Введение
Необходимость совместного анализа разнородных показателей, имеющих различные типы измерительных шкал (Stevens, 1946), единицы измерения и статистические распределения, является фундаментальной проблемой в современных научных исследованиях и прикладной аналитике. Несмотря на её центральность, универсального метода нормализации, который одновременно сохранял бы интерпретируемость результата и адаптировался к форме исходного распределения, до сих пор не предложено (Старовойтов, Голуб, 2021). Проблема имеет и глубокую методологическую основу, связанную с корректным сопоставлением разнотипных шкал в рамках теории измерений (Орлов, 2012).
Эта задача особенно актуальна в образовании, психологии (Аванесов, 2013; Гордеева, Сычев, Сиднева, 2021; Потанина, Моросанова, 2023), социологии и экономике, где требуется интегрировать данные из различных источников для получения целостной оценки.
Существующие классические методы нормализации, такие как линейное масштабирование в диапазон [0; 100] и z-стандартизация, обладают принципиальными ограничениями. Линейное шкалирование, сохраняя интерпретируемость, игнорирует форму распределения, что ведёт к искажениям при выбросах и асимметрии. z-стандартизация, оптимальная для нормальных распределений, теряет интерпретируемость и фиксированные границы при произвольной форме данных и не создаёт единого метрического пространства для показателей разных областей. Даже продвинутые психометрические подходы (IRT) не решают задачу интеграции агрегированных данных из разных источников (van der Linden, 2022).
Целью данной работы является разработка и представление нового метода нормализации – Адаптивной много-интервальной шкалы (Adaptive Multi-Interval Scale, AMIS), предназначенного для построения единого метрического пространства, позволяющего корректно интегрировать и анализировать разнородные данные. В статье излагается алгоритм метода, демонстрируется его практическая эффективность на примерах решения задач в образовательной аналитике и при работе с социально-экономическими показателями, а также проводится сравнительный анализ с традиционными подходами.
Адаптивная много-интервальная шкала. Метод построения
Развитие адаптивных и робастных методов нормализации, таких как алгоритмы, основанные на предварительной кластеризации (Vinagre, Vale, Pinto, 2025) или нелинейных преобразованиях (Lu et al., 2016), подтверждает актуальность поиска подходов, устойчивых к выбросам. Метод AMIS развивает эту идею, предлагая решение, которое не требует априорных допущений о распределении и адаптируется к его структуре через итеративное вычисление контрольных точек.
AMIS — метод нормализации данных, который преобразует исходные значения в унифицированную интервальную шкалу от 0 до 100. В отличие от линейного шкалирования, сопоставляющего значение с его долей в абстрактном диапазоне [min, max], AMIS определяет позицию значения относительно статистической структуры исходного распределения. Ключевой особенностью AMIS является использование иерархически вычисляемых контрольных точек, в качестве которых выступают средние арифметические значений внутри последовательно дробимых интервалов распределения. Этот принцип обеспечивает адаптивность шкалы к форме исходных данных, включая асимметрию и наличие выбросов, и лежит в основе построения единого метрического пространства.
Алгоритм построения шкалы AMIS
Алгоритм построения шкалы AMIS основан на итеративном статистическом разбиении исходного распределения данных. На каждом шаге для текущего интервала вычисляется среднее арифметическое, которое становится контрольной точкой для последующей кусочно-линейной интерполяции (Сорокин, 2021) и границей для следующего уровня разбиения. Количество используемых точек (3, 5, 9, 17) определяет уровень детализации модели, находя баланс между точностью аппроксимации формы распределения и вычислительной сложностью. Рекомендуемый выбор модели также зависит от объёма выборки (N):
-
N = 10–19: 3-точечная AMIS.
-
N = 20–49: добавляется 5-точечная модель AMIS.
-
N = 50–99: добавляется 9-точечная модель AMIS.
-
N ≥ 100: доступны все модели, включая 17-точечную.
Итеративная природа алгоритма позволяет теоретически генерировать модели с произвольным числом точек по формуле (2^n + 1), где n — целое число, определяющее глубину рекурсивного разбиения (для 3, 5, 9, 17 точек k = 1, 2, 3, 4 соответственно). Однако эмпирически установлено, что модели с 9–17 точками обеспечивают оптимальную точность для большинства прикладных задач.
Общая схема алгоритма для построения шкалы с k контрольными точками включает следующие шаги:
- Расчёт базовых статистик: Определение минимума (min), максимума (max) и глобального среднего (μ) исходного набора данных.
- Итеративное вычисление контрольных точек: Последовательное разбиение интервалов, начиная от [min, max], и расчёт средних арифметических значений в образовавшихся подинтервалах по принципу, представленному в таблице 1.
- Присвоение нормализованных значений: Каждой вычисленной контрольной точке ставится в соответствие фиксированное значение на универсальной шкале от 0 до 100, распределённое с постоянным шагом.
- Интерполяция и преобразование: Построение кусочно-линейной функции преобразования f(x) на основе полученных пар ( , ) и её применение ко всему набору данных для получения нормализованных значений.
Таблица 1 / Table 1
Принцип иерархического вычисления контрольных точек для моделей AMIS с различной детализацией
The principle of hierarchical calculation of control points for AMIS models with varying levels of detail
|
Модель |
Контрольные точки |
Описание |
|
3-точечная |
min, x₅, max |
Учёт центра (x₅) |
|
5-точечная |
min, x₃, x₅, x₇, max |
Добавление средних в нижней и верхней половинах данных |
|
9-точечная |
min, x₂, x₃, x₄, x₅, x₆, x₇, x₈, max |
Детализированное разбиение на интервалы |
|
17-точечная |
min, x₁, x₂, ..., x₁₅, x₁₆, max |
Высокая степень адаптации |
Примечание: Контрольные точки вычисляются иерархически как средние арифметические значений внутри соответствующих интервалов распределения: x₅ — среднее всего набора данных; x₃ и x₇ — средние значений в интервалах [min, x₅] и [x₅, max] соответственно; x₂, x₄, x₆, x₈ — средние в интервалах [min, x₃], [x₃, x₅], [x₅, x₇] и [x₇, max]. Для 17-точечной модели применяется дальнейшее дробление интервалов 9-точечной модели по тому же принципу.
Note: Control points are calculated hierarchically as arithmetic means of values within the corresponding distribution intervals: x₅ is the mean of the entire dataset; x₃ and x₇ are the means of values in the intervals [min, x₅] and [x₅, max], respectively; x₂, x₄, x₆, x₈ are the means in the intervals [min, x₃], [x₃, x₅], [x₅, x₇], and [x₇, max]. For the 17-point model, further subdivision of the 9-point model intervals is applied following the same principle.
Помимо классической реализации, метод AMIS поддерживает вариативные модели с задаваемыми пользователем граничными значениями. Данная возможность критически важна для предметных областей с семантически фиксированными диапазонами измерений. В образовательном контексте типичным примером является шкала учебных отметок от 2 до 5 баллов.
В качестве наглядной демонстрации принципа AMIS рассмотрим построение 5-точечной адаптивной модели для реальных данных о среднем времени выполнения домашних заданий по алгебре (в минутах) для учащихся 10-х классов. (N = 1039, где N — количество уникальных случаев преподавания «учитель-класс») (Кравцов, 2025б).
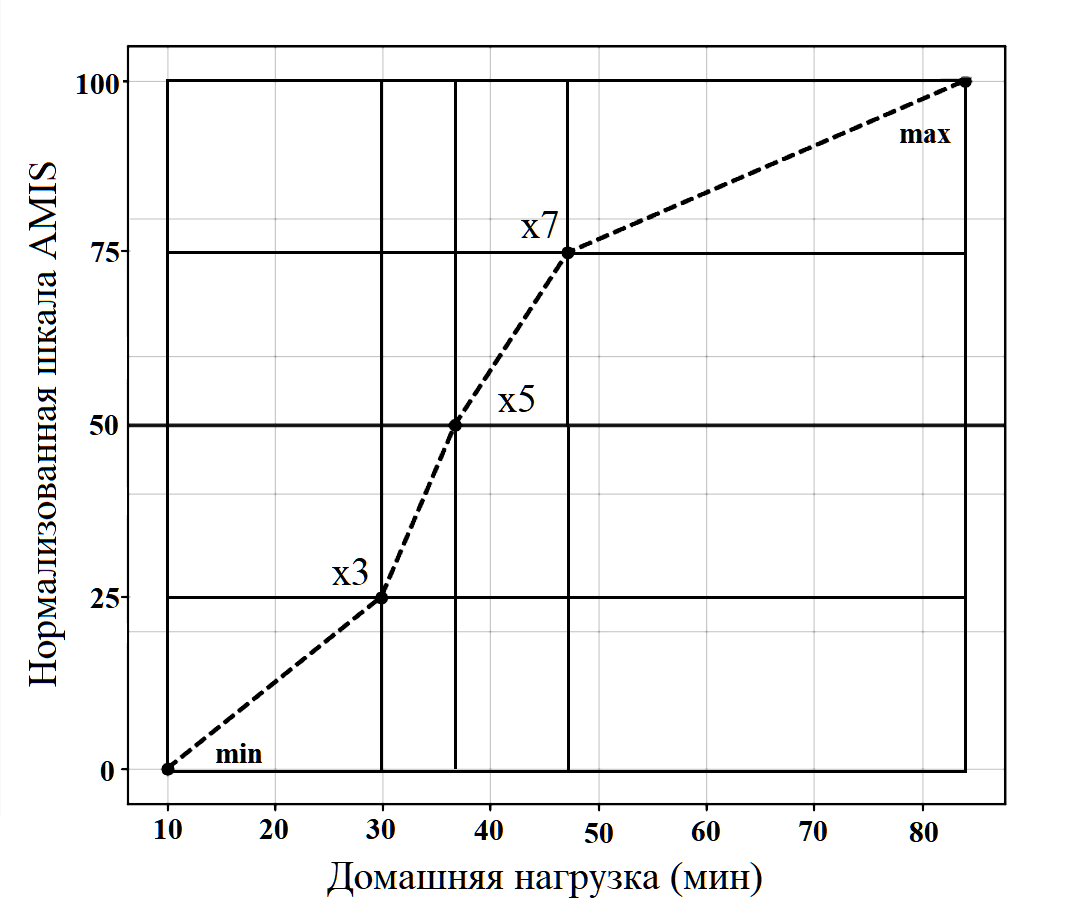
Рис.1. 5-точечная модель Адаптивной много-интервальной шкалы (AMIS)
Fig. 1. 5-point model of the Adaptive Multi-Interval Scale (AMIS)
На графике (рис. 1) вертикальные линии, проецирующие контрольные точки на ось X, наглядно демонстрируют ключевое свойство AMIS: исходные данные неравномерно распределены на исходной шкале (разные длины интервалов между min, x₃, x₅, x₇, max), тогда как на нормализованной шкале AMIS этим интервалам соответствуют строго равные отрезки по 25 баллов (0–25, 25–50, 50–75, 75–100). Это преобразование и создает интервальную шкалу внутри каждого сегмента, делая различия в баллах AMIS равнозначными с точки зрения статистического веса в распределении.
Формальное описание гибридного метода нормализации данных
Пусть задан набор исходных данных X={xi}, i=1, …, N с минимумом min(X) и максимумом max(X).
1.Определяется центральная контрольная точка — среднее значение данных:
2.Далее вычисляются промежуточные контрольные точки как средние значения по частям распределения (рис. 1):
X3=mean{xi ∣ min(X) ≤ xi ≤ x5}
X7=mean{xi ∣ x5 < xi ≤ max(X)}
Дополнительно для 9-точечной шкалы:
x2=mean{xi ∣ min(X) ≤ xi ≤x3},
x4=mean{xi ∣ x3 < xi ≤ x5}
x6=mean{xi ∣ x5 < xi ≤ x7},
x8=mean{xi ∣ x7 < xi ≤ max(X)}
Аналогично для 17-точечной модели
3.Каждой контрольной точке xk ставится в соответствие фиксированное значение yk на универсальной шкале:
Yk ∈ {0, 12.5, 25, 37.5, 50, 62.5, 75, 87.5, 100}
4.Формируется кусочно-линейная функция нормализации f:X→ по точкам (xk, yk), которая для каждого x∈X вычисляется интерполяцией между ближайшими контрольными точками:
5.Результатом является нормализованное значение f(x), которое сохраняет пропорциональность и учитывает статистическую структуру исходного распределения.
Программная реализация алгоритма AMIS
Для обеспечения проверки и практического применения алгоритма разработаны эталонные реализации на языках Python и C# в виде открытых библиотек и плагина для Excel. Исходный код и документация доступны в репозиториях проекта: AMIS Normalization Tool (Python) (https://github.com/Famimot/AMIS_Normalization_Tool) и AMIS Excel Plugin (C#) (https://github.com/Famimot/AMIS_Excel_Plugin).
Результаты
Практическое применение AMIS в образовательных исследованиях
Проблема несопоставимости разнородных метрик, таких как результаты психологических тестов, образовательные оценки и данные социологических опросов (Потанина, Моросанова, 2023), остаётся одной из наиболее актуальных в междисциплинарных исследованиях и аналитике (Tao et al., 2022), что приводит к активному использованию моделей порядковой регрессии для анализа таких данных (Bürkner, Vuorre, 2023). Как показывают данные образовательных исследований, даже в рамках одной оценочной шкалы наблюдается систематическое смещение распределений – средние значения по разным предметам существенно различаются (например, сводный средний балл 3.688 по алгебре против 4.052 по биологии). Это делает прямое сравнение и вычисление интегральных показателей методически некорректным (Кравцов, 2025а).
Результаты нормализации учебных оценок методом AMIS
На примере средних оценок, выставленных учителем в классе по истории для 11-х классов (данные по 879 уникальным случаям преподавания, N = 879) (Кравцов, 2025а) была проведена нормализация с использованием классической модели AMIS с эмпирически определяемыми границами (Рис. 2).
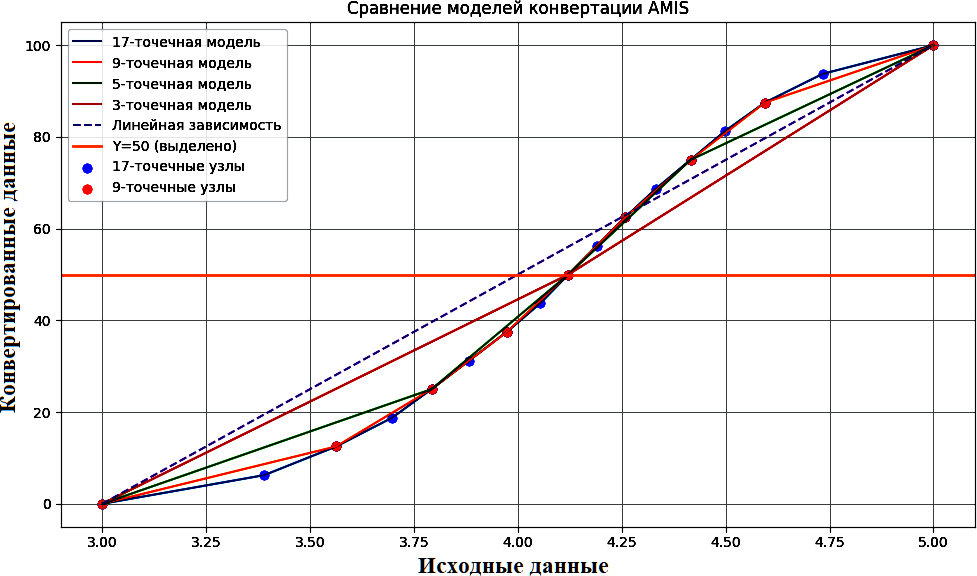
Рис. 2. Сравнение нормализации средних оценок по истории (11-й класс) методом AMIS с эмпирическими границами и линейным масштабированием
Fig. 2. Comparison of normalization of average History grades (11th grade) using the AMIS method with empirical boundaries and linear scaling
Примечание. Полный комплект материалов для воспроизведения этого и последующих рисунков (исходные данные, исходный код на Python и C#, плагин для Excel) доступен в архиве проекта Zenodo: https://doi.org/10.5281/zenodo.17588054 в разделе «Related works».
Note. The complete set of materials for reproducing this and the subsequent figures (source data, source code in Python and C#, Excel plugin) is available in the Zenodo project archive: https://doi.org/10.5281/zenodo.17588054 in the «Related works» section.
Для количественной оценки результатов, помимо визуального сравнения с линейной нормализацией, были рассчитаны ключевые метрики: энтропия распределения (H) и интегральная гладкость кривой преобразования (S) (Таблица 2).
Таблица 2/ Table 2
Сравнительный анализ моделей нормализации на примере данных по истории (11-й класс)
Comparative analysis of normalization models on the example of History subject data (11th grade)
|
Модель |
Энтропия |
Гладкость |
Узлы |
Среднее (шкала) |
|
original |
2.9625 |
- |
- |
4.1211 |
|
17_points |
3.2940 |
41217.50 |
17 |
50.00 |
|
9_points |
3.2739 |
40542.97 |
9 |
50.00 |
|
5_points |
3.1693 |
37619.89 |
5 |
50.00 |
|
3_points |
2.9914 |
28967.10 |
3 |
50.00 |
|
linear |
2.9506 |
28703.36 |
2 |
56.05 |
Анализ Таблицы 2 демонстрирует следующие ключевые результаты:
- Повышение информативности: Значение энтропии последовательно возрастает с увеличением числа контрольных точек модели AMIS (с 2.9625 для исходных данных до 3.2940 для 17-точечной модели), что свидетельствует о более равномерном и информативном распределении данных после нормализации.
- Улучшение адаптивности: Показатель гладкости (S) также монотонно увеличивается, достигая максимума для 17-точечной модели (41217.50 против 28703.36 для линейной нормировки). Это подтверждает, что адаптивные шкалы AMIS точнее следуют форме исходного распределения.
- Корректность центрирования: Для всех моделей AMIS среднее значение в нормализованной шкале стабильно равно 50.00, что соответствует центральной точке шкалы и подтверждает корректность алгоритма. В отличие от этого, линейная нормализация дает смещенное среднее (56.05), указывая на систематическую ошибку.
Для данных с классической фиксированной шкалой оценивания (например, отметки по литературе для 9-х классов, N=1379, с традиционной шкалой оценивания в диапазоне от 2 до 5 баллов) была исследована работа AMIS с жестко заданными границами. Результаты (рис. 3) подтверждают, что метод сохраняет адаптивность к распределению и внутри семантически заданного диапазона, что расширяет область его применимости.
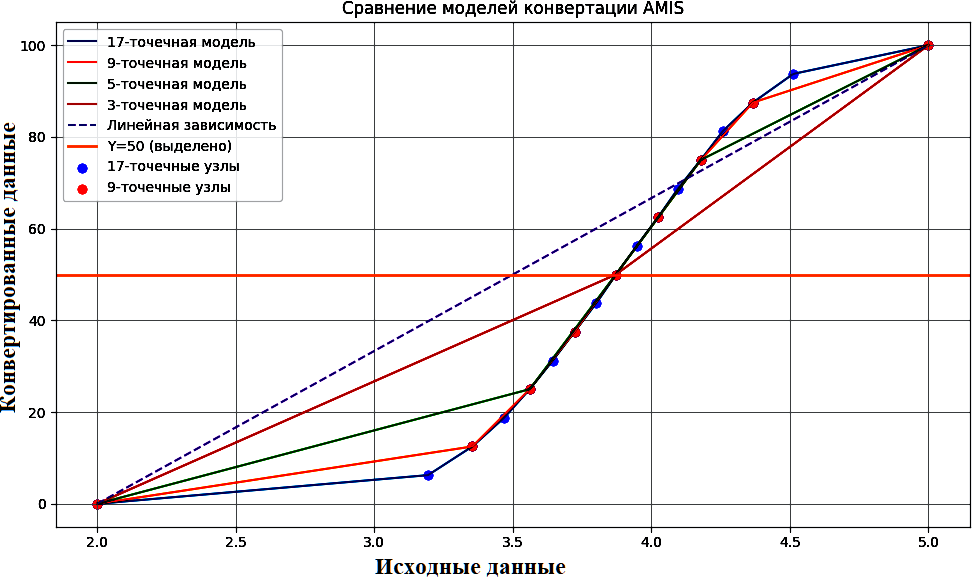
Рис. 3. Нормализация средних оценок по литературе (9-й класс) методом AMIS с фиксированным диапазоном [2, 5]
Fig. 3. Normalization of average Literature grades (9th grade) using the AMIS method with a fixed range [2, 5]
Вывод по подразделу. Практическое применение AMIS к образовательным данным позволяет устранить несопоставимость оценок по разным предметам и возрастным группам, обеспечив корректность расчета интегральных показателей. Количественные результаты (рост энтропии, стабильность среднего) подтверждают эффективность метода и его преимущество перед линейной нормализацией, делая AMIS научно обоснованным инструментом для образовательной аналитики.
Сравнительный анализ методов нормализации на примере данных о ВВП стран мира
Задача шкалирования данных с асимметричным распределением и экстремальными выбросами представляет методическую сложность и является предметом развития робастных статистических методов (Arachchige, Prendergast, Staudte, 2024), включая разработку адаптированных визуализационных инструментов, таких как модифицированные диаграммы размаха (Bruffaerts, Verardi, Vermandele, 2014; Hubert, Vandervieren, 2008). Классическим примером служит номинальный ВВП стран мира, где значения лидеров на порядки превышают медиану. Этот пример использован для сравнительного анализа, поскольку он заведомо проблематичен для стандартных методов нормализации и наглядно демонстрирует адаптивность AMIS.
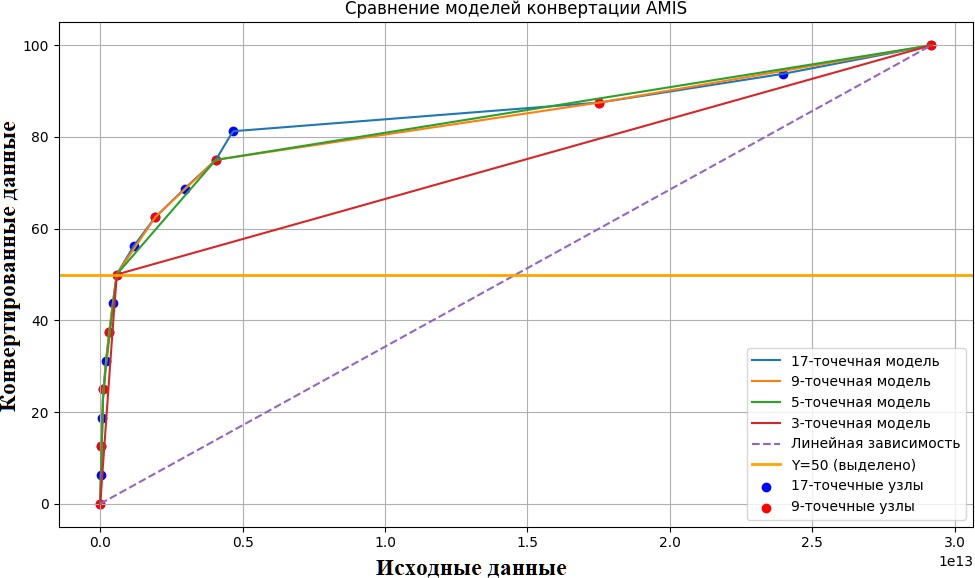
Рис. 4. Сравнение методов нормализации данных о ВВП стран мира (2024 год). На графике представлены: исходные данные, линейная нормализация, AMIS 3-, 5-, 9- и 17-точечные шкалы
Fig. 4. Comparison of normalization methods for world GDP data (2024). The graph presents: raw data, linear normalization, AMIS 3-, 5-, 9-, and 17-point scales
Таблица 3/ Table 3
Сравнительный анализ методов нормализации данных о ВВП стран мира
Comparative analysis of normalization methods for world GDP data
|
Показатель |
Оригинал |
Лин. |
AMIS 3 |
AMIS 5 |
AMIS 9 |
AMIS 17 |
|
Mean |
5.75E+11 |
1.97 |
14.91 |
20.61 |
22.53 |
22.98 |
|
Med |
4.98E+10 |
0.17 |
4.31 |
11.49 |
15.73 |
16.30 |
|
SD (σ) |
2.61E+12 |
8.95 |
19.83 |
21.52 |
20.95 |
20.84 |
|
Kurt |
90.58 |
90.58 |
1.50 |
0.67 |
0.74 |
0.82 |
|
Skw |
9.09 |
9.09 |
1.46 |
1.13 |
1.10 |
1.12 |
|
Min |
1.60E+08 |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
|
Max |
2.92E+13 |
100 |
100 |
100 |
100 |
100 |
|
N |
186 |
186 |
186 |
186 |
186 |
186 |
Примечание: для исходных данных и каждого метода нормализации приведены основные описательные статистики — среднее (Mean), медиана (Med), стандартное отклонение (SD), эксцесс (Kurt), асимметрия (Skw), минимальное (Min) и максимальное (Max) значения, а также объем выборки (N).
Note: For the raw data and each normalization method, the main descriptive statistics are provided: mean (Mean), median (Med), standard deviation (SD), kurtosis (Kurt), skewness (Skw), minimum (Min) and maximum (Max) values, as well as sample size (N).
Анализ данных (табл. 4) позволяет сделать следующие выводы.
- Стабилизация распределения и робастность. По мере увеличения детализации AMIS (3 → 17 точек) эксцесс снижается с 90.58 до ~0.8, а асимметрия — с 9.09 до ~1.2. Это указывает на эффективное и робастное преобразование исходного экспоненциального распределения, содержащего экстремальные выбросы, в близкое к нормальному, устойчивое для последующего анализа.
- Улучшение репрезентативности. Медиана последовательно возрастает от 4.31 до 16.30, приближаясь к среднему (~23), что свидетельствует о более сбалансированном распределении данных в нормализованном пространстве.
- Неадекватность стандартных методов. Линейная нормализация приводит к катастрофическому сжатию данных (Mean=1.97, Med=0.17), сохраняя экстремальные эксцесс и асимметрию (90.58 и 9.09). Z-стандартизация дает максимальное значение ≈1752σ, что делает шкалу непригодной для интерпретации.
Таким образом, только адаптивные модели AMIS обеспечивают содержательную дифференциацию объектов на всей шкале 0–100, сохраняя стабильные статистические свойства.
Обсуждение
Представленный метод AMIS вносит вклад в развитие адаптивных методов нормализации. В отличие от специализированных решений для многокритериального анализа (Vinagre, Vale, Pinto, 2025) или биомедицинских данных (Lu et al., 2016), AMIS предлагает более общий и интерпретируемый подход, опирающийся на статистическую структуру самих данных. Это делает его универсальным инструментом для решения широкого круга задач, описанных в обзорах по нормализации (Старовойтов, Голуб, 2021).
Полученные результаты демонстрируют, что AMIS обеспечивает контекстуально-зависимое измерение, учитывающее структуру распределения. В отличие от линейного шкалирования (доля в абстрактном диапазоне) или ранжирования (только порядок), AMIS определяет позицию объекта относительно статистической плотности данных, что критически важно для построения адекватных шкал в экономике, социологии и образовании, где распространены скошенные и полимодальные распределения.
Ключевые преимущества и научная новизна метода AMIS
Анализ результатов позволяет сформулировать фундаментальные преимущества метода:
- Создание единого метрического пространства для разнородных данных. Метод обеспечивает математическую корректность арифметических операций (усреднения, взвешивания) над показателями из различных предметных областей.
- Статистически обоснованная адаптивность. В отличие от линейной нормировки, AMIS не задаёт функцию априори, а итеративно вычисляет контрольные точки как средние внутри сегментов распределения, обеспечивая автоматическую адаптацию к его форме (асимметрия, выбросы).
- Сохранение интерпретируемости при обеспечении интервальности. AMIS сочетает удобство процентной шкалы (фиксированные границы 0–100) со свойствами интервальной шкалы внутри сегментов, в отличие от z-нормализации, теряющей интерпретируемость при наличии выбросов.
- Практическая эффективность. В отличие от IRT, требующей первичных ответов и сложной калибровки (van der Linden, 2022), AMIS предназначен для преобразования как исходных, так и агрегированных разнородных метрик. Это определяет его нишу в прикладной аналитике, где важны скорость, робастность и доступность результата для конечного пользователя.
Ограничения метода
Наряду с преимуществами, метод AMIS имеет определенные ограничения:
- Условная интервальность. Преобразование AMIS — кусочно-линейное, что гарантирует строгую интервальность лишь внутри сегментов между контрольными точками, а на шкале 0–100 это свойство выполняется приближённо. С ростом числа точек (и уменьшением длины сегментов) шкала асимптотически приближается к интервальной. Поэтому арифметические операции над баллами AMIS (умножение/деление значений) некорректны. Однако ключевая задача метода — построение линейных комбинаций и взвешенных индексов из разнородных показателей — решается, так как AMIS создаёт для них единое метрическое пространство, адаптированное к форме их распределений.
- Требование к интерпретации. Адаптивность AMIS требует от пользователя понимания принципа его построения, а применение нормализованных значений может нуждаться в дополнительных пояснениях или адаптации стандартных методик.
Заключение
В работе представлен новый метод нормализации данных — Адаптивная много-интервальная шкала (AMIS), решающий фундаментальную проблему совместного анализа разнородных показателей.
Основные результаты:
- Разработан метод построения единого метрического пространства путём итеративного вычисления адаптивных контрольных точек.
- Экспериментально доказана эффективность AMIS: устранение систематических ошибок при агрегации учебных оценок и робастное шкалирование данных с экстремальными выбросами (ВВП стран).
- Определена стратегическая ниша AMIS как метода, занимающего промежуточное положение между подходами: адаптивность к распределению (в отличие от линейного шкалирования), сохранение интерпретируемости (в отличие от z-стандартизации) и обеспечение интервальности внутри сегментов (в отличие от процентилей). Это делает AMIS эффективным компромиссом для задач количественной интеграции разнородных метрик.
Перспективы исследований связаны с развитием метода для потоковых данных, построением на его основе формальных математических моделей (например, учебного процесса) и внедрением в конвейеры машинного обучения для междисциплинарных исследований.
Таким образом, AMIS представляет собой методологический базис для создания единой системы измерений, а его открытая программная реализация обеспечивает доступность и воспроизводимость.
ДОСТУПНОСТЬ ДАННЫХ И КОДА (ОТКРЫТАЯ НАУКА)
Полный комплект материалов, необходимых для воспроизведения результатов данной работы, находится в открытом доступе.
Исходные данные. Деперсонализированные наборы данных (включая показатели по учебным предметам и ВВП), использованные для анализа, размещены в репозитории Harvard Dataverse: https://doi.org/10.7910/DVN/BISM0N.
Программное обеспечение:
-
исходный код алгоритма AMIS на языке Python: https://github.com/Famimot/AMIS_Normalization_Tool;
-
плагин AMIS для Excel (реализация на C#): https://github.com/Famimot/AMIS_Excel_Plugin.
Сопроводительные материалы. Препринт, обучающий видеоролик и скрипты автоматизированного анализа объединены в проекте на платформе Zenodo: https://doi.org/10.5281/zenodo.17588054 (см. Related works).
1 GDP (current US$) https://data.worldbank.org/indicator/NY.GDP.MKTP.CD (дата обращения: 0.02.2026).
2 AMIS Excel Plugin https://github.com/Famimot/AMIS_Excel_Plugin (examples/DEMO_World_GDP_2024_Static_Values.xlsx) (дата обращения: 0.02.2026).