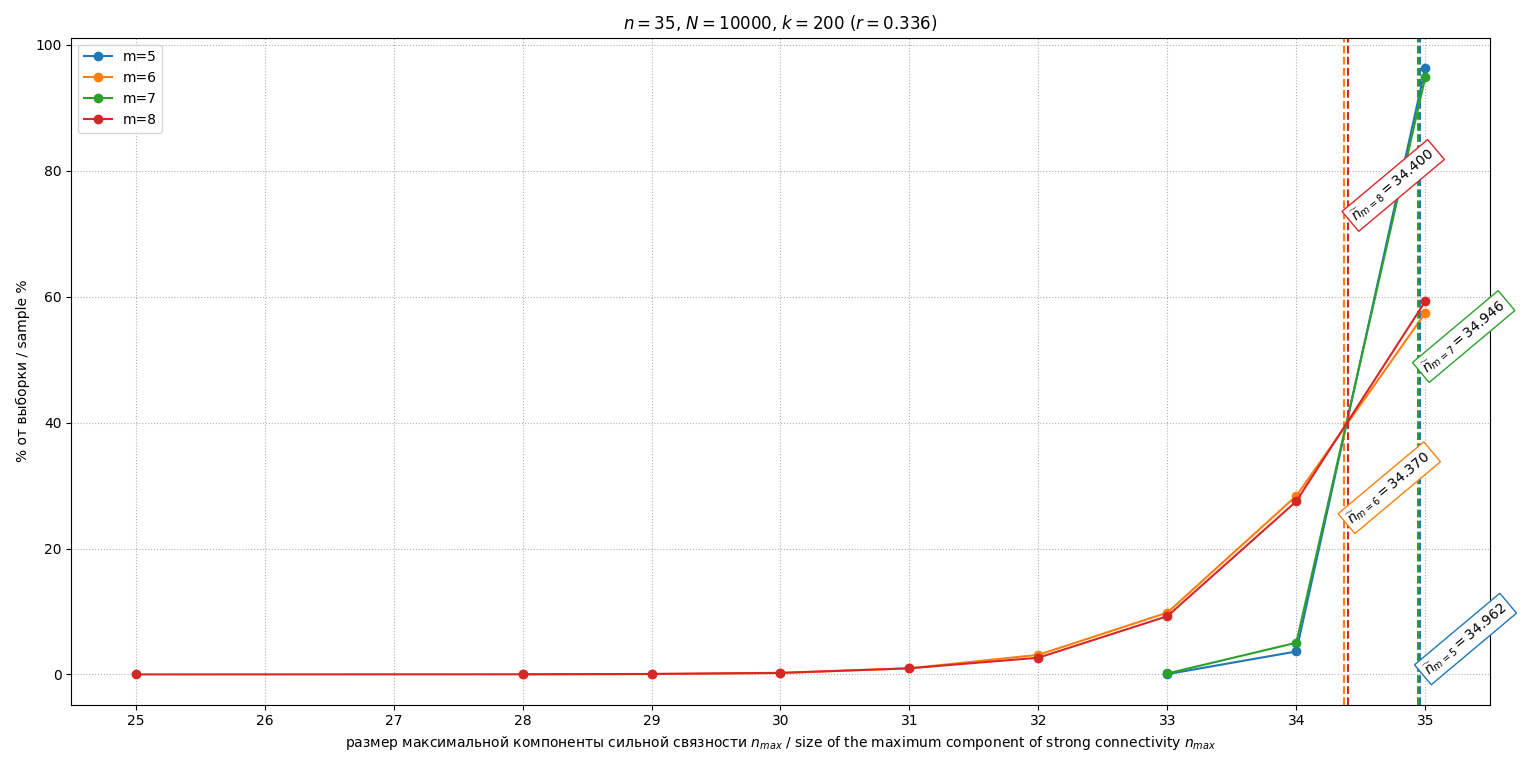
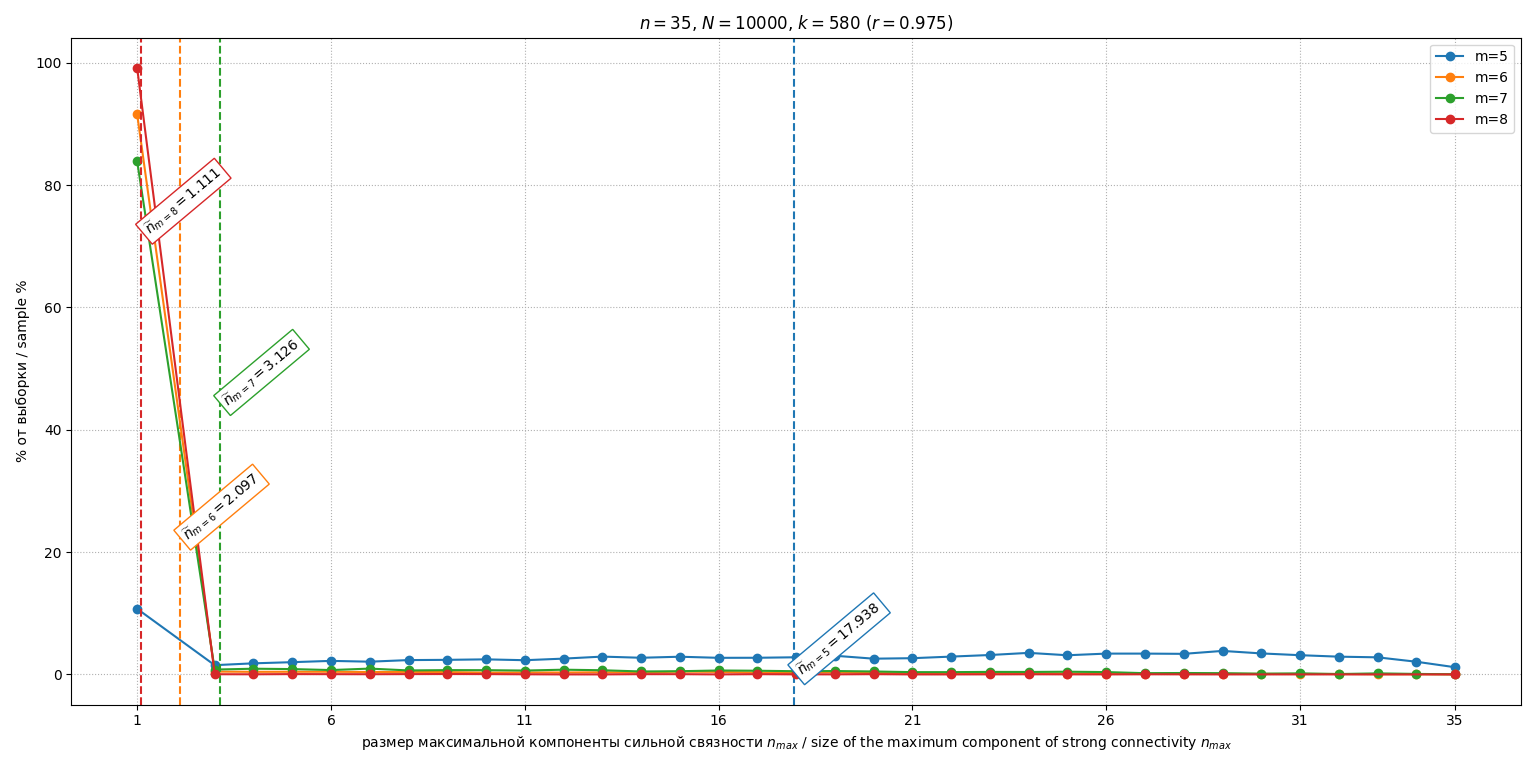
Исследовалась зависимость от смещения относительно эталона (и соответственной от степени отклонения индивидуальных мнений от единого эталона ). Для , и различных проведено по испытаний. Гистограммы распределений при , и представлены на рис. 5, 6 и 7 соответственно.
Рис. 5. Гистограммы распределений М3 при
Fig. 5. Histograms of distributions of the M3 at
Рис. 6. Гистограммы распределений М3 при
Fig. 6. Histograms of distributions of the M3 at
Рис. 7. Гистограммы распределений М3 при
Fig. 7. Histograms of distributions of the M3 at
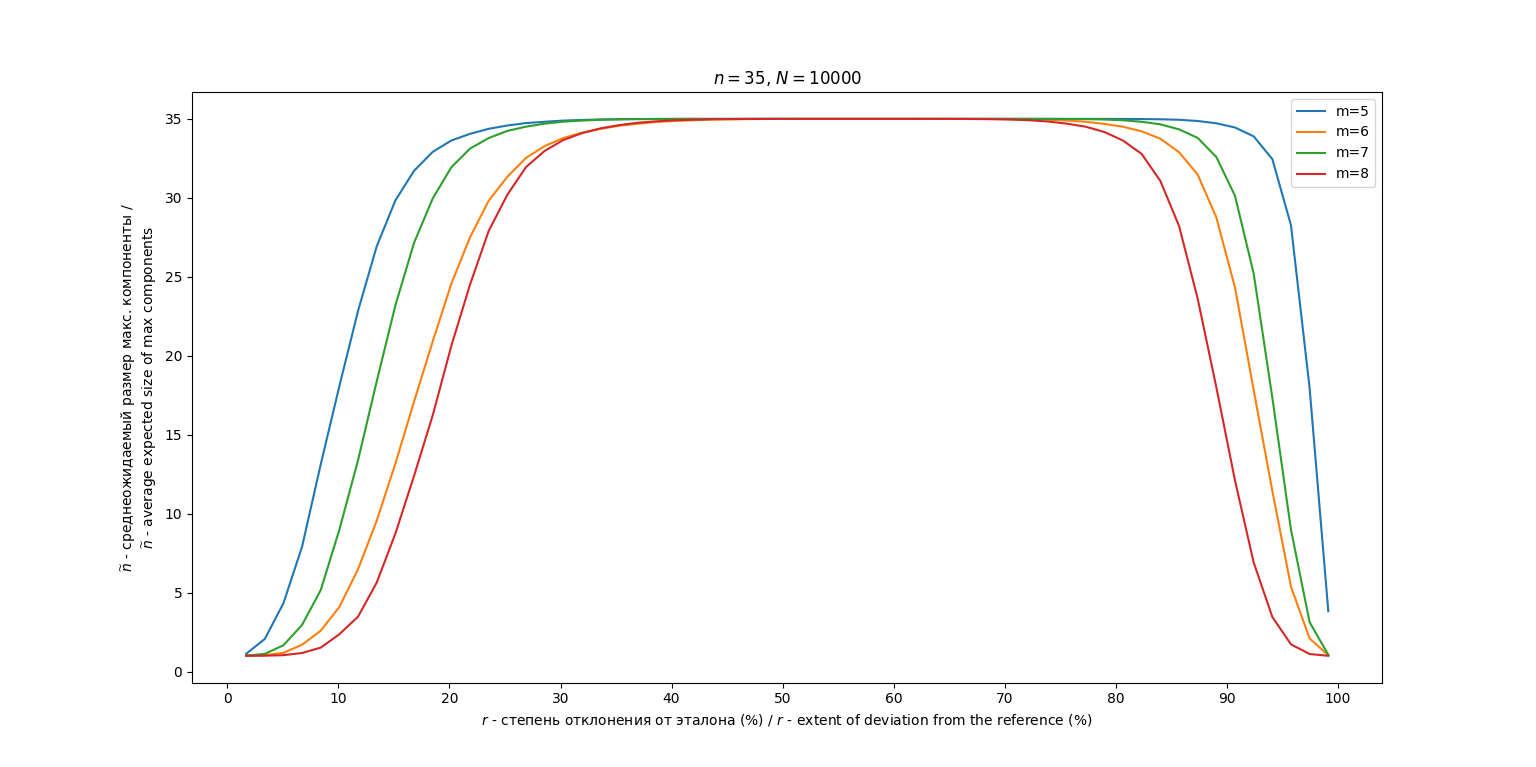
Зависимость среднеожидаемого размера максимальной компоненты от параметра для разных изображена на рис. 8. График демонстрирует немонотонную обратную U-образную зависимость: максимальные значения (минимальная эффективность декомпозиции) наблюдается в области , тогда как при (консенсус) и (поляризация) значение существенно снижается.
Рис. 8. График зависимости от степени отклонения
Fig. 8. Graph of the dependence of on the extent of deviation
Обсуждение результатов
Эксперименты показали, что эффективность декомпозиции (значение ) задачи поиска медианы Кемени слабо зависит от количества экспертов ( ), но критически обусловлена структурой мажоритарного графа, которая, в свою очередь, определяется характером профиля предпочтений. Наблюдаемая зависимость перекликается с результатами параметризованного анализа задачи (De et al., 2024), где разброс мнений рассматривается как один из ключевых параметров, определяющих вычислительную сложность.
Интерпретация результатов по моделям
Высокие значения (близкие к ) на модели M1 (независимые случайные порядки) подтверждают, что: при отсутствии какой-либо согласованности мажоритарный граф с высокой вероятностью является почти сильно связным. Небольшое уменьшение относительно объясняется вероятностным возникновением малых изолированных контуров. Практический вывод: для профилей, подобных случайным, метод декомпозиции не дает значимого снижения вычислительной сложности.
Модель M2 продемонстрировала, что введение структурной схожести мнений (через перестановку пар в едином эталоне) значительно увеличивает эффективность метода. Чем выше эта схожесть (меньше ), тем меньше размер максимальной компоненты. Увеличение ведет к приближению профиля к случайному (М1). Важно, что даже при умеренных p (например, ) средний размер максимальной компоненты ( ) существенно меньше , что указывает на значительный потенциал метода для реальных задач, где мнения экспертов обычно не являются совершенно независимыми, а группируются вокруг некоторых общих тенденций. При увеличении модель ведет себя похоже на М1 (полностью случайные перестановки), что видно при сравнении рис. 1 (М1) с рис. 4 (М2 при ). Однако разброс среднего попарного расстояния (величины обратной согласованности группы) в такой модели велика, поэтому была смоделирована модель М3.
Ключевой результат получен на модели M3. Наблюдаемая обратная U-образная зависимость от степени отклонения от эталона ( сначала увеличивается с увеличением , достигает максимума , затем уменьшается) находит объяснение при анализе внутренней когерентности группы. Параметр служит удобным инструментом для генерации профилей с разным уровнем ожидаемой когерентности, измеряемой как величина обратная среднему попарному расстоянию Хемминга между экспертами:
При (консенсус) и (поляризация) ожидаемая когерентность группы высока, что приводит к ациклической или хорошо структурированной форме мажоритарного графа и, как следствие, к его эффективной декомпозиции.
В зоне внутренние разногласия в группе максимальны (ожидаемая когерентность минимальна), мажоритарный граф близок к случайному турниру, что делает декомпозицию практически невозможной.
Таким образом, метод декомпозиции наиболее эффективен не просто при малом отклонении от гипотетического центра, а именно в условиях высокой внутренней согласованности группы, будь то консенсус или поляризация.
Практическая значимость и рекомендации
Практическая ценность метода заключается в том, что быстрый анализ КСС мажоритарного графа ( ) позволяет априорно оценить сложность исходной NP-трудной задачи по значению и принять обоснованное решение о выборе алгоритма (точный или эвристический).
Полученные результаты трансформируют метод декомпозиции из теоретического приема в ценный диагностический инструмент. Процедура построения КСС мажоритарного графа имеет сложность и может выполняться до запуска ресурсоемкого алгоритма поиска медианы Кемени.
Малое ( ) сигнализирует о высокой когерентности группы. Рекомендуется применение точного алгоритма к независимым компонентам, что гарантирует нахождение оптимального решения.
Большое (близкое к ) указывает на состояние низкую согласованность группы. Это служит основанием для отказа от точных методов в пользу эвристических алгоритмов, либо для пересмотра самого состава группы или процедуры сбора мнений.
Заключение
Экспериментально подтверждено, что метод декомпозиции задачи нахождения медианы Кемени на основе анализа мажоритарного графа обладает значительным потенциалом для значительного снижения вычислительной сложности.
Установлено, что эффективность декомпозиции напрямую коррелирует с уровнем внутренней согласованности (когерентности) группы экспертов, измеряемой через среднее попарное расстояние. Метод наиболее полезен для сильно согласованных (как при консенсусе с эталоном, так и при поляризации от эталона) и малоэффективен для групп с максимально разнородными мнениями, что объясняет наблюдаемую U-образную зависимость от степени отклонения относительно эталона .
Быстрый анализ компонент сильной связности мажоритарного графа служит не только методом ускорения вычислений, но и ценным диагностическим инструментом. Он позволяет априорно оценить ожидаемую сложность NP-трудной задачи по размеру максимальной компоненты и проанализировать структуру разногласий в группе для обоснованного выбора алгоритма решения (точного или эвристического).
Ограничения. Следует отметить ограничения проведенного исследования. Во-первых, анализ проводился на синтетических данных, сгенерированных в рамках трех параметрических моделей, которые могут упрощать структуру реальных экспертных оценок. Во-вторых, все эксперименты выполнены для фиксированного числа альтернатив ( ); поведение системы при других требует отдельного изучения. В-третьих, использованная метрика Хемминга (расстояние Кемени) является не единственно возможной, и влияние выбора иной метрики на структуру мажоритарного графа остается открытым вопросом
Важным методологическим ограничением является рассмотрение моделей M1 и M2 только для нечетного числа экспертов . Это было сделано для исключения ситуаций равенства голосов и гарантии, что граф конденсации мажоритарного графа является линейным порядком. Однако на практике число участников может быть четным, что приведет к появлению несравнимых пар (при равенстве голосов) и может повлиять на структуру графа конденсаций (Dougherty, Heckelman, 2023). Модель M3 частично снимает это ограничение, рассматривая как четные, так и нечетные , однако ее результаты для четного случая требуют отдельного углубленного анализа, т.к. помимо нахождения медиан для каждой КСС, в случае четного количества экспертов необходимо достраивать граф конденсаций до линейного порядка, что является трудоемкой задачей.
Limitations. There are some limitations that should be noted about this study. The first one is that the analysis was done on synthesized data generated using three parametric models, which might simplify the structure of real expert assessments. The second one is that all the experiments were done for a fixed number of alternatives ( ); the behaviour of the system for other values need to be studied separately. Third, the Hamming metric (Kemeny distance) used is not the only possible one, and the effect of choosing a different metric on the structure of the majority graph remains an open question.
An important methodological limitation is that models M1 and M2 are considered only for an odd number of experts . This was done to exclude situations of tie votes and to guarantee that the condensation graph of the majority graph is a linear order. However, in practice, the number of participating experts may be even, which will lead to the appearance of incomparable pairs (in the event of a tie) and may affect the structure of the condensation graph (Dougherty, Heckelman, 2023). Model M3 partially removes this restriction by considering both even and odd , but its results for the even case requires a separate in-depth analysis, since in addition to finding medians for each SCC, in the case of an even number of experts, it is necessary to complete the condensation graph to linear order, which is a time-consuming task.
Литература
Кормен, Т., Лейзерсон, Ч., Ривест, Р., Штайн, К. (2005). Глава 22.4. Топологическая сортировка. В: И.В. Красикова (ред.). Алгоритмы: построение и анализ (с. 632—635). М.: Вильямс. URL: https://elibrary.ru/item.asp?id=19445496 (дата обращения: 13.02.2026) Cormen, T., Leiserson, C., Rivest, R., Stein, C. (2005). Chapter 22.4. Topological sorting. In: I.V. Krasikova (Ed.). Introduction to algorithms (pp. 632—635). Moscow: Williams. (In Russ). URL: https://elibrary.ru/item.asp?id=19445496 (viewed: 13.02.2026)
Корнеенко, В.П. (2018). Методы многокритериального оценивания объектов с многоуровневой структурой показателей эффективности. М.: МАКС Пресс. URL: https://www.elibrary.ru/item.asp?id=35669019 (дата обращения: 13.02.2026) Korneenko, V.P. (2018). Methods of multi-criteria evaluation of objects with a multilevel structure of performance indicators. Moscow: MAKS Press. (In Russ.). URL: https://www.elibrary.ru/item.asp?id=35669019 (viewed: 13.02.2026)
Литвак, Б.Г. (1982). Экспертная информация: методы получения и анализа. М.: Радио и связь. URL: https://www.elibrary.ru/item.asp?edn=qtwiuj (дата обращения: 13.02.2026) Litvak, B.G. (1982). Expert information: methods of obtaining and analyzing. Moscow: Radio i svyaz'. (In Russ.). URL: https://www.elibrary.ru/item.asp?edn=qtwiuj (viewed: 13.02.2026)
Нефедов, В.Н. (2022). Медиана для нечетного числа отношений линейного порядка и ее использование в задачах группового выбора. ПДМ, 57, 98— https://doi.org/10.17223/20710410/57/7 Nefedov, V.N. (2022). Median for an odd number of linear order relations and its use in group choice problems. Prikladnaya Diskretnaya Matematika, 57, 98—127. (In Russ.). https://doi.org/10.17223/20710410/57/7
Нефедов, В.Н., Осипова, В.А. (2022). Согласование индивидуальных ранжировок методом ветвей и границ. Известия РАН. Теория и системы управления, 6, 123— https://doi.org/10.31857/s0002338822060142 Nefedov, V.N., Osipova, V.A. (2022). Coordination of individual rankings by the method of branches and boundaries. Journal of Computer and Systems Sciences International, 6, 123—132. (In Russ.). https://doi.org/10.31857/s0002338822060142
Azzini, I., Munda, G. (2020). A new approach for identifying the Kemeny median ranking. European Journal of Operational Research, 2, 388-401, https://doi.org/10.1016/j.ejor.2019.08.033
Bartholdi, J., Tovey, C.A., Trick M.A. (1989). Voting schemes for which it can be difficult to tell who won the election. Social Choice and Welfare, 6(2), 157— https://doi.org/10.1007/bf00303169
Cook, W.D. (2006), Distance–based and Adhoc Consensus Models in Ordinal Preference Ranking. Europ. J. of Operational Research, 172, 369— https://doi.org/10.1016/j.ejor.2005.03.048
De, K., Mittal, H., Dey, P., Misra, N. (2024). Parameterized aspects of distinct Kemeny rank aggregation. Acta Informatica, 61, 401— https://doi.org/10.1007/s00236-024-00463-x
Dougherty, K., Heckelman, J.C. (2023). When ties are possible: Weak Condorcet winners and Arrovian rationality. Mathematical Social Sciences, 123, 45— https://doi.org/10.48550/arXiv.1704.06304
Hudry, O. (2012). On the computation of median linear orders, of median complete preorders and of median weak orders, Mathematical Social Sciences, 1, 2— https://doi.org/10.1016/j.mathsocsci.2011.06.004
Sharir, M. (1981). A Strong-Connectivity Algorithm and Its Applications in Data Flow Analysis. Computers & Mathematics with Applications, 7, 67-72. https://doi.org/10.1016/0898-1221(81)90008-0
Tarjan, R.E. (1972). Depth-first search and linear graph algorithms. SIAM Journal on Computing, 1(2), 146— http://dx.doi.org/10.1137/0201010
Varol, Y.L., Rotem, D. (1981). An algorithm to generate all topological sorting arrangements. The Computer Journal, 24(1), 83— https://doi.org/10.1093/comjnl/24.1.83
Young, H.P. (1988). Condorcet’s Theory of Voting. American Political Science Review, 82, 1231— https://doi.org/10.2307/1961757
Информация об авторах
Виктор Николаевич Нефедов, кандидат физико-математических наук, доцент кафедры математической кибернетики, Московский авиационный институт (национальный исследовательский университет) (МАИ), Москва, Российская Федерация, e-mail: nefedovvn54@yandex.ru
Владислава Сергеевна Силаева, студент магистратуры, институт «Компьютерные науки и прикладная математика», Московский авиационный институт (национальный исследовательский университет) (МАИ), Москва, Российская Федерация, e-mail: vladasilaeva@yandex.ru
Вклад авторов
Все авторы приняли участие в обсуждении результатов и согласовали окончательный текст рукописи.
Конфликт интересов
Авторы заявляют об отсутствии конфликта интересов.
Метрики
Просмотров web
За все время: 115
В прошлом месяце: 20
В текущем месяце: 6
Скачиваний PDF
За все время: 48
В прошлом месяце: 19
В текущем месяце: 0
Всего
За все время: 163
В прошлом месяце: 39
В текущем месяце: 6