Введение
В настоящее время встает ряд задач обеспечения доступа исследователям и исследовательским коллективам к национальным и международным ресурсам, результатам научных исследований на территории страны. Для их решения все большую популярность приобретают технологии семантического полнотекстового поиска, базирующиеся на смысловом анализе информации (Захарова, 2009). Одним из наиболее эффективных инструментов, позволяющих проводить данную модель поиска, являются онтологии. В соответствии с концепцией Грубера, онтологией называется «явная спецификация концептуализации» (Gruber, 1995). Концептуализация — это абстрактная модель понятийного состава отрасли. Явная спецификация — это формальное, машиночитаемое представление понятийной модели отрасли. Таким образом, понятие онтологии можно представить как машиночитаемое представление упрощенной модели знания, необходимое для точного и эффективного обмена знаниями в семантической паутине той или иной отрасли.
Помимо этого, понятийная система высокотехнологичных отраслей может включать сотни тысяч классов объектов, которые участвуют в неограниченном числе отношений и ситуаций. Недостаточное использование лингвистических и онтологических знаний (формализованных представлений терминологии предметной области), используемых в приложениях информационного поиска и автоматической обработки текстов (АОТ), часто не обеспечивают требуемое качество результатов обработки и анализа содержания текстов по причине высокой трудоемкости ручной обработки текстов и создания на их основе онтологий. Существенно повысить качество интеллектуальной обработки можно только путем внедрения в технологии автоматической обработки текстов дополнительных знаний о современном техническом отраслевом языке и знаний об отраслевых технологических процессах.
Для решения этих проблем необходимо получить и описать эти знания, а также зафиксировать их в специальных онтологических справочниках: глоссариях, семантических и концептуальных словарях, тезаурусах, онтологиях. Именно упомянутые справочники должны содержать описания сотен тысяч отраслевых объектов и их смысловых отношений.
Разработчики информационных систем обычно применяют современные методы обработки и анализа текстов, учитывающие как привычные лингвистические, так и нейросетевые методы обработки и анализа смыслового содержания текстов, в частности, бурно развивающиеся большие языковые модели. Тем не менее, их внедрение добавляет ряд технических проблем, таких как эпистемическая неопределенность (EU, Epistemic Uncertainty), «галлюцинации» LLM, неоднородность терминологии, низкий уровень сопоставления онтологий. Все это также необходимо учитывать при составлении онтологий.
Классификация методов автоматизированного создания онтологий предметных областей
Одной из современных парадигм интеллектуальной обработки текстовой информации, описывающих знания о мире и предметных областях, являются онтологические справочники и формальные онтологии. Многие исследователи в этой сфере стремятся разработать сложные формальные подходы и практически аксиоматизированные теории. Однако при таком подходе автоматическая обработка неструктурированных текстов на естественном языке затруднительна ввиду их неоднозначности и неточности (Лукашевич, 2016).
В настоящее время разработано значительное число методов, подходов и технологий, решающих задачи автоматизированного формирования онтологий предметных областей. Существующие методы условно разделяются на следующие группы в зависимости от использования основного подхода:
- методы, основанные на лексико-синтаксических шаблонах;
- методы глубокого и машинного обучения, в частности на основе использования LLM;
- статистические методы;
- гибридные методы.
Методы на основе лексико-синтаксических шаблонов
Такие классические методы, основанные на правилах, предполагают использование лексико-синтаксических шаблонов, которые интегрируют лексические, синтаксические и семантические представления для автоматического извлечения релевантных слов и фраз из текста. Согласно исследованию (Sadirmekova et al., 2024), существует возможность автоматического создания LSP на основе шаблонов проектирования онтологий (ODP, Ontology Design Patterns) (Gangemi, Presutti, 2009). Анализ эффективности показывает, что методы на основе лексико-синтаксических шаблонов демонстрируют высокую результативность лишь при работе с текстами узкоспециализированных предметных областей с унифицированной терминологией, при этом обладая высоким уровнем прозрачности и не требуя обучающих выборок. Однако использование таких методов требует точечной настройки и доработки шаблонов под конкретную предметную отрасль, что включает в себя необходимость добавления специфических понятий и свойств для каждой конкретной задачи. Кроме того, методы на основе LSP показывают низкие показатели полноты при вариативности естественного языка.
Подход на основе статистических методов
Подход, базирующийся на использовании статистических методов, относится к методам статистического анализа данных на естественном языке (Хорошилов, Никитин, Будзко, 2014). Для реализации этих методов требуются большие объемы текстовой информации — репрезентативные корпуса текстов.
На первом этапе в каждой коллекции документов выделяют термины-кандидаты (как правило, существительные и именные группы), определяется их частота встречаемости. Использование частотных критериев позволяет значительно сократить число предполагаемых классов понятий.
На втором этапе проводится ранжирование терминов по частоте встречаемости и другим статистическим критериям, оценивается пересечение различных коллекций по используемым терминам.
Этап выделения отношений между классами является наиболее сложным. В рамках этого подхода предполагается, что первоначально строится не произвольная онтология, а тезаурус — таксономия с терминами. В качестве базовых отношений, действующих между терминами, определяются отношения «is-a» и «synonym-of». Для выделения отношения «is-a» обычно используют количественный подход к информации. Он позволяет выделить только базовые отношения, необходимые для построения таксономии. Однако возможно его расширение для выделения и других отношений (Хорошилов, Кан, Филиппов, 2024).
Основной недостаток такого подхода — необходимость наличия огромных массивов текстовой информации, а также выполнения требований к репрезентативности этих наборов текстов. Помимо этого, подход на основе статистических методов обладает недостаточной семантической точностью, особенно при работе с редкими терминами, а также присутствием значительного числа гиперонимов, гипонимов.
Методы машинного обучения и нейросетевые подходы
В настоящее время методы создания онтологий предметных отраслей науки на основе машинного и глубокого обучения набирают все большую популярность.
В работе (Sivaramakrishnan, Suchithra, 2019) авторами предложено применение методов интеллектуального анализа данных посредством использования сверточных нейросетей на основе семантических и тематических графов. Предлагаемый метод устраняет ограничение на поиск ключевых слов, которым обладают большинство классических подходов к рассматриваемой задаче, путем применения метода преобразования запросов. В его основе — формирование внутренней пары «запрос — значение» и последующее выведение списка предыдущих запросов пользователей, что в итоге сокращает время и затраты на вычисления и повышает производительность. Тем не менее, стоит учитывать неинтерпретируемость процесса обучения модели.
Авторами работы (Сидорова, Иванов, Овчинникова, 2025) предложено использование нейросетевых моделей и больших языковых моделей для извлечения из текстов терминов и семантических связей между ними. В данной работе представлены динамически формирующиеся инструкции для LLM на основе результатов предыдущих этапов анализа. Общая схема принципа работы LLM представлена на рис. 1. Результаты экспериментов показали хорошие значения F1-меры для задач извлечения терминов и связей между ними.
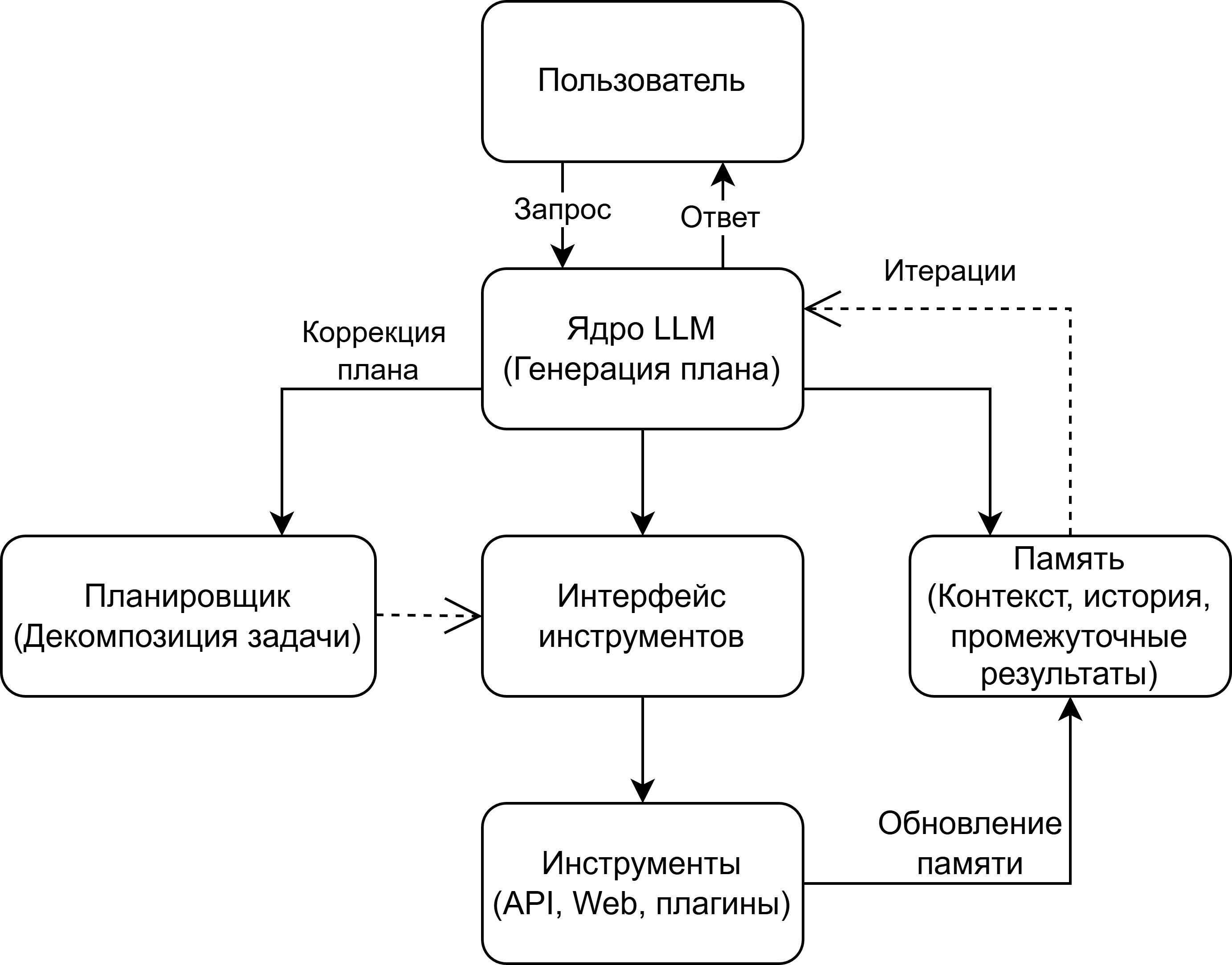
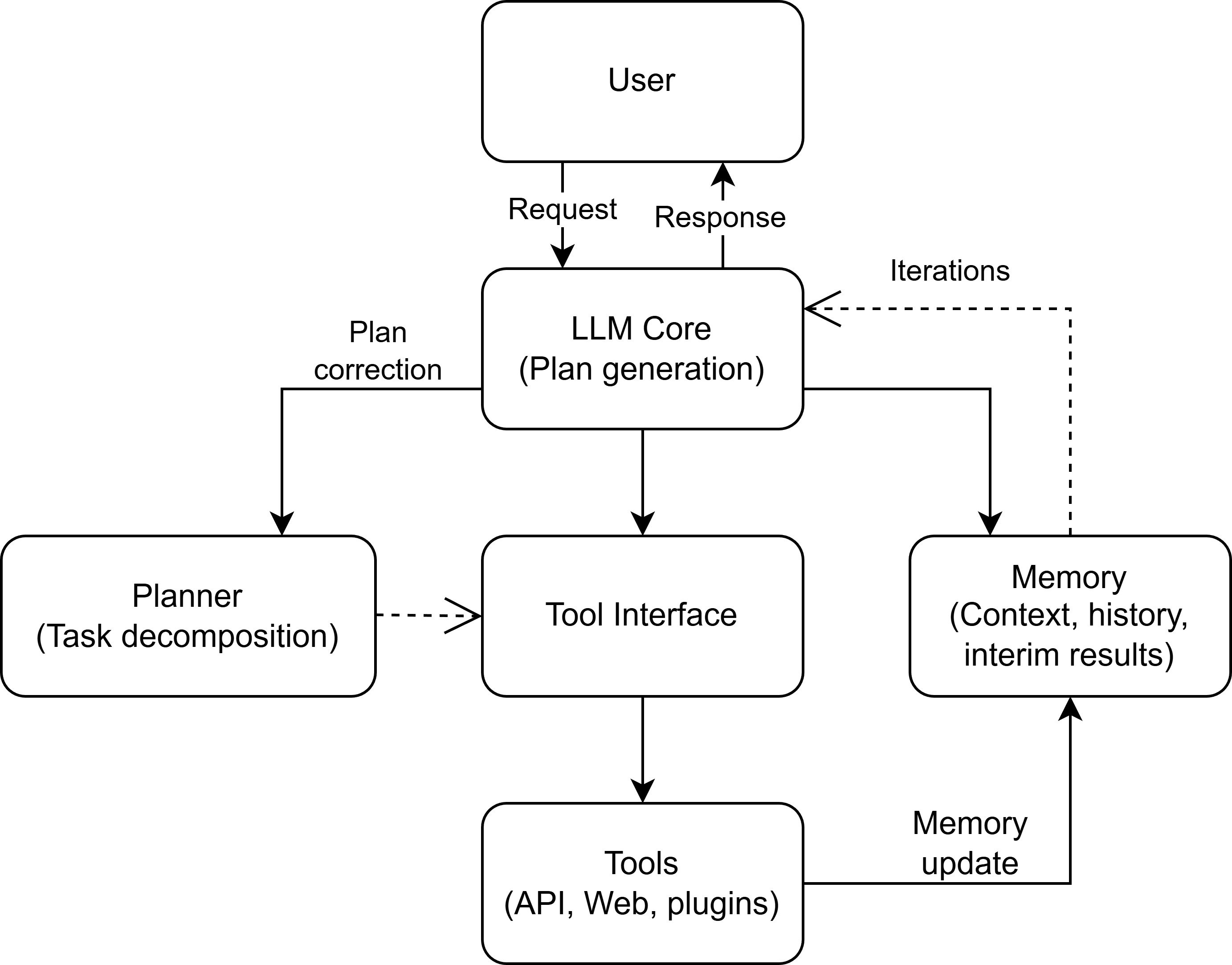
Однако при использовании методов и моделей искусственного интеллекта необходимо учитывать проблему неоднородности создаваемых онтологий, а также высокую вероятность проявления «галлюцинаций» у LLM. В целях снижения данных показателей необходимо подготавливать целостные онтологии, которые обладают внутренним единством, логической связностью и достаточной полнотой для последующей передачи данных нейросетевой модели. Далее будут рассмотрены алгоритмы, используемые для решения указанных проблем.
Гибридные методы
Современные исследования в области онтологического инжиниринга демонстрируют устойчивый тренд к гибридизации различных подходов (Ghidalia, 2023).
В работе (Чуднов, 2025) рассматривается система динамического управления знаниями (СДУЗ). Она состоит из модуля извлечения знаний, основанного на дообученной модели ruBERT, и логического интерпретатора на основе Prolog.
СДУЗ позволяет решать задачи распознавание именованных сущностей (NER, Named Entity Recognition) и извлечения отношений (RE, Relation Extraction). Разработчики предложили механизм обратной связи, позволяющий обнаружить противоречия между предсказаниями нейросети и логическими правилами, проводить экспертную коррекцию и дообучать трансформер на скорректированных данных. Однако сложность настройки правил требует большего вовлечения экспертов в работу с системой.
Иной подход реализован в работе (Kukreja, 2025), где предложен end-to-end пайплайн изучения онтологий, использующий LLM (GPT-4o) для извлечения концептов и отношений в сочетании с гибридным интерпретатором принятия решений на основе multi-factor similarity score. Система включает human-in-the-loop интерфейс для валидации и обеспечивает хранение результатов в графовой базе данных Neo4j.
Для преодоления недостатков отдельных методов создания онтологий в настоящей работе предлагается гибридный подход, включающий лингвостатистические методы, метод концептуального фразеологического анализа (Хорошилов, Кан, Филиппов, 2024) и использование LLM.
Данный метод должен позволять построить замкнутый цикл автоматизированного создания онтологий на основе текстов различных предметных областей, в частности, автоматического установления родовидовых отношений между понятиями.
Алгоритм состоит из следующих этапов:
- сбор массива научно-технической документации (НТД) по интересующей тематике;
- проведение обработки текста посредством разработанного программного комплекса обработки текстов, включающего средства токенизации и морфологического анализа (МА);
- определение системы объектов в собранном массиве на основе использования семантико-синтаксического (ССА) и статистического анализа;
- проведение вторичной обработки на основе применения методов концептуального анализа (КА);
- преобразование полученных результатов в онтологическую структуру посредством генерации RDF-триплетов и импорт в редактор Protégé через OWL-интерфейс;
- дообучение нескольких LLM (в частности, моделей семейств Qwen и Deepseek) на массивах текстов и результатах предыдущих этапов. Каждая модель должна решать свою задачу в процессе:
- Модель A — токенизация и морфологический анализ;
- Модель B — статистический анализ;
- Модель C — семантико-синтаксический анализ (на основе результатов первой модели),
- Модель D — концептуальный анализа (на основе результатов модели ССА),
- Модель E — формирование онтологической модели, преобразование результатов концептуального анализа и ССА в онтологические структуры, в частности, в онтологии / тезаурусы / таксономии в виде RDF / OWL-файлов;
- проведение тестирования дообученных моделей. В качестве метрик качества использовать точность, полноту и F1-меру. В первых итерациях планируется достичь значения F1-меры не ниже 0,8 на тестовых данных.
Подробная схема алгоритма представлена на рис. 2.
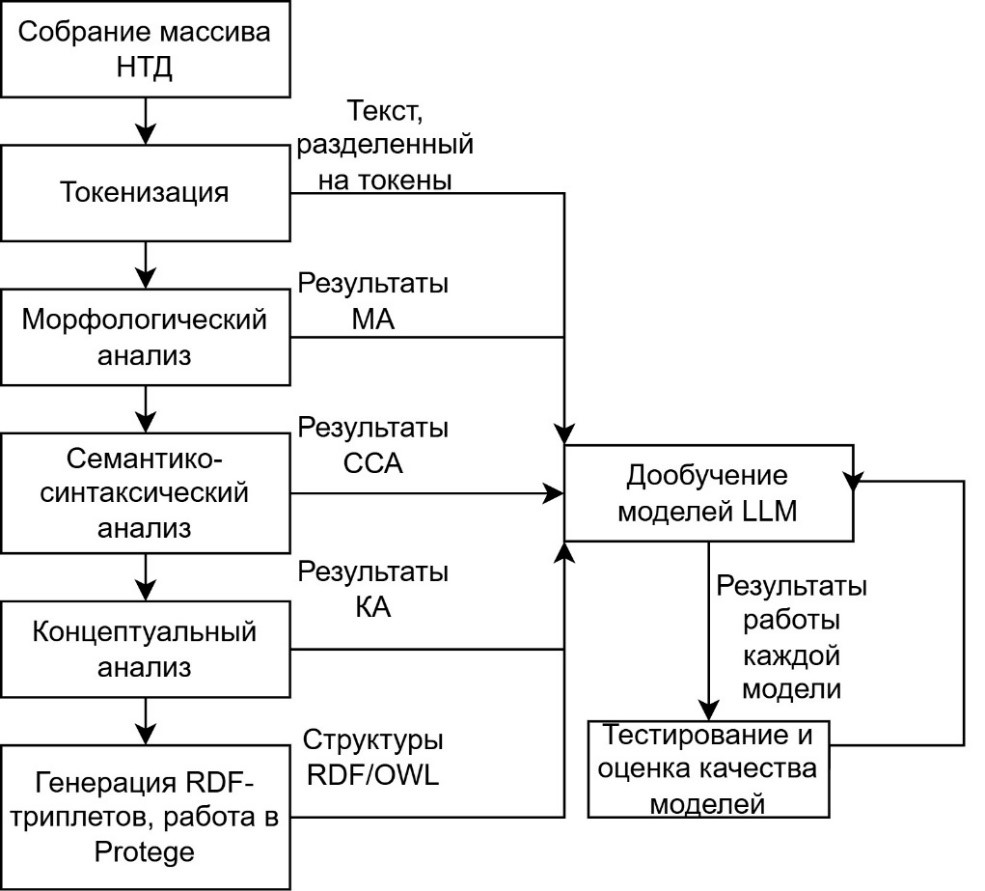
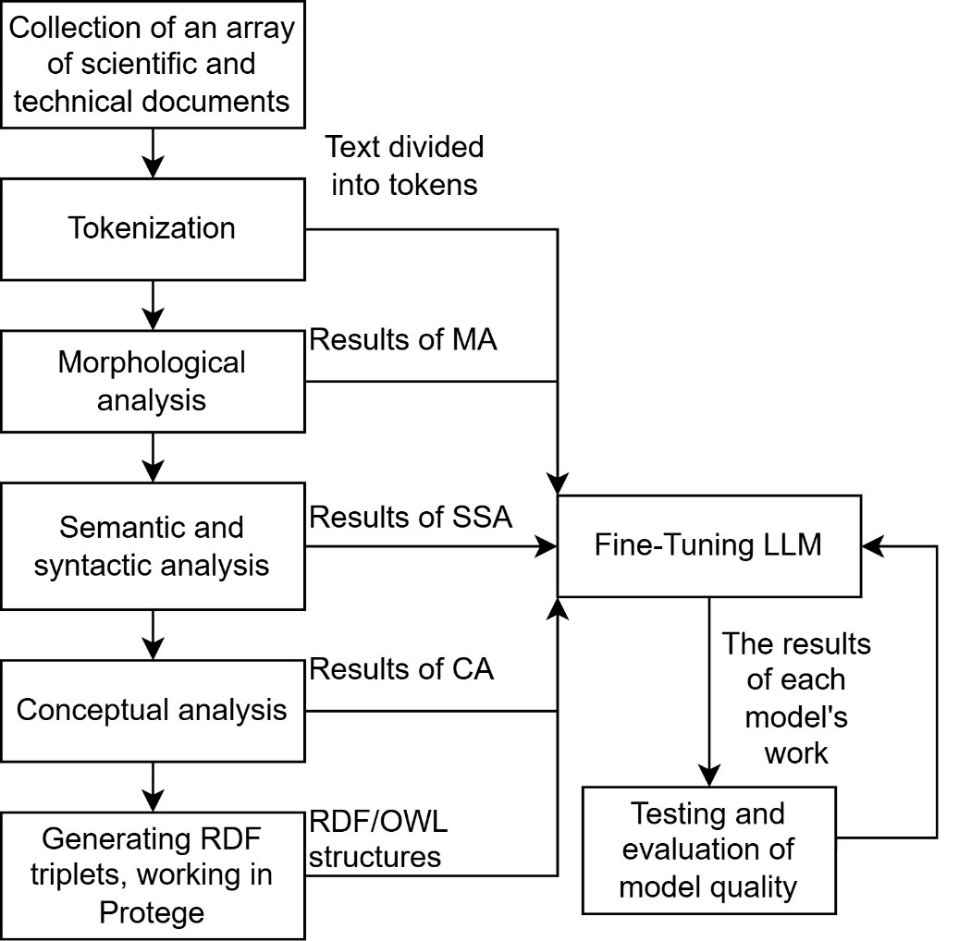
На данном этапе работы собран массив из 3000 полнотекстовых документов из открытых источников по авиационной тематике, реализована обработка текстов при помощи средств токенизации и морфологического анализа.
Классификация методов сопоставления онтологий предметных областей
В настоящее время среди основных методов сопоставления онтологий предметных областей выделяют традиционные и эволюционные методы (рис. 3).
Традиционные методы сопоставления
Традиционные методы включают ручные, формальные и статистические подходы. Первые включают лексикографическое сравнение, сравнение с учетом значений и создание «онтологий верхнего уровня» (Maedche, Staab, 2002). Применение таких методов обычно сопровождается финансовыми трудностями, однако позволяет решить задачу с относительно высокой точностью.
Формальные методы включают в себя структурный анализ (оценка сходства связей между сущностями), анализ сходства по перекрестным связям (оценка сходства через похожие классы и типы связей в онтологиях) и логический вывод (анализ свойств классов и экземпляров классов онтологий, с помощью которых из имеющихся соответствий логически выводятся другие соответствия) (Рогушина, 2017). Такой подход обладает высокой вычислительной сложностью и дает качественные результаты при работе лишь с узкоспециализированной терминологией.
Статистический подход к сопоставлению онтологий учитывает частоту встречаемости терминов в корпусах текстов и применяет меры сходства, количественно оценивая, насколько выявленные сущности подобны. Основные недостатки таких методов описаны выше.
Эволюционные алгоритмы сопоставления
Эволюционная оптимизация (мета-сопоставление) основывается на поиске оптимальных весовых коэффициентов для комбинации различных мер сходства (лексических, структурных). Однако применение эволюционных алгоритмов (ЕА) в задачах сопоставления онтологий сопряжено с рядом ограничений, среди которых преждевременная сходимость (конвергенция), приводящая к субоптимальным решениям, а также необходимость априорного задания эталонных соответствий для оценки качества найденных решений.
Для устранения данных недостатков авторами работы (Lv, Jiang, Li, 2021) предложен усовершенствованный подход к сопоставлению онтологий на основе EA, в котором для оценки качества решения представлены два приблизительных оценочных показателя — псевдовоспоминание и псевдоточность. В свою очередь, для преодоления преждевременной сходимости используется адаптивное давление отбора, которое регулируется в зависимости от стадии эволюции.
В работе (Lv, Jiang, Li, 2021) выделяют применение EA на основе входных данных без эталонного выравнивания (NRA, No Reference Alignment) и c ним (RA, Reference Alignment). Разработанный авторами алгоритм Improved EA+NRA отмечается высокой точностью обработки, но низкой производительностью по сравнению с EA+RA.
Примером применения эволюционного алгоритма можно указать работу (Кравченко Д., Кравченко Ю., Марков, 2020), где авторы для решения задач сопоставления крупных онтологий предложили в перспективу биоинспирированные алгоритмы. Гибридизация бактериального поиска и алгоритма кукушки позволила им достичь экономии времени до 13% по сравнению с традиционными методами сопоставления при обработке онтологий с 500 000 вершин.
Заключение
Проведенный анализ существующих подходов к решению задачи автоматизированного построения онтологий предметных областей науки показал, что ни один из существующих классов методов не является универсальным:
- лингвистические шаблоны требуют трудоемкой адаптации;
- статистические методы ограничены недостаточной семантической точностью;
- нейросетевые подходы имеют проблемы с нехваткой размеченных данных и «галлюцинациями».
В связи с этим, был предложен гибридный подход автоматизированного создания тематических онтологий предметных областей науки, основывающийся на интеграции лингвостатистических методов и LLM. Разработан алгоритм данного подхода, который позволяет построить замкнутый цикл автоматизированного создания онтологий.
В отличие от известных решений, алгоритм позволяет:
- применять LLM не как «черный ящик», а в связке с правилами лингвистического анализа;
- обеспечить замкнутый цикл: онтология — обучение модели — уточнение онтологии.
В дальнейшем планируется масштабирование подхода на другие области науки и интеграция с базами знаний.
Результаты работы будут внедрены в технологический процесс ВИНИТИ РАН для решения задач анализа текстов различных предметных областей.