В статье рассматриваются теоретические аспекты управления многоагентной системой, на основе вероятностных марковских моделей. Система представляет собой набор агентов, с возможностью взаимодействовать между собой, для достижения группы целей. Поведение системы является непредсказуемым с точки зрения целей. Поведение агентов определяется с помощью алгоритма, который включает идентификацию параметров вероятностной модели, используя максимизацию целевых функций, представляющих индивидуальные и групповые вероятности достижения (пометки) целей.
Для цитаты:Левонович, Н.И. (2025). Разработка вероятностной модели поведения многоагентной системы в трехмерном пространстве. Моделирование и анализ данных,15(2), 152–164. https://doi.org/10.17759/mda.2025150209
В последнее время существенно актуализировались проблемы, связанные с управлением группой подвижных объектов, которым необходимо согласовывать свое поведение для достижения целей. Постановка и решение задач в данной сфере может использоваться для управления группами наземных и воздушных роботов и других мобильных систем.
Данные системы могут применятся для поиска в тайге, поиска и слежения за движущимися объектами на обширных пространствах.
Описание поведения системы
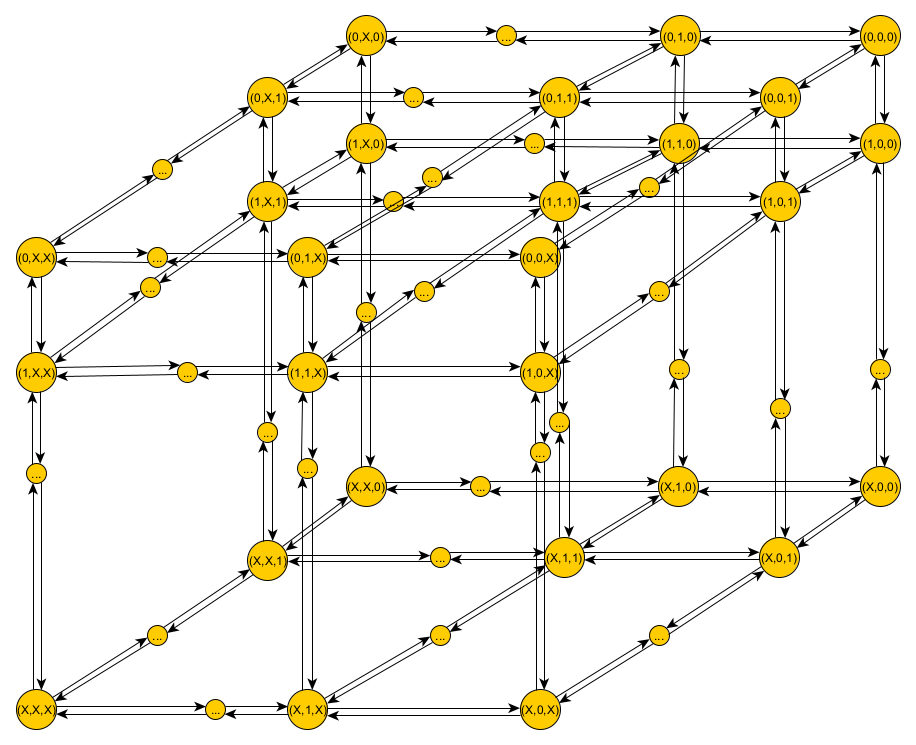
Агенты движутся в трехмерном игровом пространстве, которое содержит набор целей , согласно некоторым правилам, пытаясь поразить цели. С целью определения положения агентов и целей вводится агент-наблюдатель, относительно которого производится позиционирование, к нему привязана относительная система координат. Пространство ограничено зоной действия агента-наблюдателя и разделено на кубы. Позиция агента и цели определяется с точностью до куба , где индекс долготы , индекс широты , индекс высоты (рисунок 1). Вероятность того, что агент находится в ячейке в момент времени определяется функцией .
Рис. 1. Структура отношений между состояниями случайного марковского процесса, представляющая движение агентов по ячейкам игрового поля
Fig. 1. Structure of relationship between states of random Markov process representing agent movement through game field cells
В дискретные моменты времени, разделенные интервалами дискретизации , агент может воздействовать на цель, и вероятно это воздействие будет успешно или претерпит воздействие со стороны цели и вероятно пораженным целью с вероятностями определяемые позициями агентов и целей. В параметрах системы задаются: пороговые вероятности для индивидуального и коллективного воздействия на цель, максимальная разрешенная вероятность успешного воздействия цели на агента , максимальная скорость агента . Число агентов, одновременно терпящих воздействие одной цели (не регулируется, один агента).
В дискретный каждый момент времени все функционирующие агенты знают какой ячейке они находятся. В зависимости от игровой ситуации агенты могут получать или не получать информацию о положении других агентах.
Изменение положения агентов и целей на игровом поле, а также вероятностей взаимных поражений происходит за фиксированный интервал времени называется тактом игры.
Концом игры является ситуация, когда на поле не осталось целей (все цели помечены), либо когда на поле не осталось агентов.
В рассматриваемой модели цели могу располагаться только на одном индексе высоты (наземные цели).
Предположим, что движение каждого агента по ячейкам анализируемого пространства описывается случайным марковским процессом с непрерывным временем и дискретными состояниями. Нахождение в состоянии такого марковского процесса означает пребывание в выделенной ячейке рассматриваемого пространства, которая имеет те же индексы. В таком случае переходы, подчиняющиеся пуассоновскому потоку случайных событий, возможны только между смежными ячейками, которые имеют общую грань.
Число переходов между смежными состояниями , происходящий за любой интервал времени , начиная со времени подчиняются закону Пуассона:
где – вероятность переходов за этот интервал, среднее количество переходов, совершаемых за интервал с момента времени . В дальнейшем рассматриваются только стационарные потоки и
Гипотеза о пуассоновском распределении переходов является стандартной для рассматриваемой области, так как это распределение часто встречается на практике, так как следует из предельных теорем для потоков событий.
Поведение каждого агента в части перемещения определяется автономно. Динамика вероятностей пребывания -того агента в состояниях марковского процесса определяется системой дифференциальных уравнений Колмогорова в матричной форме:
где – вероятности пребывания m-того агента в n-том состоянии процесса, – вектор интенсивностей перехода между смежными состояниями для m-того агента. – матрица -того порядка интенсивностей перехода между смежными состояниями m-того агента. Начальные условия , где – индекс ячейки в который m-тый агент находился в .
Введём следующее обозначения для элементов вектора (рисунок 2)
Интенсивность переходов m-того агента в состоянии в сторону увеличения первой координаты ;
Интенсивность переходов m-того агента в состоянии в сторону уменьшения первой координаты ;
Интенсивность переходов m-того агента в состоянии в сторону увеличения второй координаты ;
Интенсивность переходов m-того агента в состоянии в сторону уменьшения второй координаты ;
Интенсивность переходов m-того агента в состоянии в сторону увеличения третий координаты ;
Интенсивность переходов m-того агента в состоянии в сторону уменьшения третий координаты ;
Рис. 2. Обозначение интенсивности переходов m-того агента в данном состоянии
Fig. 2. Designation of the intensity of transitions of the m-th agent in a given state
Расчет вероятностей для всех агентов происходит синхронно в дискретные моменты времени с шагом . Некоторые агенты могут оставаться в тех же ячейках.
Обозначим текущий момент времени как , обозначим введем следующие обозначения для событий:
– n-тая цель успешно помечена в результате воздействия;
– m-тый агент помечена в результате n-той цели;
– воздействие m-тым агентом на n-тую цель;
– m-тый агент находится в ячейке
– в момент времени m-тый агент находится в ячейке , которая смежна с ячейкой, в которой агент находился в момент времени .
– переход m-того агента из ячейки, в которой он был в момент времени в одну из смежных ячеек.
– n-тая цель находится в ячейке
Вероятность успешной пометки n-той цели в результате воздействия m-тым агентом вычисляется согласно формуле полной вероятности:
Вероятность успешной пометки n-той цели, находящейся в ячейке m-тым агентом в результате воздействия из ячейки в момент времени задается относительной «картой осуществимости» :
Вероятности определяются из решения системы дифференциальных уравнений Колмогорова. Цель движется по функции.
Вероятность успешной пометки m-того агента, находящегося ячейке , n-той целью находящейся в ячейке в результате воздействия в момент времени задается относительной «картой уязвимости» :
Карты осуществимости и уязвимости пересчитываются каждый такт игры, чтобы отслеживать перемещения целей и агентов по игровому полю. Для решения множества прикладных проблем, целесообразно определить распределение вероятностей, которые задают две карты как логистические функций:
где расстояние между ячейками и ; параметры идентифицируется по методу максимального правдоподобия согласно эмпирическим данным, для того чтобы обеспечить наивысшую вероятность попадания наблюдаемой цели и агентов в контрольную серию экспериментов.
Найдем закон распределения для , которое необходимо для перехода между состояниями процесса. Вероятность, что переход не случится - . Это значение эквивалентно вероятности события : . Следовательно, , где – функция распределения случайной величины Это распределение имеет плотность и математическое ожидание
Вероятность успешной пометки n-той цели в ходе групповой атаки оценивается согласно формуле сумме вероятностей, в случае воздействия на него всеми агентами одновременно:
События и полагаются независимыми если .
Построение пар атак
Введем понятие воздействия (потенциального воздействия), как пары агента и цели , – множество воздействий, функционал назовем значением воздействия.
Матрица значений воздействия , образуется из значений воздействий, которые стоят на пересечении строки (относящейся к агенту) и столбца (относящейся к цели).
Построим граф ; . Для ребер существует функционал разметки , , где .
Для полученного графа с помощью венгерского алгоритма [Венгерский алгоритм решения; Задача о назначениях] решается задача о назначениях получается распределение воздействий.
Определения:
Паросочетанием M называется набор попарно несмежных рёбер графа (иными словами, любой вершине графа должно быть инцидентно не более одного ребра из множества M). Мощностью паросочетания назовём количество рёбер в нём. Наибольшим (или максимальным) паросочетанием назовём паросочетание, мощность которого максимальна среди всех возможных паросочетаний в данном графе. Все те вершины, у которых есть смежное ребро из паросочетания (т.е. которые имеют степень ровно один в подграфе, образованном M), назовём насыщенными этим паросочетанием.
Полное паросочетание – паросочетание, в которое входят все вершины.
Цепью длины k назовём некоторый простой путь (т.е. не содержащий повторяющихся вершин или рёбер), содержащий k рёбер.
Чередующейся цепью (в двудольном графе, относительно некоторого паросочетания) назовём цепь, в которой рёбра поочередно принадлежат/не принадлежат паросочетанию.
Увеличивающей цепью (в двудольном графе, относительно некоторого паросочетания) назовём чередующуюся цепь, у которой начальная и конечная вершины не принадлежат паросочетанию.
Алгоритм решает следующую задачу пусть дан взвешенный полный двудольный граф c целыми весами ребер , нужно найти в нем полное паросочетание минимального веса. Вес паросочетания определяется как сумма весов его ребер.
Функцию назовём потенциалом, если для любых вершин и выполняется условие:
где — стоимость ребра между и . Значением потенциала называется сумма потенциалов всех вершин.
Заметим, что стоимость любого совершенного паросочетания не может быть меньше значения любого потенциала. Венгерский алгоритм решает задачу оптимально: он находит одновременно и совершенное паросочетание, и потенциал, у которых стоимость паросочетания совпадает со значением потенциала. Это доказывает, что оба решения являются оптимальными.
Алгоритм работает с жёсткими рёбрами — теми, для которых выполняется равенство:
Если обозначить подграф из таких рёбер как , то стоимость любого совершенного паросочетания в (при его существовании) в точности равна значению потенциала .
Алгоритм работает с матрицей весов графа.
Вспомогательный алгоритм (алгоритм Куна)
Алгоритм
1.Берем пустое паросочетание;
2.Пока в графе удается найти увеличивающую цепь, выполняется чередование паросочетание вдоль этой цепи, и повторять процесс поиска увеличивающей цепи.
a.Как только не удалось найти увеличивающую цепь, процесс поиска останавливается, текущее паросочетание максимально.
Алгоритм Куна [Алгоритм Куна нахождения] ищет любую увеличивающую цепь, с помощью обходу в глубину или в ширину. Алгоритм Куна просматривает все вершины графа по очереди, запуская из каждой обход, пытающийся найти увеличивающую цепь, начинающуюся в этой вершине.
Алгоритм последовательно обрабатывает все вершины первой доли :
Если вершина уже насыщена текущим паросочетанием (т. е. уже соединена с какой-то вершиной второй доли), то она пропускается.
В противном случае алгоритм пытается насытить путём поиска увеличивающей цепи, начинающейся в этой вершине.
Для поиска используется обход в глубину (DFS) (реже — в ширину, BFS):
1.Начинаем из ненасыщенной вершины первой доли.
2.Перебираем все рёбра, исходящие из . Пусть текущее ребро ведёт в вершину второй доли.
oЕсли ненасыщенна, то цепь найдена — это просто ребро .
Действие: добавляем в паросочетание и завершаем поиск.
oЕсли уже насыщена ребром , то продолжаем поиск из .
Таким образом, мы пытаемся построить чередующуюся цепь вида .
3.Обход продолжается, пока либо не будет найдена увеличивающая цепь, либо не станет ясно, что такой цепи не существует.
Результат обхода
Если цепь найдена, то вершина становится насыщенной, и мощность паросочетания увеличивается на 1.
Если цепь не найдена, то вершина остаётся ненасыщенной (и в текущем паросочетании её уже нельзя покрыть).
Завершение работы алгоритма
После обработки всех вершин первой доли текущее паросочетание становится максимальным, и алгоритм завершает работу.
Алгоритм для равных долей
Алгоритм хранит в памяти потенциал (в виде массивов и ) и ориентацию (направление) каждого жёсткого ребра. Эта ориентация обладает ключевым свойством: рёбра, направленные от к , формируют паросочетание, обозначаемое . Ориентированный граф, состоящий из жёстких рёбер с заданной ориентацией, обозначается как .
Шаг 1. В начале алгоритма потенциал полагается равным нулю и паросочетание полагается пустым.
Цикл. На каждом шаге алгоритм пытается увеличить мощность текущего паросочетания на единицу, не изменяя потенциалы. Это делается в графе жёстких рёбер с использованием модифицированного алгоритма Куна для поиска максимального паросочетания в двудольных графах.
Если на текущем шаге цикла не удалось увеличить паросочетание, производится корректировка потенциалов, чтобы создать новые возможности для увеличения паросочетания:
1.Определим множества и и величину Δ
— посещённые вершины первой доли при обходе (поиске увеличивающей цепи).
— посещённые вершины второй доли.
Δ вычисляется как:
Таким образом Δ > 0, иначе существовало бы "жёсткое" ребро , ведущее к противоречию с определением и .
2.Корректировка потенциалов
Для всех :
Для всех :
Корректность потенциала сохраняется: для рёбер , где и : (по выбору Δ). Для остальных комбинаций неравенство либо не изменилось, либо усилилось.
Жёсткие рёбра паросочетания остаются: ребра паросочетания могли измениться только если и , но такие рёбра не входят в (так как не была посещена).
3.Рост достижимого множества
После пересчёта все ранее достижимые вершины остаются достижимыми. Появится хотя бы одно новое жёсткое ребро (где , ), делающее вершину достижимой. Таким образом, строго увеличивается.
4.Конечность алгоритма
Поскольку размер не может превысить , число пересчётов потенциалов ограничено ( ). После каждого пересчёта либо находится увеличивающая цепь, либо прогресс гарантирован.
Завершение алгоритма. Алгоритм продолжает итеративно выполнять следующие шаги:
1.Поиск увеличивающей цепи для текущего паросочетания .
2.Если цепь найдена — увеличение на единицу.
3.Если цепь не найдена — пересчёт потенциалов, расширяющий множество достижимых вершин.
Рано или поздно будет достигнут потенциал, при котором существует совершенное паросочетание (если исходный граф его допускает). Это паросочетание и будет решением задачи.
Если говорить об асимптотике алгоритма, то она составляет , поскольку всего должно произойти увеличений паросочетания, перед каждым из которых происходит не более пересчётов потенциала, каждый из которых выполняется за время .
3.2. Модификация алгоритма для неравных долей с асимптотикой
Ключевая идея – вместо одновременного рассмотрения всей матрицы, алгоритм последовательно добавляет строки, на каждом шаге поддерживая максимальное паросочетание для уже обработанной части. Это позволяет:
1.Локализовать пересчёты потенциалов только для новых данных.
2.Сделать алгоритм пригодным для неравных долей.
3.Снизить асимптотику до (или для прямоугольных матриц).
Оптимизации для асимптотики :
Поддержка массива , для каждого столбца хранится минимальное значение по всем посещённым строкам . Обновляется за при добавлении новой строки в .
Быстрый поиск – вычисляется за .
Итеративный обход Куна – после пересчёта потенциала обход продолжается с новыми жёсткими рёбрами, не перезапускаясь с нуля.
В результате выполнения венгерского алгоритма имеются пары оптимальных атак, с вероятностью поражения.
Алгоритм поведения системного агента
Поведение -того агента определяется следующим алгоритмом.
Шаг 1. Указать начальные условия, которые определяются:
Распределение агентов по ячейкам игрового поля;
«Карта осуществимости» представлена функцией
«Карта уязвимости» представлена функцией
Приблизительная оценка интервала семплирования.
Шаг 2. Для текущего распределения агентов и целей на текущий момент :
Для каждой цели рассчитать вероятность пометки агента. Для каждого цели выбрать первого по порядку агента, вероятность пометки, которого превышает порог, удалить агента пропорционально вероятности пометки.
Выполнить вероятностную атаку согласно построенным парам атак с помощью алгоритма, представленного в предыдущем пункте статьи.
Шаг 3. Если как минимум одно из условий для завершения игры выполнено на момент :
Получение информации о пометке всех агентов.
Получение информации о пометке всех целей.
Тогда перейти к шагу 6, иначе перейти к шагу 4.
Шаг 4. Выполним идентификацию свободных параметров марковского процесса, полагая , где ограничение скорости задает ограничения значения компонент вектора , со средними значениями , и времени перехода. Если агентам доступна информация друг о друге, максимизировать целевую функцию игры, которая вычисляется по формуле (obj), и представляет собой сумму вероятностей успешного воздействия на цели (простую сумму, которая сама не является вероятностью) в момент времени , принимая в расчет всех агентов.
В противном случае, задача оптимизации решается отдельно для каждого агента автономно, с индивидуальными целевыми функциями , в момент времени (при условии равновероятного выбора цели).
Перейти к шагу 5.
Шаг 5. Для каждого агента выбрать ячейку игрового поля, смежную с ячейкой, в которой он находится в момент времени используя «метод рулетки», с вероятностями выбора пропорциональми предсказанным байесовским оценкам и вероятностям , рассчитанным для момента времени как результат предыдущего шага алгоритма, и переместить агента туда со скоростью, случайные компоненты, которой вычисляются на основе интенсивностей идентифицированных на шаге 4, если выполнены следующие ограничения:
Если не выполнено условие 1, установить скорость перемещения равной , если не выполнено второе условие, не перемещаться. На текущий такт игры, интервал определяется как максимальное время необходимое для перемещения между центрами соседних ячеек:
, где
Переходы агентов между состояниями синхронизированы по интервалу который одинаков для всех объектов.
Перейти к следующему по порядку дискретному моменту времени , и далее полагать его текущим моментом времени. Перейти к шагу 2.
Шаг 6. Завершить игру.
Задача идентификации решается по методу, предложенному в статье [Kuravsky, 2015].
Выводы
Разработана вероятностная модель поведения прикладной многоагентной системы, которая представляет собой игровое взаимодействие между агентами и целями. Поведение агентов не детерминировано и таким образом непредсказуемо с точки зрения целей. Модель подразумевает применимость в условиях скоординированной или автономной работы агентов, на основе доступности агентам информации о положении друг друга.
Поведение агентов определяется вспомогательным алгоритмом, который включает:
Идентификация параметров вероятностной модели, используя максимизацию целевой функцию, которая учитывает вероятности поражения целей.
Последовательное движение агентов по игровому полю со скоростями, случайные компоненты которых вычисляются, используя идентифицированные параметры модели.
Атаку врага в случае превышения вероятности группового или индивидуального поражения цели.
Разработанная модель и алгоритм обеспечивают управление поведением соответствующих прикладных многоагентных систем.
Литература
Венгерский алгоритм решения задачи о назначениях [Электронный ресурс] // Викиконспекты ИТМО – URL: https://neerc.ifmo.ru/wiki/index.php?title=%D0%92%D0%B5%D0%BD%D0%B3%D0%B5%D1%80%D1%81%D0%BA%D0%B8%D0%B9_%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC_%D1%80%D0%B5%D1%88%D0%B5%D0%BD%D0%B8%D1%8F_%D0%B7%D0%B0%D0%B4%D0%B0%D1%87%D0%B8_%D0%BE_%D0%BD%D0%B0%D0%B7%D0%BD%D0%B0%D1%87%D0%B5%D0%BD%D0%B8%D1%8F%D1%85 (дата обращения 05.05.2025)
Задача о назначениях. Венгерский алгоритм (алгоритм Куна) [Электронный ресурс] // MAXimal :: algo – URL: http://e-maxx.ru/algo/assignment_hungary (дата обращения 05.05.2025)
Алгоритм Куна нахождения наибольшего паросочетания [Электронный ресурс] // MAXimal :: algo – URL: http://e-maxx.ru/algo/kuhn_matching (дата обращения 05.05.2025)
Kuravsky L. S., Marmalyuk P. A., Yuryev G. A., Dumin P. N., A numerical technique for the identification of discrete-state continuous-time Markov models, Appl. Math. Sci. 9:379–391, 2015. http://dx.doi.org/10.12988/ams.2015.410882.
Информация об авторах
Никита Ильич Левонович, лаборант-исследователь, лаборатория количественной психологии центра ИТ, факультета "Информационные технологии", , Московский государственный психолого-педагогический университет (ФГБОУ ВО МГППУ), аспирант, факультет "Информационные технологии"; руководитель, научно-производственного центра Левоник, Дмитров, Российская Федерация, ORCID: https://orcid.org/0000-0002-8580-0490, e-mail: levonikitatech@yandex.ru
Метрики
Просмотров web
За все время: 290
В прошлом месяце: 10
В текущем месяце: 0
Скачиваний PDF
За все время: 78
В прошлом месяце: 17
В текущем месяце: 0
Всего
За все время: 368
В прошлом месяце: 27
В текущем месяце: 0