Введение
В рамках дискуссий на общественно значимые темы в сети Интернет порождается огромное количество текстов. Возникает вопрос: каковы условия того, что они будут прочитаны людьми, а не только роботами в рамках различных поисковых алгоритмов и моделей машинного обучения? Выражение «прочитан людьми» предполагает, разумеется, не только формальное посещение страницы, но и понимание текста. Однако текст встречает человека не только своим расположением на странице и внешним видом (вопросы, которые исследуются, как правило, более всего в рамках темы “usability” (Ромич, Бороевич, 2025; Soegard, Dam, 2015), но и своим объемом, количеством букв, слов, предложений, лексикой и сложностью. Интуитивно понятно, что сложность играет важную роль, но как ее измерить? С другой стороны, сложности противостоит интерес, что мы также знаем из повседневной жизни. Сильная мотивация заставляет людей читать весьма сложные тексты, не понимать, бросать, и снова, и снова приниматься читать, пытаясь составить адекватную репрезентацию написанного. В данной статье описывается применение методики, разработанной нами в 2024 году на основе компьютерной технологии регистрации синтаксических отношений. Сама по себе данная технология является относительно новой. В настоящее время благодаря развитию компьютерной лингвистики синтаксические отношения могут быть выделены автоматически в соответствии с международной системой, являющейся универсальной для множества языков, в том числе и для русского. Соответствие установлено в рамках проекта СинТагРус, разрабатываемого с 1998 года в ИППИ РАН, при участии ИРЯ РАН. Всего выделяется 49 синтаксических отношений (далее СинтО) (Савчук и др., 2024; Список, 2023). Нами их регистрация осуществляется при помощи пакета компьютерной обработки текста Natasha (https://github.com/natasha/slovnet) в экосистеме Python.
Явных признаков применения именно данной системы СинтО для задач психологии среди уже опубликованных статей нам обнаружить не удалось. Даже в наиболее свежей совместной работе сотрудников НЦПЗ РАМН и ИСА РАН (Девяткин и др., 2021) она еще не используется, не говоря уже о более ранних (Ениколопов и др., 2019 а, б, в, г).
Также не обнаружили мы признаков ее применения в таких научно-прикладных областях, как общая дидактика (Вахрушева и др., 2021) и обучение иностранным языкам (Виноградова и др., 2021; Лапошина, 2023), в которых задача определения сложности и удобочитаемости текстов имеет первостепенную важность. Пока, похоже, не применяется она и в области юриспруденции, где формулировки законов могут быть чрезвычайно громоздкими (Кнутов, Чаплинский, Алимпеев, 2022; Кнутов и др., 2021).
Подходы к анализу сложности текстов развиваются сейчас и в других странах (см. обзоры в Liu, Lee, 2023; Pan et al., 2024). Однако судить о том, какие конкретно показатели лингвистической статистики применяются на различных компьютерных ресурсах, по изложению в статьях зачастую затруднительно. Дело в том, что таких показателей может быть от нескольких десятков до нескольких сотен и взаимосогласование их происходит в ходе обучения нейронных сетей. При этом различные показатели работы нейросетей зачастую соотносятся между собой даже без экспериментов с участием людей.
Конечно, оценка сложности текстов в столь различных задачах, как интернет-коммуникация, чтение учебных текстов и разработка законов, имеет значительные отличия. Лица, участвующие в общественных обсуждениях, как правило, являются носителями языка, хотя и с сильно различающимися языковыми способностями. При этом они находятся в поиске релевантной информации, отвечающей их внутренним запросам. Соответственно, можно выделить два граничных уровня сложности текстов: 1) уровень «сканирования» в ходе интернет-серфинга для оценки релевантности встречаемых текстов; 2) уровень отвержения, запретительный уровень сложности, при котором дальнейшее чтение невозможно, даже при условии релевантности информации. Конечно, эти уровни постоянно колеблются, зависят как от множества индивидуальных различий, так и от состояния субъекта, но, тем не менее, они есть и могут быть оценены с помощью разнообразной статистики текста, в первую очередь синтаксических отношений.
Предварительно получить представление о границах этих значений и величине их вариации можно при помощи субъективных оценок испытуемыми специально созданных экспериментальных текстов. Фактор интереса к текстам является первостепенным, направляющим усилия читающего, — соответственно, он не может быть проигнорирован при исследовании интернет-коммуникаций и должен быть адекватно учтен.
Цель исследования — апробировать методику оценки сложности текста субъектами в условиях, приближенных к интернет-серфингу. Жанр исследования — пилотажное.
Гипотезы исследования: 1) количество синтаксических отношений, приходящихся на одно предложение, определяет субъективную оценку сложности текста; 2) сложность текста и интерес к нему связаны негативно.
Конечно, мы понимаем, что различные СинтО имеют различный вклад в сложность понимания текста. Поэтому и выдвижение гипотезы о решающем вкладе отношения СннтО/предложение имеет технический характер. Там, где оно нарушается, и следует искать усложняющие или, наоборот, облегчающие общее понимание СинтО.
Материалы и методы
Материал исследования — тексты, опубликованные на интернет-ресурсе Яндекс.Дзен. Поскольку многое в оценке сложности зависит от лексики, а в оценке интереса — от тематики, тексты унифицировались по тематическим направлениям. Всего было четыре тематических направления — публицистика, рассказы, научный и научно-популярный тексты: 1) публицистика депутата Государственной Думы М.Г. Делягина — сложный; 2) рассказы Махила, голландца, живущего в РФ, о путешествиях по ней — простой; 3) датировка Ригведы, научно-популярный, но ближе к научному, — сложный; 4) история языка иврит — научно-популярный в чистом виде — средний.
Затем для проверки гипотезы 1 сложные тексты подверглись упрощению путем простой разбивки предложений на более короткие, а короткие — усложнению путем объединения коротких предложений в более длинные. Таким образом, сами синтаксические отношения сохранялись, изменялось лишь их количество в одном предложении. Пара стимульных отрывков одного тематического направления представляла собой либо различные фрагменты одного и того же текста, либо отрывки из двух текстов одной авторской серии. Объем текстов, около тысячи знаков, был взят, чтобы не слишком утомлять испытуемых, но все же оставить этот фактор ощутимым. Предварительная качественная классификация текстов на простые, средние и сложные была следующей: от менее 10 до 15 СинтО на предложение — простой, 15—20 — средний, более 20 — сложный.
Таблица 1 / Table 1
Статистика по стимульным текстам
Stimuli texts statistics
|
Текст |
Делягин 1 сложный |
Делягин 2 |
Делягин 1 сложный |
Делягин 2 |
Делягин 1 сложный |
Делягин 2 |
Делягин 1 сложный |
Делягин 2 |
|
Количество знаков в тексте: / N signs |
875 |
847 |
1133 |
1085 |
868 |
886 |
1036 |
1110 |
|
Количество слов в тексте: / N words |
130 |
141 |
222 |
209 |
145 |
134 |
182 |
194 |
|
Количество предложений/ N sentences |
6 |
12 |
22 |
10 |
7 |
21 |
11 |
18 |
|
Ср. длина слова (букв) / mean word lengths |
6 |
6 |
5 |
5 |
5 |
6 |
5 |
5 |
|
Ср. длина предложения (слов): / mean sentence lengths |
21 |
11 |
10 |
20 |
20 |
6 |
16 |
10 |
|
Количество СинтО: / N rels |
148 |
170 |
262 |
255 |
196 |
193 |
216 |
222 |
|
Букв на СинтО / letters/rels |
5 |
4 |
4 |
4 |
4 |
4 |
4 |
5 |
|
СинтО на слово / rels/words |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
СинтО/предл. / Rels/sentence |
24 |
14 |
11 |
25 |
28 |
9 |
19 |
12 |
|
'acl' |
5 |
2 |
2 |
0 |
1 |
0 |
12 |
1 |
|
'acl:relcl': |
2 |
0 |
0 |
3 |
2 |
1 |
1 |
9 |
|
'advcl' |
0 |
0 |
1 |
2 |
2 |
0 |
1 |
1 |
|
'advmod': |
12 |
7 |
32 |
29 |
12 |
8 |
14 |
21 |
|
'amod': |
24 |
13 |
18 |
16 |
15 |
15 |
19 |
17 |
|
'appos': |
0 |
6 |
0 |
1 |
4 |
9 |
1 |
1 |
|
'aux': |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
2 |
|
'aux:pass': |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
|
'case': |
13 |
15 |
30 |
15 |
13 |
9 |
20 |
30 |
|
'cc': |
5 |
7 |
12 |
13 |
5 |
5 |
8 |
4 |
|
'ccomp': |
2 |
7 |
17 |
10 |
4 |
0 |
0 |
0 |
|
'compound': |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
|
'conj': |
7 |
11 |
8 |
22 |
9 |
11 |
6 |
9 |
|
'cop': |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
|
'csubj': |
1 |
2 |
0 |
2 |
0 |
0 |
2 |
2 |
|
'det': |
6 |
3 |
7 |
4 |
7 |
1 |
8 |
8 |
|
'expl': |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
|
'fixed': |
1 |
0 |
4 |
2 |
0 |
0 |
2 |
2 |
|
'flat:foreign': |
0 |
0 |
0 |
0 |
2 |
4 |
0 |
0 |
|
'flat:name': |
0 |
0 |
0 |
0 |
2 |
13 |
1 |
0 |
|
'list': |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
'iobj': |
1 |
1 |
1 |
4 |
0 |
0 |
7 |
1 |
|
'mark': |
2 |
1 |
6 |
6 |
5 |
0 |
5 |
1 |
|
'nmod': |
12 |
19 |
8 |
3 |
12 |
18 |
9 |
11 |
|
'nsubj': |
8 |
10 |
27 |
22 |
16 |
14 |
19 |
14 |
|
'nsubj:pass': |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
|
'nummod': |
2 |
4 |
1 |
8 |
3 |
0 |
0 |
1 |
|
'nummod:gov' |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
|
'obj': |
7 |
4 |
5 |
16 |
2 |
1 |
14 |
6 |
|
'obl': |
10 |
12 |
22 |
13 |
7 |
8 |
16 |
30 |
|
'obl:agent': |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
'orphan': |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
'parataxis': |
3 |
5 |
6 |
5 |
8 |
11 |
7 |
7 |
|
'punct': |
23 |
36 |
49 |
53 |
54 |
63 |
39 |
39 |
|
'xcomp': |
2 |
2 |
3 |
4 |
6 |
1 |
2 |
1 |
Расшифровка СинтО содержится в Списке Синтаксических Отношений (2023).
Программный код для обработки текстов находится по адресу: https://github.com/Tim-Sa/text_diff_exp_notebook
Для проведения данного исследования был создан специальный сайт. Поскольку сайт более не поддерживается в связи с окончанием проекта, примеры текстов разной сложности даны в Приложении 2.
В целях удобства для испытуемых регистрации не производилось, тестирование было анонимным. Испытуемые не получали компенсационных выплат. Приглашение испытуемых производилось лично и через дружественные ТГ-каналы. Судя по аудитории каналов, возраст испытуемых порядка 30 ± 10 лет. Тексты предъявлялись в квазислучайном порядке.
Инструкция. Испытуемых просили оценить каждый текст по двум шкалам: 1) сложности и 2) интересу, вызываемому текстом. Оценки варьировались от 1 до 8, где 1 — наименьшая выраженность признака, а 8 — наибольшая. Шкалы предъявлялись в виде двух бегунков с демонстрацией текущего значения выраженности признаков в целых величинах.
Статистические процедуры: гипотезы и критерии
Обработка данных проводилась с помощью пакета Statisticа 6.0. Применялись методы непараметрической статистики: T-критерий Уилкоксона для оценки сдвига в результатах тестирования и критерий Фридмана (Friedman ANOVA) для соотнесения эффектов двух основных факторов интереса и сложности.
Отвержение гипотезы H0 проводилось при значениях p ≤ .05, в диапазоне значений 0,05 < p ≤ 0,09 определялись тенденции.
Результаты
Были собраны данные с 33 уникальных IP-адресов. Естественно, все результаты имеют предварительный и иллюстративный характер. Строго говоря, даже оценить полученные распределения при таком количестве наблюдений невозможно. Тем не менее, поскольку моды и медианы почти совпадают, можно предположить, что распределения близки к нормальным и, соответственно, к ним применимы базовые показатели среднего, дисперсии, стандартного отклонения и стандартной оценки.
Таблица 2 / Table 2
Субъективные оценки сложности текстов (N = 33)
Subjective evaluations of texts complexity (N = 33)
|
Текст |
Делягин 1 сл. |
Делягин 2 ср. |
Махил 1 пр. |
Махил 2 ср. |
Ригведа 1 сл. |
Ригведа 2 пр. |
Иврит 1 ср. |
Иврит 2 пр. |
|
Медианы / Medians |
2 |
4 |
1 |
2 |
4 |
3 |
3 |
3 |
|
Моды / Modes |
2 |
4 |
1 |
1 |
4 |
3 |
3 |
3 |
|
Ср. знач / Means |
2,82 |
4,09 |
1,76 |
2,32 |
3,82 |
3,15 |
3,12 |
3,21 |
|
Дисперсия / Variance |
3,76 |
3,65 |
3,11 |
3,35 |
4,78 |
2,63 |
2,80 |
3,86 |
|
Станд. откл. / Std. Dev. |
1,86 |
1,83 |
1,70 |
1,77 |
2,09 |
1,55 |
1,60 |
1,88 |
|
Станд. ошибк. / Std. Err. |
0,32 |
0,32 |
0,30 |
0,31 |
0,36 |
0,27 |
0,28 |
0,33 |
|
СинтО/предлож. / Rels/sentences |
24 |
14 |
11 |
25 |
28 |
9 |
19 |
12 |
В целом можно видеть, что тексты, имеющие меньший показатель СинтО/предложение, воспринимаются как более простые, за исключением первого, наиболее сложного текста Делягина. Весьма вероятно, такая парадоксальная реакция испытуемых спровоцирована запретительной, вызывающей негативную реакцию сложностью текста. Не исключено также, что само название «сложность» воспринимается некоторыми испытуемыми как вызов их интеллектуальным способностям и провоцирует их на искажение субъективной оценки. Видимо, в будущем следует подумать о более нейтральной формулировке.
Таблица 3 / Table 3
Субъективные оценки интереса, вызываемого текстами (N = 33)
Subjective evaluations of interest caused by the texts (N = 33)
|
Текст |
Делягин 1 сл. |
Делягин 2 ср. |
Махил 1 пр. |
Махил 2 ср. |
Ригведа 1 сл. |
Ригведа 2 пр. |
Иврит 1 ср. |
Иврит 2 пр. |
|
Медианы / Medians |
2 |
3 |
4 |
3 |
3,5 |
3 |
4 |
5 |
|
Моды / Modes |
2 |
3 |
4 |
3 |
3 |
3 |
4 |
5 |
|
Ср. знач / Means |
2,85 |
2,91 |
3,38 |
3,32 |
3,68 |
3,24 |
4,35 |
4,76 |
|
Дисперсия / Variance |
3,92 |
2,96 |
4,55 |
3,79 |
3,62 |
2,94 |
2,43 |
2,50 |
|
Станд. откл. / Std. Dev. |
1,90 |
1,65 |
2,05 |
1,86 |
1,82 |
1,64 |
1,49 |
1,51 |
|
Станд. ошибк. / Std. Err. |
0,33 |
0,29 |
0,36 |
0,32 |
0,32 |
0,29 |
0,26 |
0,26 |
|
СинтО/предлож. / Rels/sentences |
24 |
14 |
11 |
25 |
28 |
9 |
19 |
12 |
Таблица 4 / Table 4
Cложность, сравнение внутри тематических групп, Т-критерий Вилкоксона
Complexity, comparison within thematic groups, Wilcoxon T
|
|
Valid |
T |
Z |
p-level |
|
Делягин сл. & Делягин ср. |
33 |
64,0 |
2,7 |
0,008042 |
|
Махил пр. & Махил ср. |
33 |
57,5 |
2,2 |
0,025083 |
Различия между текстами о Ригведе и иврите не достигают значимости по субъективной оценке сложности.
Таблица 5 / Table 5
Сложность, сравнение между тематическими группами, Т-критерий Вилкоксона
Complexity, comparison between thematic groups, Wilcoxon T
|
|
Valid |
T |
Z |
p-level |
|
Делягин Ср. & Махил ср. |
33 |
10,0 |
4,2 |
0,000026 |
|
Делягин Ср. & Иврит ср. |
33 |
105,0 |
2,2 |
0,025642 |
Средний текст Делягина субъективно сложнее средних текстов как о Ригведе, так и об иврите.
Таблица 6 / Table 6
Сравнения текстов по вызываемому ими интересу, между тематическими блоками
Comparison of texts by the interest caused by them, between thematic blocs
|
|
Valid |
T |
Z |
p-level |
|
Делягин ср. инт & иврит ср. инт. |
33 |
58,00 |
3,15 |
0,0016 |
|
Делягин сл. инт & иврит пр. инт |
33 |
24,50 |
3,45 |
0,0006 |
|
Ригведа сл. инт & иврит ср. инт. |
33 |
95,50 |
2,03 |
0,0422 |
|
Ригведа пр. инт & иврит пр. инт |
33 |
20,00 |
3,59 |
0,0003 |
|
Махил ср. инт & иврит ср. инт. |
33 |
37,50 |
2,89 |
0,0039 |
|
Махил пр. инт & иврит пр. инт. |
33 |
92,00 |
2,89 |
0,0039 |
|
Махил ср. инт & иврит пр. инт. |
33 |
61,50 |
3,37 |
0,0007 |
По вызываемому интересу внутри тематических блоков различия незначимы, а между тематическими блоками — велики.
При этом, когда сравниваются тексты разных тематических блоков при отличающейся сложности этих текстов, уровень значимости различий возрастает. Вместе с тем, имеются исключения, по-видимому, продиктованные спецификой конкретных СинтО в текстах. Например, «Ригведа сложная» вызывает больший интерес, чем «Ригведа простая». Посмотрев на таблицу с СинтО (табл. 1), замечаем, что во втором тексте намного больше 'flat:name' (многосоставные имена) — 13 против 2. Вероятно, это и снижает интерес, при том что самих СинтО на предложение меньше. Разумеется, все эти отношения должны изучаться гораздо более подробно на различных выборках.
Таким образом, можно сделать предварительный вывод, что, хотя лексико-тематическая направленность имеет основное значение, сложность также играет немалую роль. В целом взаимоотношение сложности текста и интереса к нему — большая тема, нуждающаяся в дальнейших исследованиях.
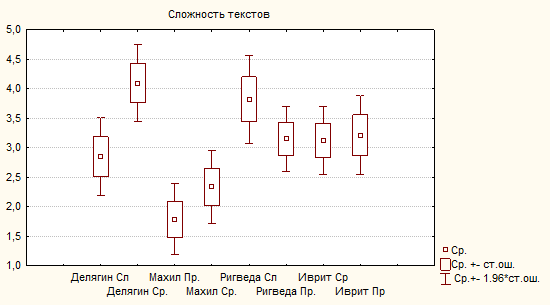
Fig. 1. Complexity of texts. Means, Means ± standard error, Means ± confidence interval (N = 33)
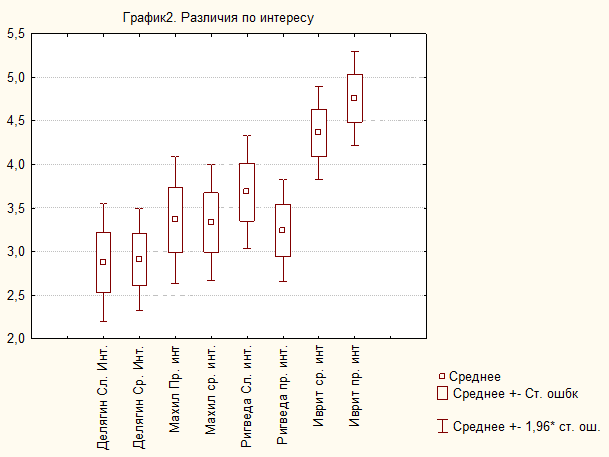
Рис. 2. Интерес, вызываемый текстами. Средние, средние ± стандартная ошибка, средние ± доверительный интервал (N = 33)
Fig. 2. Interest caused by the texts. Means, Means ± standard error, Means ± confidence interval (N = 33)
Обсуждение результатов
Предварительные оценки субъективной сложности сообщений в Интернете демонстрируют ограничения этой методики по надежности результатов. Причем дело даже не в количестве наблюдений. За дисперсией оценок может скрываться как различный уровень навыков чтения, общего и вербального интеллекта, состояния испытуемых во время чтения и оценки, так и произвольность оценок, и недобросовестность со стороны испытуемых. Ведь в целом мы даже не можем быть уверены в том, прочитал ли испытуемый текст или вопрос теста! И это общая проблема любого тестирования в Интернете и, шире, любого тестирования без применения средств психофизиологической регистрации. Вопросы регистрации движений глаз при тестировании обсуждаются в (Алмаев, Бессонова, Мурашева, 2020), а связь шкал лжи и показателей ЭЭГ — в (Алмаев, Мурашева, Петрович, 2020; Almayev, Murasheva, Petrovich, 2024). Частично решить проблему с достоверностью прочитывания текста можно при помощи задания: дать обратную связь, ответить на вопросы, указать, встречалось ли данное слово в тексте и т. п. По мере возрастания сложности все большее значение приобретает и фактор мотивации участия в эксперименте.
Тем не менее связка качеств «сложность — интерес» на материале чтения текстов потенциально может представлять значительную ценность в рамках лабораторного психофизиологического исследования. Такое исследование, включающее в себя, например, регистрацию движений глаз, кожно-гальваническую реакцию и ЭЭГ, выглядит весьма перспективным. Как меняются паттерны движений глаз при возрастающем интересе и, напротив, в случае скуки? Что происходит с различными показателями ЭЭГ, когда сложность текста преодолевает когнитивную активность чтения? Такой момент можно, например, регистрировать при помощи нажатия кнопки и отметки соответствующего события на ЭЭГ. Какие ЭЭГ и глазодвигательные паттерны соответствуют поиску когнитивных ресурсов, позволяющих вчитываться в сложный текст, как при наличии, так и при отсутствии интереса? Также чтение текстов различной сложности может выступать как модель для изучения нейрофизиологических процессов внимания, интереса и отвлечения. Можно, например, организовать отвлечения звуковыми стимулами с несколькими параметрами. Сложностью текста можно хорошо управлять на основе СинтО, подбирая и варьируя соответствующие стимулы. Интересом управлять несколько сложнее, но тоже, в общем-то, возможно, особенно в мелкосерийных лабораторных исследованиях — например, просить самих испытуемых подобрать текст на интересующую их тематику. С другой стороны, методы психологии (время реакции) и психофизиологии (негативность вызванных потенциалов, пупиллометрия, соотношения мощности в различных отведениях и проч.) могут использоваться для замера емкости когнитивных ресурсов, потребляемых СинтО, их комбинациями и структурами вложений одних СинтО в другие.
В целом, тема выглядит интересной и перспективной для психологии и психофизиологии. Возможность программного выделения СинтО позволяет разделить их на несколько больших классов, например коммуникативные и предметные, и изучать их объединения в различные кластеры по отдельности, внутри этих классов. Особо стоит отметить, что программные решения на основе Natasha относительно нетребовательны к вычислительным мощностям. СинтО — психологически осмысленный, «живой» параметр; многообразное изучение и использование его в целях психологических исследований, например индивидуальных различий, связи с мотивацией, с личностными чертами и т. п., представляется перспективным.
При этом уже сейчас, на основе самых предварительных данных, можно дать некоторую первичную рекомендацию. При прочих равных для легкости понимания текст должен характеризоваться величиной порядка 10—15 СинтО на предложение. Учитывая, что в среднем количество СинтО равно количеству слов (см. табл. 1), можно ориентироваться на соответствующее количество слов. Меньшее значение этого отношения может начать восприниматься как бессвязность, или требовать погружения в тему. Естественно, этот вопрос, в свою очередь, также нуждается в эмпирическом изучении.
Заключение
Найдена и самостоятельно освоена на основе программных средств, находящихся в свободном доступе, новая мера оценки сложности текстов, расширяющая существующие возможности в данной области. Разработана базовая методика, позволяющая учитывать тематический интерес и лексическую знакомость для испытуемых тех или иных тем в Интернете. Сложность текста находится в отношениях противоборства с интересом к нему. Хотя интерес к тексту определяется в основном интересом к теме, однако сложность текста способна снизить интерес к нему, в то время как относительная простота — повысить. Субъективные оценки могут не отличаться большой надежностью, особенно на данном этапе предварительных исследований. Тем не менее, данные методики могут развиваться и улучшаться как в онлайн-подходах, так и, особенно, с использованием лабораторных психофизиологических методов с регистрацией движений глаз и различных показателей ЭЭГ.
Ограничения. Данное исследование является пилотажным, оно ограничено как количеством наблюдений, так и контролем условий. В частности, не было проконтролировано, какие фрагменты текста испытуемые в действительности прочитали.
Limitations. This study is a pilot one and is limited by both the number of observations and the control of conditions. Specifically, it was not possible to control which text fragments the subjects actually read.