1. ВВЕДЕНИЕ
Среди факторов, которые определяют эффективность обучения человека новым навыкам в рамках рабочей группы с общими интересами, или эффективность убеждения индивидуума в некотором местном сообществе о ценности системы взглядов, предложенных для обсуждения и принятия , являются: степень подверженности индивидуума влиянию других членов группы или других групп и собственные мотивации индивидуума. Собственные мотивации здесь не рассматриваются. Социум может повлиять на них через передачу знаний, умений, навыков. Но даже при наличии этих стимулирующих мотивацию качеств, индивидуум может не иметь общих с сообществом интересов в их использовании. В этой статье мы рассмотрим первый из этих двух факторов. Возможность измерения влияния отправителя сообщения на получателя полезна для определения эффективности убеждения, обучения, психологического или морального воздействия в условиях, когда за участниками дискуссии или диалога не закреплены формальным образом роли и позиции обучающего и обучаемого. На форумах и интернете, например, участники могут иметь различный статус, в зависимости от степени успешности их активности на форуме, но это не дает им полномочий командования, а дисциплинарное соподчинение между участниками форума не признается (не допускается).
Фактической оценке подвергается две характеристики членов некоего локального сообщества, а через них и характеристики всего выбранного локального сообщества. Это:
- Степень воздействия той или иной информационной акции на локальное сообщество (можно говорить и о степени обучаемости сообщества и о возможности манипулирования групповым сознанием, то есть о позитивном и негативном воздействии на локальное сообщество близкими по характеру методами) ;
- Степень сопротивляемости индивидуумов локального сообщества (по выборочной совокупности респондентов из этого сообщества) данному информационному материалу.
Первая характеристика показывает эффективность воздействия конкретных материалов или экспертов, вторая степень индивидуализма или конформизма членов данного локального сообщества.
Подобного рода задача ставилась П.С.Краснощековым, который предложил модель коллективного поведения людей (см., например гл 11.3. в [Васин, 2008], или начальную версию [Краснощеков, 1998]). (Недавно он вернулся к теме и сделал ряд уточнений и дополнений [Makagonov, 2014]). Им описана модель принятия решения индивидуумом, который руководствуется как своим личным отношением к обсуждаемому вопросу, так и отношением к этому вопросу окружающих его субъектов. Индивидуум должен сделать выбор между двумя вариантами - принять одно из двух альтернативных решений, занять одну из двух альтернативных позиций.
По условию, влияние каждого j -го члена сообщества на i - го индивидуума не зависит от влияния других членов и определяется числом λij - вероятностью того, что i - ый индивидуум примет (будет разделять) позицию (состояние) j -го с той же вероятностью Pj, с которой это состояние испытывает воздействующий на него j -й. Для индивидуума, не имеющего своего устойчивого мнения, вероятность нового состояния, после воздействия остальных членов сообщества выражается формулой
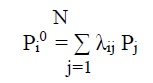 (1)
(1)
где λii =0 (то-есть, самоубеждение в этой формуле не рассматривается, так как по условию индивидуум не имеет своего устойчивого мнения), все λij неотрицательны, а их сумма равна единице:
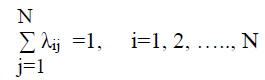 (2)
(2)
N - число членов сообщества, могущих оказывать влияние на других.

![]() (3)
(3)
Или, подробнее:
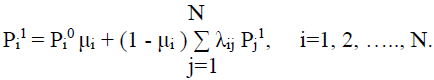 (4)
(4)
При заданных параметрах ![]() можно посчитать значения
можно посчитать значения ![]() . Однако, общего метода расчета этих параметров П.С. Краснощеков не приводит, а использует гипотетические модели, для которых параметры определяет на основе здравого смысла.
. Однако, общего метода расчета этих параметров П.С. Краснощеков не приводит, а использует гипотетические модели, для которых параметры определяет на основе здравого смысла.
Ранее в [Расторгуев] был предложен алгоритм вычисления коэффициентов ![]() для этой модели применительно к оценке меры взаимовлияния членов форума в локальной социальной сети.
для этой модели применительно к оценке меры взаимовлияния членов форума в локальной социальной сети.
Для измерения влияния, которое отдельные члены группы оказывают на других, и степени конформизма личности, мы используем семантико-логический анализ (с количественными выводами) сообщений на форуме, который содержит обсуждение проблем и инноваций.
Мы используем метод кластерного анализа, чтобы найти сходства и расхождения между членами форума и классифицировать их, выявляя, таким образом, какие из них являются активными лидерами и оказывают влияние на других.
Рассмотрим далее алгоритм и процедуру оценки влияния экспертов на респондентов из некоторой локальной социальной общности, объединённой по каким-либо признакам (территориально-средовым, образовательно-деятельностным, и т. п.), связанным с групповым сознанием (поведением).
Для оценки выбрана форма опроса-диалога, в котором респонденту предлагается высказать свое мнение по вопросу, по которому у глобального сообщества нет единого мнения. Вопросы закрытые, с заданным набором возможных ответов, или полузакрытые, с заданным диапазоном количественных оценок. Перед ответом на закрытый вопрос - «оценить мнение эксперта» - респонденту сообщается аргументация эксперта, обосновывающая это мнение. Таким образом, оценке подвергается не просто выбор эксперта, но и его обоснованность с точки зрения респондента. Значит, по оценке респондента можно оценить влияние аргументов эксперта на позицию респондента, на его собственную позицию по обсуждаемому вопросу.
2. ПОСТАНОВКА ЗАДАЧИ
Поменяем условия, примем гипотезу о том, что индивидуум с номером j должен сделать выбор не в пользу или против одного варианта (состояния А), а между тремя различными (не- пересекающимися) вариантами. Предположим теперь, что всего возможно в данном случае несколько состояний: А1, А2, ..., Ак и требуется указать вероятности P(A1,j), P(A2,j) или P(Ak,j) своих предпочтений в отношении вариантов состояния А(1, j), А (2,j) ...А(к,]).
Будем здесь рассматривать не больше трех вариантов (к=3) по двум причинам:
- Обобщение на произвольное конечное число альтернатив не представляет трудностей;
- Сведения, основанные на контент-анализе сообщений, трудно разделить на очень большое количество статистически значимых альтернатив.
В соответствии с вышеприведенными формулами в отношении этих предпочтений индивидуум имеет своё мнение с одной и той же степенью уверенности. Это соответствует оценке его характера с помощью коэффициента μi, который должен иметь одно и тоже значения μi (А1) = μi (А2) = μi (А3) для каждого варианта.
Выражение ![]() под знаком суммы в формуле (4) для каждого варианта: А1, А2, А3 имеет множителем вероятность
под знаком суммы в формуле (4) для каждого варианта: А1, А2, А3 имеет множителем вероятность ![]() . Однако, эта вероятность имеет также одно и то же значение для всех вариантов, так как зависит не от рассматриваемого варианта состояния А, а от степени влияния j -го члена сообщества на i - го индивидуума:
. Однако, эта вероятность имеет также одно и то же значение для всех вариантов, так как зависит не от рассматриваемого варианта состояния А, а от степени влияния j -го члена сообщества на i - го индивидуума: ![]() . Индивидуум с номером «i» находится под влиянием аргументов индивидуума «j» вне зависимости от того, являются ли высказывания последнего за А1, А2 или А3. Учёт долей высказываний за каждый из вариантов обеспечивается вторым множителем в этом выражении: Pj(A 1), Pj(A2), или Pj(A3).
. Индивидуум с номером «i» находится под влиянием аргументов индивидуума «j» вне зависимости от того, являются ли высказывания последнего за А1, А2 или А3. Учёт долей высказываний за каждый из вариантов обеспечивается вторым множителем в этом выражении: Pj(A 1), Pj(A2), или Pj(A3).
В случае L высказываний против одного из вариантов А1, А2 или А3, например, против А1, его учитывают как высказывание за А2 и А3, в пропорции L*Pj(A2) b L* Pj(A3).
Пусть на индивидуума воздействуют эксперты с разными мнениями по каждому из альтернативных вариантов, с различной аргументацией в пользу и против каждого варианта. Тогда эти эксперты по существу выступают конкурентами в борьбе за выбор, который предстоит сделать членам сообщества. Сами эксперты в соответствии с инструкцией или по убеждению не меняют своего мнения (р эксперта равно единице). Поэтому относящаяся к ним система уравнений, аналогичная системе (1) должна распасться на независимые между собой тройки уравнений для каждого индивидуума, при этом каждая тройка относится к одному индивидууму или к тем, которые имеют одинаковое поведение в течение всего периода наблюдений.
3. ВЫБОР ВОПРОСНИКА ДЛЯ ИССЛЕДОВАНИЯ
В качестве материала для вычислительного эксперимента был сформирован вопросник следующей структуры:
Сведения о респонденте: Пол (Х0). Возраст (Х1). Факультет (Х2). Курс (Х3). Семейное положение (Х4).
Собственно опрос по теме исследования влияния высказываний на респондента.
3.1. Выбор темы и структуры опроса
Для чистоты эксперимента вопросы не должны иметь очевидных ответов. Лучше, чтобы вопросы вообще не имели «правильных» ответов. Выбор пал на гипотетическую ситуацию, широко обсуждаемую в интернете, в том числе профессиональными психологами и ведущими тренингов (см., например [7-12]): Вы спаслись в катастрофе и у Вас есть возможность спасти только одного человека из трёх
- мать (вариант 1), супруг(а/у) (вариант 2) или - своего ребенка (вариант 3).
Первый вопрос: Кого бы спасали Вы? (указать номер варианта). Этот вопрос широко обсуждается в интернете. В действительности он интересен тем, что по ответам на него имеется некоторая статистика, различная для разных типов национальных культур, и имеется сравнительно большой набор аргументов в пользу того или иного выбора. Эти аргументы можно предъявлять респондентам, чтобы они оценивали выбор внешних экспертов с учетом мотивировки последних.
Далее респонденту последовательно сообщается статистика выбора с господствующей мотивировкой:
- в одной западной стране (Индекс обобщённого эксперта W),
- в одной восточной стране (Индекс E),
- в Российском портале ОТВЕТЫ.ру (Индекс N), и
- среди жителей юга Мексики(Индекс S).
После оглашения данных по каждой выборке в отдельности респонденту предлагается оценить по трёхбалльной шкале своё отношение (-1; 0; +1) к выбору вариантов внешними экспертами. Эти варианты представлены в таблице 1.
Таблица 1.
|
Выборка |
Вариант V1 -мать |
Вариант V2 - супруг(а) |
Вариант V3 - ребенок |
Основной мотив самого массового (более 69%) выбора в каждой строке |
|
W |
0,000 |
0,400 |
0,600 |
Нет данных |
|
E |
1,000 |
0,000 |
0,000 |
Жениться можно ещё раз, и детей народить можно ещё, а мать у меня одна |
|
N |
0,200 |
0,100 |
0,700 |
Ребёнку надо жить, а совесть не будет мучить, так как, думаю, что погибшие мой выбор одобрили бы. |
|
S |
0,000 |
0,000 |
1,000 |
Мой род должен продолжаться |
|
Средний россия нин (оценка респондентов) Prus (B1,B2,B3) |
0,090 |
0,220 |
0,690 |
(Результаты данного опроса) |
|
Априорный выбор респондентов PAcad (V1, V2,V3) |
0,250 |
0,060 |
0,690 |
(Результаты данного опроса) |
Респондентам также были заданы вопросы: какой выбор предпочитают они: V1, V2 или V3 и какой выбор, по их мнению, сделал бы средний россиянин B1,B2,B3.
Результаты обсуждаются в следующих разделах, а суммарные результаты опроса даны в двух последних строках таблицы №1.
4. ФОРМИРОВАНИЕ ВЫБОРКИ И ПЕРВИЧНЫЕ РЕЗУЛЬТАТЫ ОПРОСА
В качестве генеральной совокупности было выбрано множество студентов РАНХиГС, обучающихся на гуманитарных специальностях.
Удалось получить анкеты опроса 32 респондентов
Характеристика опрошенных: из тридцати двух опрошенных 9 человек мужского пола 23 - женского.
Для оценки представительности выборки по этому показателю требуется знать соотношение полов по всей генеральной совокупности опрошенных категорий.
Х1: Средний возраст 19,6 весь диапазон = 18-22
Таблица 2. Распределение респондентов по возрасту.
|
Возраст (количество лет) |
18 |
19 |
20 |
21 |
22 |
Примечание |
|
Количество респондентов |
5 |
13 |
8 |
3 |
3 |
Всего |
Х4: сем положение: 5 из 32 - женихи или невесты 1 замужем.
Для оценки представительности выборки по показателям Х0, Х1 и Х4 требуется знать соотношение полов по всей генеральной совокупности опрошенных категорий.
Показатели Х2, Х3 - принадлежность факультету и курсу сведены в таблицу 3:
Таблица 3.
|
ФГУ |
ИБДА |
ФЭСН |
ФЭН |
1 курс |
2 курс |
3 курс |
4 курс |
другое |
|
20 |
5 |
3 |
3 |
0 |
9 |
16 |
6 |
1 |
Х2: 20 человек из 32 - студенты ФГУ
Х3: Половина опрошенных - студенты 3-го курса.
С точки зрения распределения характеристик Х2 Х3 выборка нерепрезентативна.
Однако степень влияния этих характеристик может быть несущественной, что можно проверить методом кластеризации. А именно: если эти характеристики не влияют на выбор варианта ответа у респондента, то эти характеристики должны быть представлены равномерно в каждом кластере.
По условиям опроса каждый респондент оценивает только одно суждение каждого внешнего эксперта, поэтому для одного опрашиваемого подсчёт коэффициентов влияния Ху и pi даёт грубые простые результаты. Описанная в [Makagonov, 2014] , ранее разработанная нами методика не работает, так как там у каждого опрашиваемого фиксировалась статистика его выбора в нескольких опытах (сеансах дискуссий с тем же внешним экспертом). Статистика оценок его отношения к выбору альтернатив внешними экспертами позволяла там посчитать отношение согласий к сумме согласий и несогласий.
В нашем варианте опроса вместо одного опрашиваемого в нескольких опытах приходится взять несколько опрашиваемых в одном опыте. Эти опрашиваемые по поводу мнения одного внешнего эксперта должны быть подобны, например, принадлежать одному кластеру с общими значениями показателей. Поэтому перед статистической обработкой и подсчётом коэффициентов влияния приходится разбивать всех респондентов на кластеры. Естественным в данном случае является объединение в один кластер респондентов с одинаковым ответом на вопрос, кого бы спасали они (варианты V1, V2 , V3). (По условиям опроса они не могут разбить свои предпочтения на части).
Совместный кластерный анализ характеристик Х0-Х4 и вариантов V1, V2, V3 для 32-х респондентов показал, что главными характеристиками, влияющими на образование кластеров респондентов (без учёта оценок ими выбора внешних экспертов) явились три показателя: семейное положение, варианты выбора V3 и E3. При этом максимальное значение характеристики V3 оказалось у всех респондентов первого и второго кластеров: R1, R3, R6, R7, R9, R10, R11, R12, R13, R14, R15, R16, R17, R18, R19, R20, R23, R25, R26, R28, R29, R30 всего у 22 респондентов из 32.
5. ПОДСЧЁТ КОЭФФИЦИЕНТОВ ВЛИЯНИЯ λij И μi И ВЕРОЯТНОСТЕЙ Pi1 И Pi .
С учётом алгоритма, изложенного в [Makagonov, 2014], и в связи с переходом от одновариантного выбора (A или не А (А)) к многовариантному (в эксперименте - трёхвариантному), вычисление априорных вероятностей и коэффициентов сводится к следующим процедурам:
Вероятности состояний А1, А2 и А3 у отправителей сообщений определены заранее.
Оценки вероятности среднего априорного выбора респондентов определяются по формуле
P (Ai) = количество случаев выбора Ai / (сумма всех случаев выбора)
Оценки вероятности среднего мнения респондентов о выборе среднего россиянина подсчитываются аналогично.
Значения процентных долей, соответствующих этим оценкам вероятностей, приведены в таблице 1 в последних двух строках.
5.1. Вычисление μ



Мы выполняем эту операцию для каждого из сообщений и для всех пассивных экспертов. Затем для каждого пассивного j-ого эксперта мы получаем меру независимости мнения μ, которые мы используем в формуле (4).
![]()
Это можно сделать, только если пассивные эксперты искренни и ответственно относятся к производимому ими анализу, а не расставляют оценки случайным образом. Люди не меняют своё мнение слишком часто, поэтому μ отражает свойство характера индивидуума и эту характеристику можно использовать при измерениях в других обсуждениях с их участием.
Поэтому для расчёта μ в Excel мы используем следующий алгоритм:
- Находим во всех высказываниях их направленность «за Ai» или «против Ai».
- В строке L под строкой высказываний мы помещаем логическую характеристику в форме 1 для состояния A и -1 для состояния А.
- Мы просим участников оценки выразить своё мнение в форме «1» в случае согласия, «0» - если их мнение не сложилось, и -1 если они не согласны с идеей состояния А. Эти значения помещены в строках i=L+1,L+2,L+3,L+4);
- Если оценщик полностью поддерживает все высказывания активных экспертов (оценки совпадают) тогда оценщик является полным конформистом и его коэффициент μ следует приравнять нулю.
- Если оценщик не согласен со всеми высказываниями, тогда он имеет коэффициент р равный единице.
- Если мы сравниваем K пар оценок в строке L и в каждой из строк от L+1 до L+4 и среди них имеются расхождения, то р равно сумме всех расхождений, делённой на K (количество пар).
Расчёты, проведённые по этому алгоритму дали значения μ для трёх обобщённых оценщиков, осреднённых представителей кластеров выбравших для спасения мать (M), супруга (S ) и своего ребёнка (CH), дали следующие результаты:
![]()
В случае, если индивидуум не может участвовать в оценке, но он высказал сам свое мнение по каждому вопросу, который еще не обсуждался им с экспертами, то в этом случае можно с какой-то степенью уверенности предсказывать поведение оценщика по каждому высказыванию эксперта. Тогда можно фиксировать только отклонения от этих предсказаний, и они определят влияние активных экспертов на мнение оценщика.
5.2. Вычисление λ
Как было сказано выше, для получения статистики оценок вместо одного опрашиваемого в нескольких опытах приходится взять несколько опрашиваемых, принадлежащих одному кластеру с близкими значениями показателей.
Когда одно высказывание оценивают несколько членов одного кластера, то суммирование совпадений и несовпадений производим по всем оценкам представителей одного кластера оценщиков всех (трёх) высказываний одного активного эксперта. Итак, имеется три кластера оценщиков, в каждом из кластеров собраны оценщики, голосовавшие за одно из состояний A1, A2, или A3. Из статистики этих оценок находим λ по следующему алгоритму:



Например, для 22-х оценщиков, выбравших априорно состояние A3=Ch, выбор эксперта W (WM,WS; WCh) и результаты вычисления значений R и C приведены в таблице 4.
Таблица 4.
|
|
|
Оценка выбора W теми, кто выбрал Ch |
||
|
|
Выбор состояния экспертом W |
Осуждение (-1) |
Безразличие (0) |
Одобрение (1) |
|
WM |
0 |
8 |
7 |
7 |
|
WS |
0,4 |
9 |
2 |
11 |
|
WCH |
0,6 |
0 |
0 |
22 |
|
|
Σ |
R(M,S,Ch)=17 |
9 |
C(M,S,Ch)=40 |
Отсюда L(Ch,W)=C/(C+R)= 0,701754. Вычислив каждое ![]() и после нормирования их, получаем
и после нормирования их, получаем
![]()
Аналогично для 22 оценщиков, выбравших априорно состояние A3=Ch, выбор эксперта E (EM,ES; ECh) и вычисление значений R и C приведены в таблице 5.
Таблица 5.
|
|
|
Оценка выбора E тем, кто выбрал Ch |
||
|
|
Выбор эксперта E |
Осуждение (-1) |
Безразличие (0) |
Одобрение (1) |
|
EM |
1 |
10 |
6 |
6 |
|
ES |
0 |
11 |
6 |
5 |
|
ECH |
0 |
20 |
2 |
0 |
|
|
Σ |
R(M,S,Ch)=41 |
14 |
C(M,S,Ch)=11 |

Таблица 6.
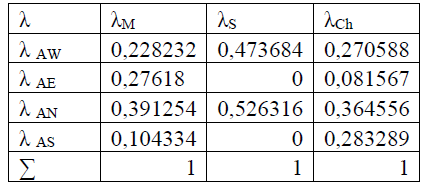

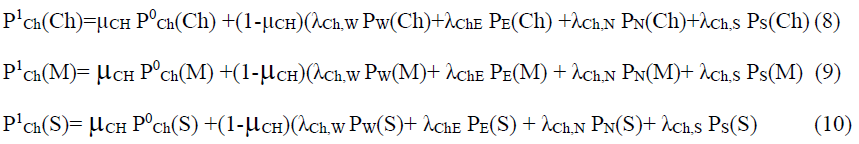
Особенностями этих трёх формул являются следующие:
- Часть априорных вероятностей выбора этих 22 оценщиков ![]() равна нулю;
равна нулю;
- Все ![]() (k=1,2,3,4) одинаковы для каждого из значений k.
(k=1,2,3,4) одинаковы для каждого из значений k.
- Эксперты по условиям проведения эксперимента не участвуют в явном виде и на них респонденты оценщики не могут оказать влияния, поэтому априорные и апостериорные вероятности выбора активных экспертов совпадают и поэтому верхний индекс опущен, а сами эти вероятности связаны соотношением
![]()
Поскольку ![]() равны нулю, а их апостериорные аналоги в большинстве своём отличны от нуля, то очевидно, что часть оценщиков в процессе ознакомления с мнениями активных экспертов переходях из своего кластера в другой. Это означает, что вероятность каждого апостериорного состояния должна быть собрана из вычислений по формулам типа (8-10) как взвешенная сумма апостериорных вероятностей для каждой группы. Например, итоговое значение апостериорной вероятности выбора состояния Ch должно быть посчитано по формуле:
равны нулю, а их апостериорные аналоги в большинстве своём отличны от нуля, то очевидно, что часть оценщиков в процессе ознакомления с мнениями активных экспертов переходях из своего кластера в другой. Это означает, что вероятность каждого апостериорного состояния должна быть собрана из вычислений по формулам типа (8-10) как взвешенная сумма апостериорных вероятностей для каждой группы. Например, итоговое значение апостериорной вероятности выбора состояния Ch должно быть посчитано по формуле:
![]()
Сумма этих финальных апостериорных вероятностей должна быть равна единице. Эти замечания отражены в нижеследующей таблице 7.
Таблица 7.
|
Априорная вероятность выбора трёх групп опрашиваемых |
В столбце: начальный выбор опрашиваемых |
Вероятность принадлежности группе №1,2, или 3 |
Апостериорная вероятность состояния тех, кто раньше выбирал Мать -S Супруга(у) - S Ребёнка - CH |
Сумма по строке Σ |
||||
|
Acad M |
Acad S |
Aca dCH |
M |
S |
CH |
|
||
|
1 |
0 |
0 |
AcadM |
0,25 |
0,700605 |
0,060484 |
0,238911 |
1 |
|
0 |
1 |
0 |
AcadS |
0,0625 |
0,032037 |
0,769336 |
0,198627 |
1 |
|
0 |
0 |
1 |
AcadCH |
0,6875 |
0,10081 |
0,094423 |
0,804768 |
1 |
Взвешенные суммы апостериорных вероятностей для каждой группы представлены в строке Pacad(a posteriori) нижеследующей таблицы 8.
Таблица 8.
|
|
P(M) |
P(S) |
P(Ch) |
Σ |
|
Pn |
0,2 |
0,1 |
0,7 |
1 |
|
Pacad(a priori) |
0,25 |
0,0625 |
0,6875 |
1 |
|
Pacad(a posteriori) |
0,24646 |
0,12812 |
0,62542 |
1 |
|
Prus |
0,09375 |
0,21875 |
0,6875 |
1 |
Рассмотренный эксперимент в пределах имеющейся выборки показывает, что информирование оценщиков о мнениях других экспертов сильно и не вполне предсказуемо влияет на мнение респондентов
6. ЗАКЛЮЧЕНИЕ
Выбор вопросника проведён с целью предъявления респондентам вопросов, не имеющих однозначного предсказуемого ответа.
В рассмотренном эксперименте помимо вычисления изменения вероятностей исходного состояния каждого оценщика, требуется подсчитывать вероятности смены состояния и пересчитывать баланс апостериорных состояний.
При последующих опросах тех же респондентов по близкой тематике можно надеяться на сохранение характера респондентов, а значит и сохранения значения р, однако пока этот момент остаётся гипотезой, подлежащей проверке.
Рассмотренный случай трёх вариантов очевидным образом распространяется на произвольное число вариантов.
Формула (1) преобразуется к виду
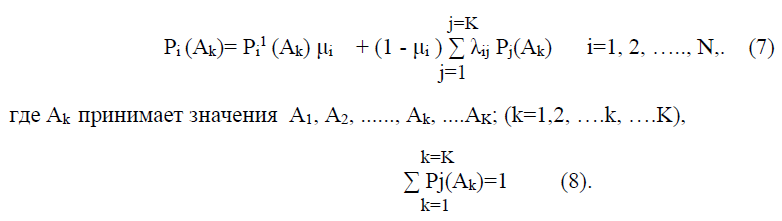
В рассмотренном эксперименте активные эксперты не обмениваются мнениями между собой, поэтому система сильно упростилась, фактически распавшись на отдельные группы уравнений (по три в каждой группе), но общий алгоритм остаётся невырожденным и все выводы справедливы и для общего случая.
Наиболее сложным шагом в описанной методике остаётся контент-анализ для оценки суждений экспертов, но эта операция не столь трудоёмка при ограниченном числе оцениваемых высказываний.
Разработанная методика может быть рекомендована как для анализа степени обучающего воздействия, или качества учебного материала, выставленного на сайте или на форуме.
Она же может применяться и для оценки раздаточного учебного материала при любых формах обучения.